 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially-Aware Evaluation Framework for Aerial LiDAR Point Cloud Semantic Segmentation: Distance-Based Metrics on Challenging Regions
Mar 23, 2026Semantic segmentation metrics for 3D point clouds, such as mean Intersection over Union (mIoU) and Overall Accuracy (OA), present two key limitations in the context of aerial LiDAR data. First, they treat all misclassifications equally regardless of their spatial context, overlooking cases where the geometric severity of errors directly impacts the quality of derived geospatial products such as Digital Terrain Models. Second, they are often dominated by the large proportion of easily classified points, which can mask meaningful differences between models and under-represent performance in challenging regions. To address these limitations, we propose a novel evaluation framework for comparing semantic segmentation models through two complementary approaches. First, we introduce distance-based metrics that account for the spatial deviation between each misclassified point and the nearest ground-truth point of the predicted class, capturing the geometric severity of errors. Second, we propose a focused evaluation on a common subset of hard points, defined as the points misclassified by at least one of the evaluated models, thereby reducing the bias introduced by easily classified points and better revealing differences in model performance in challenging regions. We validate our framework by comparing three state-of-the-art deep learning models on three aerial LiDAR datasets. Results demonstrate that the proposed metrics provide complementary information to traditional measures, revealing spatial error patterns that are critical for Earth Observation applications but invisible to conventional evaluation approaches. The proposed framework enables more informed model selection for scenarios where spatial consistency is critical.
Benchmarking Deep Learning Models for Aerial LiDAR Point Cloud Semantic Segmentation under Real Acquisition Conditions: A Case Study in Navarre
Mar 23, 2026Recent advances in deep learning have significantly improved 3D semantic segmentation, but most models focus on indoor or terrestrial datasets. Their behavior under real aerial acquisition conditions remains insufficiently explored, and although a few studies have addressed similar scenarios, they differ in dataset design, acquisition conditions, and model selection. To address this gap, we conduct an experimental benchmark evaluating several state-of-the-art architectures on a large-scale aerial LiDAR dataset acquired under operational flight conditions in Navarre, Spain, covering heterogeneous urban, rural, and industrial landscapes. This study compares four representative deep learning models, including KPConv, RandLA-Net, Superpoint Transformer, and Point Transformer V3, across five semantic classes commonly found in airborne surveys, such as ground, vegetation, buildings, and vehicles, highlighting the inherent challenges of class imbalance and geometric variability in aerial data. Results show that all tested models achieve high overall accuracy exceeding 93%, with KPConv attaining the highest mean IoU (78.51%) through consistent performance across classes, particularly on challenging and underrepresented categories. Point Transformer V3 demonstrates superior performance on the underrepresented vehicle class (75.11% IoU), while Superpoint Transformer and RandLA-Net trade off segmentation robustness for computational efficiency.
Towards interval uncertainty propagation control in bivariate aggregation processes and the introduction of width-limited interval-valued overlap functions
Jun 08, 2021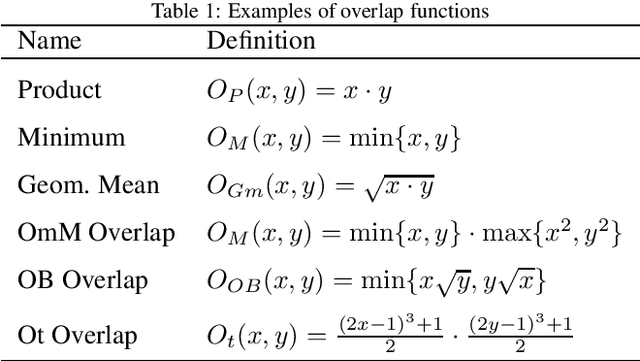

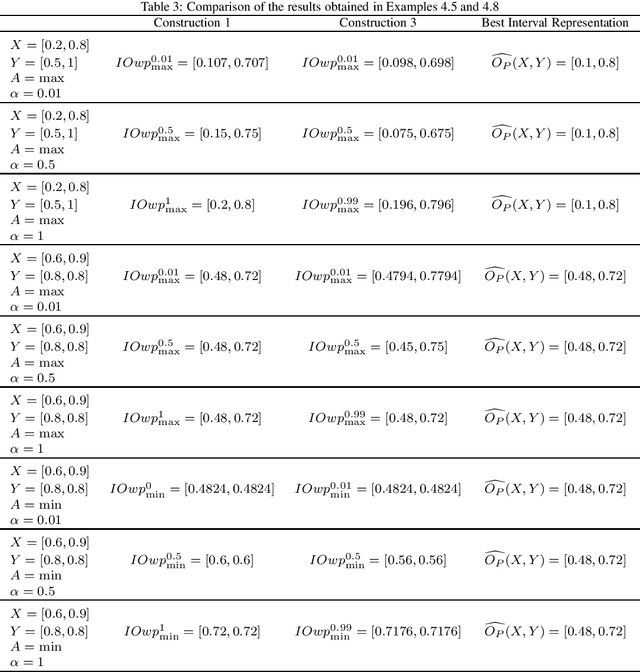
Overlap functions are a class of aggregation functions that measure the overlapping degree between two values. Interval-valued overlap functions were defined as an extension to express the overlapping of interval-valued data, and they have been usually applied when there is uncertainty regarding the assignment of membership degrees. The choice of a total order for intervals can be significant, which motivated the recent developments on interval-valued aggregation functions and interval-valued overlap functions that are increasing to a given admissible order, that is, a total order that refines the usual partial order for intervals. Also, width preservation has been considered on these recent works, in an intent to avoid the uncertainty increase and guarantee the information quality, but no deeper study was made regarding the relation between the widths of the input intervals and the output interval, when applying interval-valued functions, or how one can control such uncertainty propagation based on this relation. Thus, in this paper we: (i) introduce and develop the concepts of width-limited interval-valued functions and width limiting functions, presenting a theoretical approach to analyze the relation between the widths of the input and output intervals of bivariate interval-valued functions, with special attention to interval-valued aggregation functions; (ii) introduce the concept of $(a,b)$-ultramodular aggregation functions, a less restrictive extension of one-dimension convexity for bivariate aggregation functions, which have an important predictable behaviour with respect to the width when extended to the interval-valued context; (iii) define width-limited interval-valued overlap functions, taking into account a function that controls the width of the output interval; (iv) present and compare three construction methods for these width-limited interval-valued overlap functions.