 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Realism of LLM-powered Social Agents: A Case Study of Reactions to Spanish Online News
May 27, 2026LLM-powered social agents are increasingly used to simulate online social behavior, yet their realism remains difficult to validate. Existing work has largely relied on general-purpose benchmarks, while less attention has been paid to short, reactive discourse such as audience replies to online news. In this paper, we evaluate whether LLM-generated reactions to Spanish online news reproduce measurable properties of real audience discourse. Using the Hatemedia dataset, we pair 5,631 news items with 58,555 real audience reactions, and generate a matched synthetic dataset using five LLMs under a shared experimental setting. We compare real and synthetic reactions across three dimensions: hate speech, sentiment, and semantic alignment, considering both off-the-shelf and fine-tuned generation. Results show that off-the-shelf models are poor proxies for real audience reactions: they strongly underproduce hate speech, introduce model-specific sentiment biases, and remain distributionally distant from human replies. Fine-tuning improves fidelity unevenly. Qwen3 provides the most balanced approximation, while Mistral7B achieves the strongest sentiment and semantic alignment but overshoots hate prevalence. Plausible synthetic replies do not necessarily reproduce the distributional properties of public discourse.
Large Scale Analysis of Open MOOC Reviews to Support Learners' Course Selection
Jan 11, 2022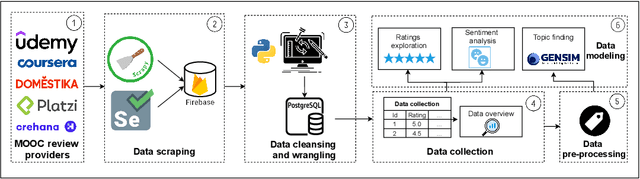
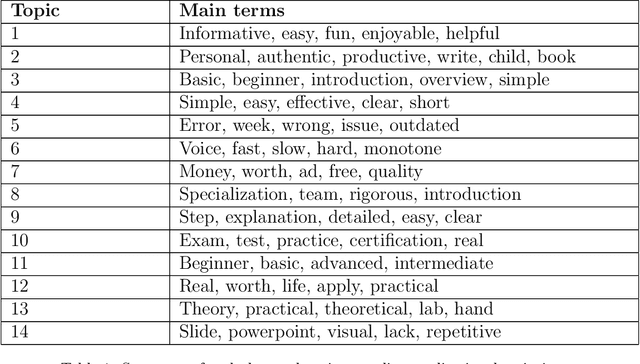
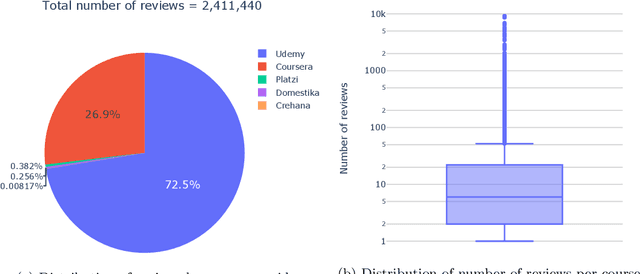
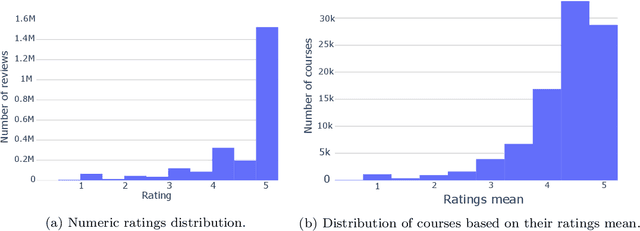
The recent pandemic has changed the way we see education. It is not surprising that children and college students are not the only ones using online education. Millions of adults have signed up for online classes and courses during last years, and MOOC providers, such as Coursera or edX, are reporting millions of new users signing up in their platforms. However, students do face some challenges when choosing courses. Though online review systems are standard among many verticals, no standardized or fully decentralized review systems exist in the MOOC ecosystem. In this vein, we believe that there is an opportunity to leverage available open MOOC reviews in order to build simpler and more transparent reviewing systems, allowing users to really identify the best courses out there. Specifically, in our research we analyze 2.4 million reviews (which is the largest MOOC reviews dataset used until now) from five different platforms in order to determine the following: (1) if the numeric ratings provide discriminant information to learners, (2) if NLP-driven sentiment analysis on textual reviews could provide valuable information to learners, (3) if we can leverage NLP-driven topic finding techniques to infer themes that could be important for learners, and (4) if we can use these models to effectively characterize MOOCs based on the open reviews. Results show that numeric ratings are clearly biased (63\% of them are 5-star ratings), and the topic modeling reveals some interesting topics related with course advertisements, the real applicability, or the difficulty of the different courses. We expect our study to shed some light on the area and promote a more transparent approach in online education reviews, which are becoming more and more popular as we enter the post-pandemic era.