 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCienaLLM: Generative Climate-Impact Extraction from News Articles with Autoregressive LLMs
Dec 22, 2025Understanding and monitoring the socio-economic impacts of climate hazards requires extracting structured information from heterogeneous news articles on a large scale. To that end, we have developed CienaLLM, a modular framework based on schema-guided Generative Information Extraction. CienaLLM uses open-weight Large Language Models for zero-shot information extraction from news articles, and supports configurable prompts and output schemas, multi-step pipelines, and cloud or on-premise inference. To systematically assess how the choice of LLM family, size, precision regime, and prompting strategy affect performance, we run a large factorial study in models, precisions, and prompt engineering techniques. An additional response parsing step nearly eliminates format errors while preserving accuracy; larger models deliver the strongest and most stable performance, while quantization offers substantial efficiency gains with modest accuracy trade-offs; and prompt strategies show heterogeneous, model-specific effects. CienaLLM matches or outperforms the supervised baseline in accuracy for extracting drought impacts from Spanish news, although at a higher inference cost. While evaluated in droughts, the schema-driven and model-agnostic design is suitable for adapting to related information extraction tasks (e.g., other hazards, sectors, or languages) by editing prompts and schemas rather than retraining. We release code, configurations, and schemas to support reproducible use.
Linguistic Interpretability of Transformer-based Language Models: a systematic review
Apr 09, 2025Language models based on the Transformer architecture achieve excellent results in many language-related tasks, such as text classification or sentiment analysis. However, despite the architecture of these models being well-defined, little is known about how their internal computations help them achieve their results. This renders these models, as of today, a type of 'black box' systems. There is, however, a line of research -- 'interpretability' -- aiming to learn how information is encoded inside these models. More specifically, there is work dedicated to studying whether Transformer-based models possess knowledge of linguistic phenomena similar to human speakers -- an area we call 'linguistic interpretability' of these models. In this survey we present a comprehensive analysis of 160 research works, spread across multiple languages and models -- including multilingual ones -- that attempt to discover linguistic information from the perspective of several traditional Linguistics disciplines: Syntax, Morphology, Lexico-Semantics and Discourse. Our survey fills a gap in the existing interpretability literature, which either not focus on linguistic knowledge in these models or present some limitations -- e.g. only studying English-based models. Our survey also focuses on Pre-trained Language Models not further specialized for a downstream task, with an emphasis on works that use interpretability techniques that explore models' internal representations.
Orchestrating NLP Services for the Legal Domain
Mar 28, 2020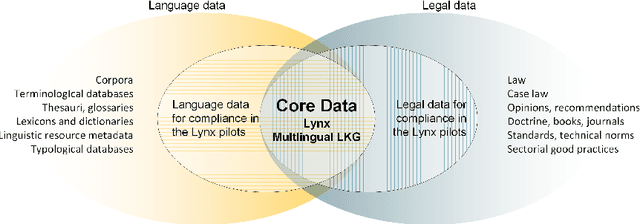
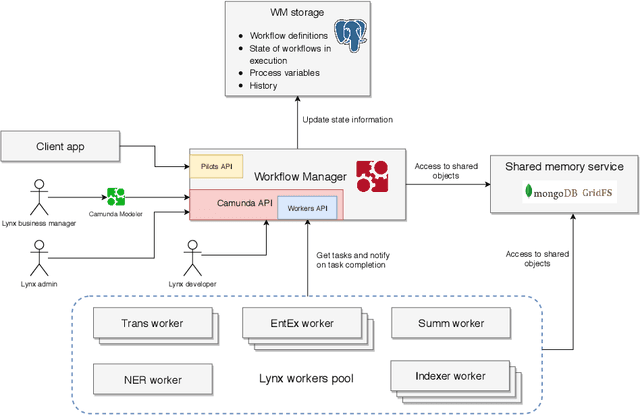
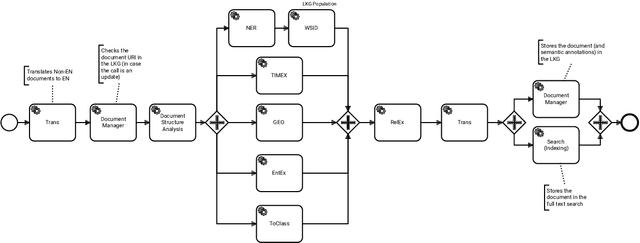
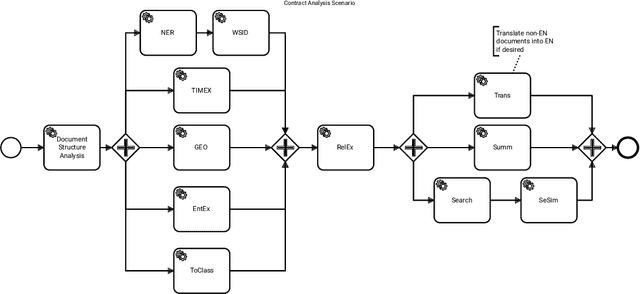
Legal technology is currently receiving a lot of attention from various angles. In this contribution we describe the main technical components of a system that is currently under development in the European innovation project Lynx, which includes partners from industry and research. The key contribution of this paper is a workflow manager that enables the flexible orchestration of workflows based on a portfolio of Natural Language Processing and Content Curation services as well as a Multilingual Legal Knowledge Graph that contains semantic information and meaningful references to legal documents. We also describe different use cases with which we experiment and develop prototypical solutions.
Semantic Relatedness for Keyword Disambiguation: Exploiting Different Embeddings
Feb 25, 2020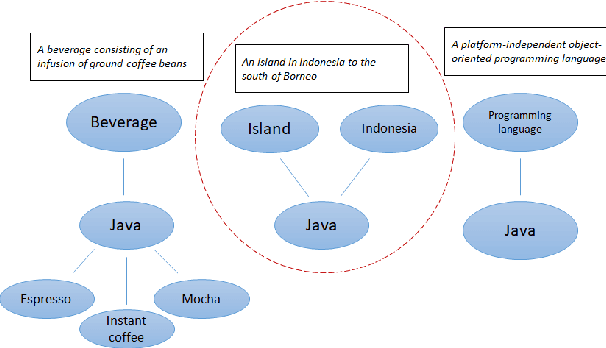
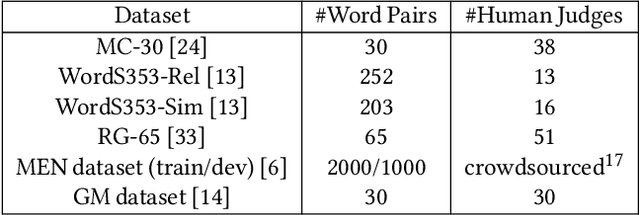
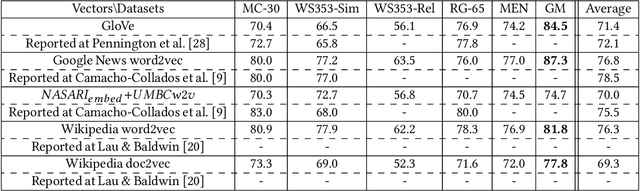

Understanding the meaning of words is crucial for many tasks that involve human-machine interaction. This has been tackled by research in Word Sense Disambiguation (WSD) in the Natural Language Processing (NLP) field. Recently, WSD and many other NLP tasks have taken advantage of embeddings-based representation of words, sentences, and documents. However, when it comes to WSD, most embeddings models suffer from ambiguity as they do not capture the different possible meanings of the words. Even when they do, the list of possible meanings for a word (sense inventory) has to be known in advance at training time to be included in the embeddings space. Unfortunately, there are situations in which such a sense inventory is not known in advance (e.g., an ontology selected at run-time), or it evolves with time and its status diverges from the one at training time. This hampers the use of embeddings models for WSD. Furthermore, traditional WSD techniques do not perform well in situations in which the available linguistic information is very scarce, such as the case of keyword-based queries. In this paper, we propose an approach to keyword disambiguation which grounds on a semantic relatedness between words and senses provided by an external inventory (ontology) that is not known at training time. Building on previous works, we present a semantic relatedness measure that uses word embeddings, and explore different disambiguation algorithms to also exploit both word and sentence representations. Experimental results show that this approach achieves results comparable with the state of the art when applied for WSD, without training for a particular domain.