 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Artificial Intelligence Write Like Borges? An Evaluation Protocol for Spanish Microfiction
Jun 09, 2025Automated story writing has been a subject of study for over 60 years. Large language models can generate narratively consistent and linguistically coherent short fiction texts. Despite these advancements, rigorous assessment of such outputs for literary merit - especially concerning aesthetic qualities - has received scant attention. In this paper, we address the challenge of evaluating AI-generated microfictions and argue that this task requires consideration of literary criteria across various aspects of the text, such as thematic coherence, textual clarity, interpretive depth, and aesthetic quality. To facilitate this, we present GrAImes: an evaluation protocol grounded in literary theory, specifically drawing from a literary perspective, to offer an objective framework for assessing AI-generated microfiction. Furthermore, we report the results of our validation of the evaluation protocol, as answered by both literature experts and literary enthusiasts. This protocol will serve as a foundation for evaluating automatically generated microfictions and assessing their literary value.
GeSERA: General-domain Summary Evaluation by Relevance Analysis
Oct 07, 2021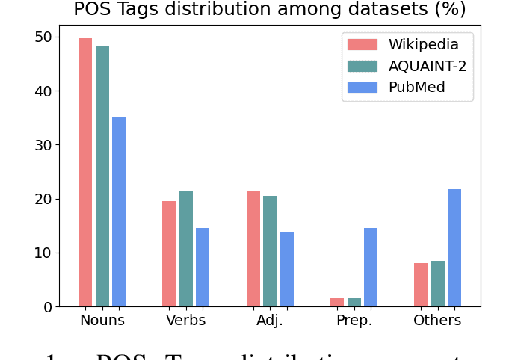
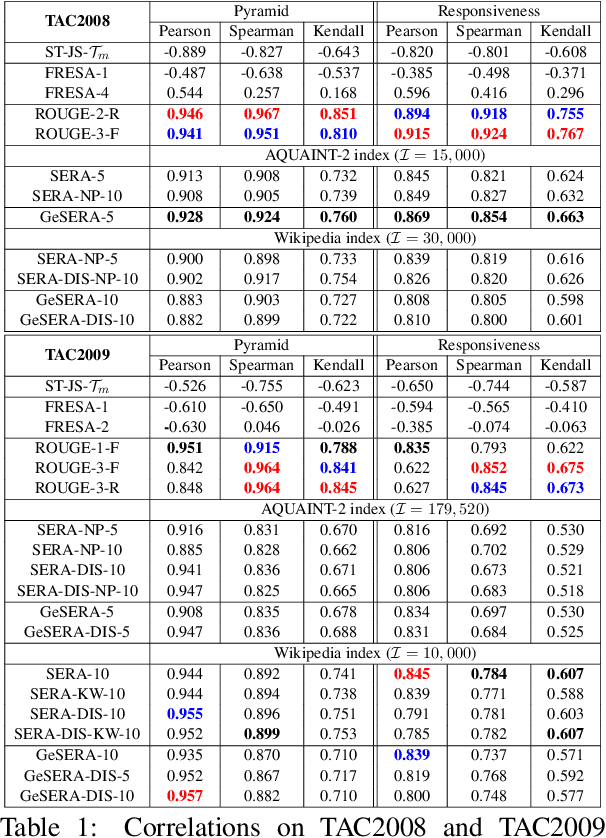
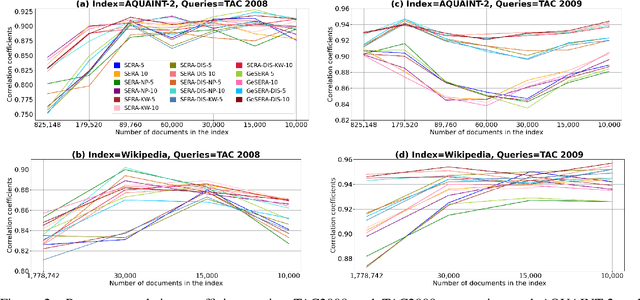
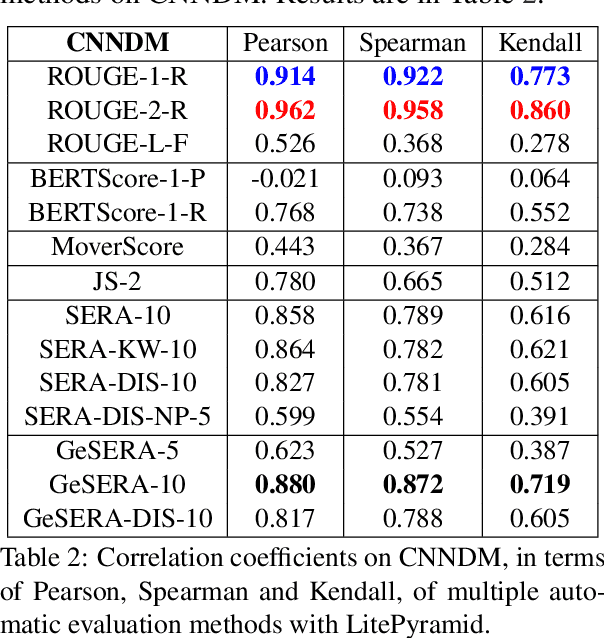
We present GeSERA, an open-source improved version of SERA for evaluating automatic extractive and abstractive summaries from the general domain. SERA is based on a search engine that compares candidate and reference summaries (called queries) against an information retrieval document base (called index). SERA was originally designed for the biomedical domain only, where it showed a better correlation with manual methods than the widely used lexical-based ROUGE method. In this paper, we take out SERA from the biomedical domain to the general one by adapting its content-based method to successfully evaluate summaries from the general domain. First, we improve the query reformulation strategy with POS Tags analysis of general-domain corpora. Second, we replace the biomedical index used in SERA with two article collections from AQUAINT-2 and Wikipedia. We conduct experiments with TAC2008, TAC2009, and CNNDM datasets. Results show that, in most cases, GeSERA achieves higher correlations with manual evaluation methods than SERA, while it reduces its gap with ROUGE for general-domain summary evaluation. GeSERA even surpasses ROUGE in two cases of TAC2009. Finally, we conduct extensive experiments and provide a comprehensive study of the impact of human annotators and the index size on summary evaluation with SERA and GeSERA.