 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen and Where to Reset Matters for Long-Term Test-Time Adaptation
Mar 04, 2026When continual test-time adaptation (TTA) persists over the long term, errors accumulate in the model and further cause it to predict only a few classes for all inputs, a phenomenon known as model collapse. Recent studies have explored reset strategies that completely erase these accumulated errors. However, their periodic resets lead to suboptimal adaptation, as they occur independently of the actual risk of collapse. Moreover, their full resets cause catastrophic loss of knowledge acquired over time, even though such knowledge could be beneficial in the future. To this end, we propose (1) an Adaptive and Selective Reset (ASR) scheme that dynamically determines when and where to reset, (2) an importance-aware regularizer to recover essential knowledge lost due to reset, and (3) an on-the-fly adaptation adjustment scheme to enhance adaptability under challenging domain shifts. Extensive experiments across long-term TTA benchmarks demonstrate the effectiveness of our approach, particularly under challenging conditions. Our code is available at https://github.com/YonseiML/asr.
Adversarial Training with Stochastic Weight Average
Sep 21, 2020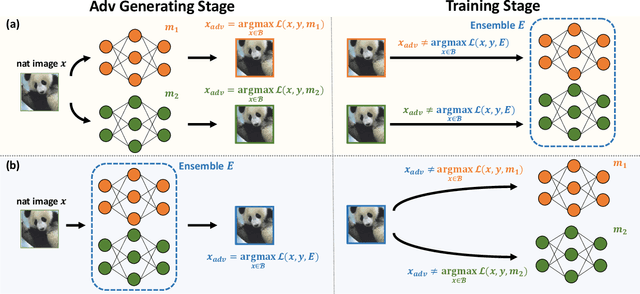
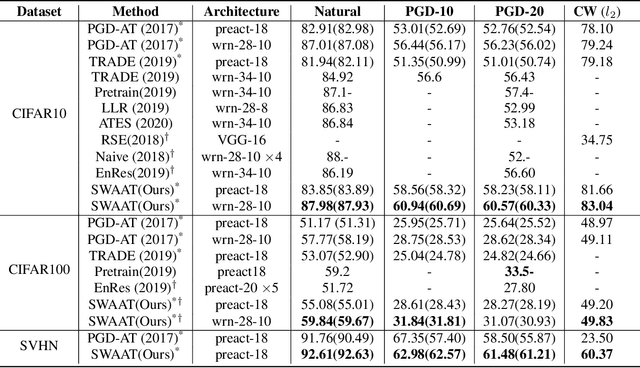
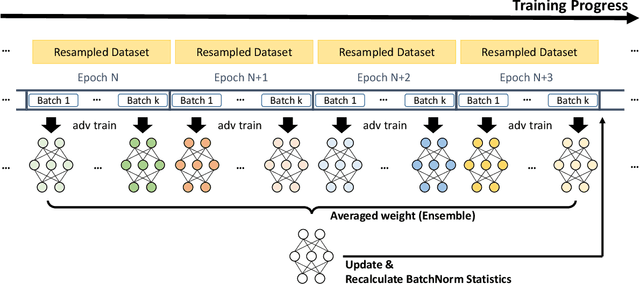

Adversarial training deep neural networks often experience serious overfitting problem. Recently, it is explained that the overfitting happens because the sample complexity of training data is insufficient to generalize robustness. In traditional machine learning, one way to relieve overfitting from the lack of data is to use ensemble methods. However, adversarial training multiple networks is extremely expensive. Moreover, we found that there is a dilemma on choosing target model to generate adversarial examples. Optimizing attack to the members of ensemble will be suboptimal attack to the ensemble and incurs covariate shift, while attack to ensemble will weaken the members and lose the benefit from ensembling. In this paper, we propose adversarial training with Stochastic weight average (SWA); while performing adversarial training, we aggregate the temporal weight states in the trajectory of training. By adopting SWA, the benefit of ensemble can be gained without tremendous computational increment and without facing the dilemma. Moreover, we further improved SWA to be adequate to adversarial training. The empirical results on CIFAR-10, CIFAR-100 and SVHN show that our method can improve the robustness of models.