 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBe Greedy in Multi-Armed Bandits
Jan 04, 2021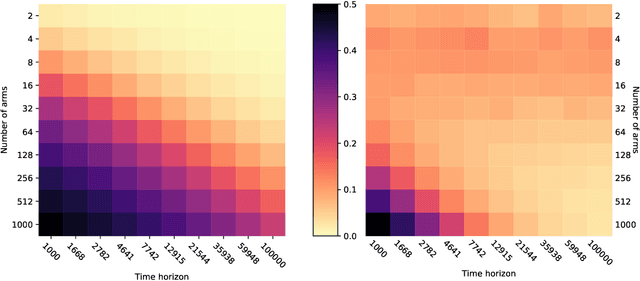
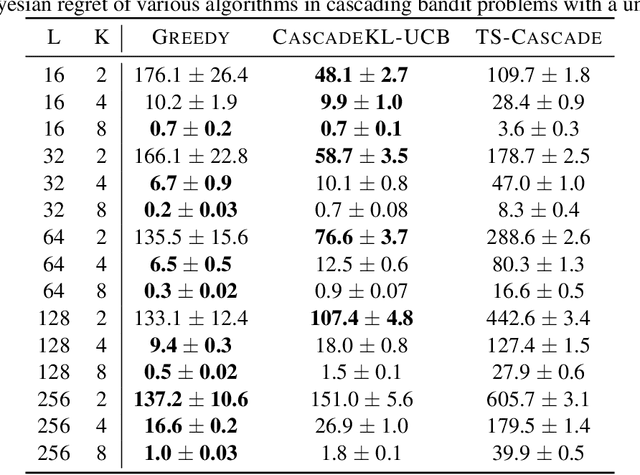
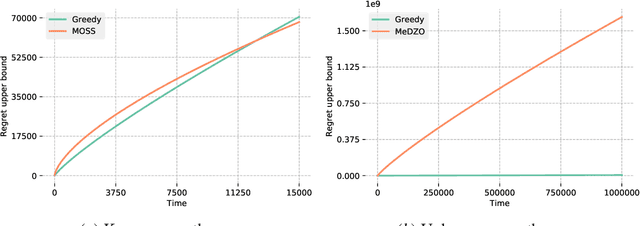
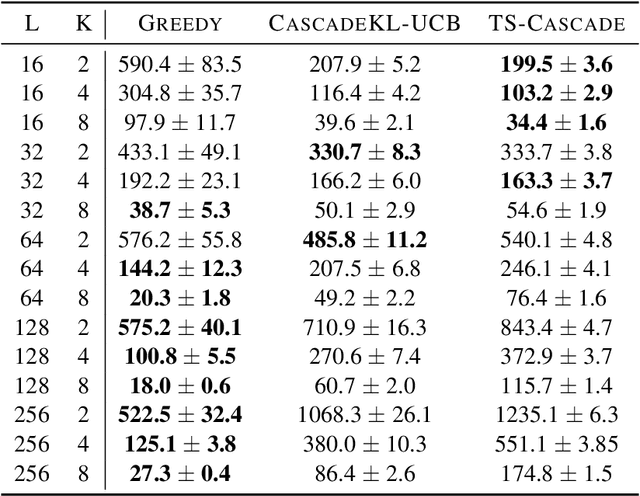
The Greedy algorithm is the simplest heuristic in sequential decision problem that carelessly takes the locally optimal choice at each round, disregarding any advantages of exploring and/or information gathering. Theoretically, it is known to sometimes have poor performances, for instance even a linear regret (with respect to the time horizon) in the standard multi-armed bandit problem. On the other hand, this heuristic performs reasonably well in practice and it even has sublinear, and even near-optimal, regret bounds in some very specific linear contextual and Bayesian bandit models. We build on a recent line of work and investigate bandit settings where the number of arms is relatively large and where simple greedy algorithms enjoy highly competitive performance, both in theory and in practice. We first provide a generic worst-case bound on the regret of the Greedy algorithm. When combined with some arms subsampling, we prove that it verifies near-optimal worst-case regret bounds in continuous, infinite and many-armed bandit problems. Moreover, for shorter time spans, the theoretical relative suboptimality of Greedy is even reduced. As a consequence, we subversively claim that for many interesting problems and associated horizons, the best compromise between theoretical guarantees, practical performances and computational burden is definitely to follow the greedy heuristic. We support our claim by many numerical experiments that show significant improvements compared to the state-of-the-art, even for moderately long time horizon.
Lifelong Learning in Multi-Armed Bandits
Dec 28, 2020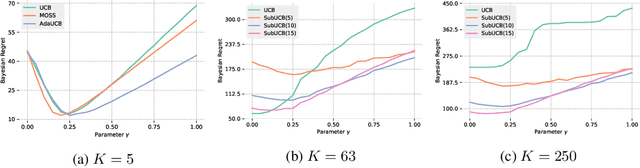
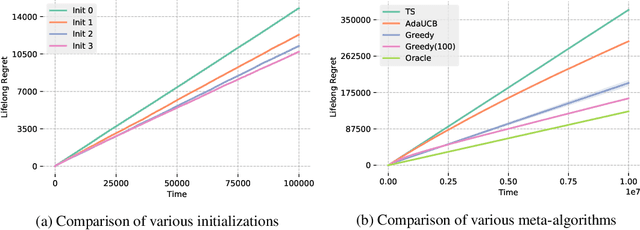
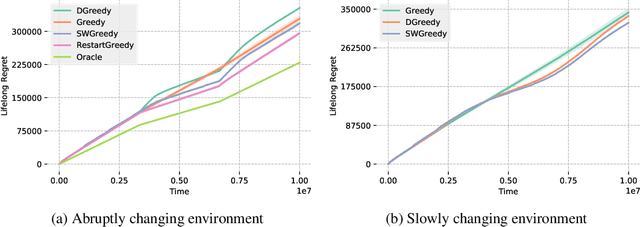
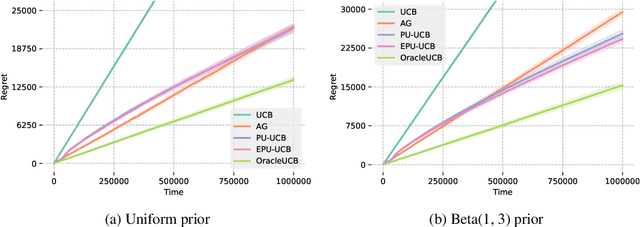
Continuously learning and leveraging the knowledge accumulated from prior tasks in order to improve future performance is a long standing machine learning problem. In this paper, we study the problem in the multi-armed bandit framework with the objective to minimize the total regret incurred over a series of tasks. While most bandit algorithms are designed to have a low worst-case regret, we examine here the average regret over bandit instances drawn from some prior distribution which may change over time. We specifically focus on confidence interval tuning of UCB algorithms. We propose a bandit over bandit approach with greedy algorithms and we perform extensive experimental evaluations in both stationary and non-stationary environments. We further apply our solution to the mortal bandit problem, showing empirical improvement over previous work.