 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe COTe score: A decomposable framework for evaluating Document Layout Analysis models
Mar 16, 2026Document Layout analysis (DLA), is the process by which a page is parsed into meaningful elements, often using machine learning models. Typically, the quality of a model is judged using general object detection metrics such as IoU, F1 or mAP. However, these metrics are designed for images that are 2D projections of 3D space, not for the natively 2D imagery of printed media. This discrepancy can result in misleading or uninformative interpretation of model performance by the metrics. To encourage more robust, comparable, and nuanced DLA, we introduce: The Structural Semantic Unit (SSU) a relational labelling approach that shifts the focus from the physical to the semantic structure of the content; and the Coverage, Overlap, Trespass, and Excess (COTe) score, a decomposable metric for measuring page parsing quality. We demonstrate the value of these methods through case studies and by evaluating 5 common DLA models on 3 DLA datasets. We show that the COTe score is more informative than traditional metrics and reveals distinct failure modes across models, such as breaching semantic boundaries or repeatedly parsing the same region. In addition, the COTe score reduces the interpretation-performance gap by up to 76% relative to the F1. Notably, we find that the COTe's granularity robustness largely holds even without explicit SSU labelling, lowering the barriers to entry for using the system. Finally, we release an SSU labelled dataset and a Python library for applying COTe in DLA projects.
Reading the unreadable: Creating a dataset of 19th century English newspapers using image-to-text language models
Feb 18, 2025Oscar Wilde said, "The difference between literature and journalism is that journalism is unreadable, and literature is not read." Unfortunately, The digitally archived journalism of Oscar Wilde's 19th century often has no or poor quality Optical Character Recognition (OCR), reducing the accessibility of these archives and making them unreadable both figuratively and literally. This paper helps address the issue by performing OCR on "The Nineteenth Century Serials Edition" (NCSE), an 84k-page collection of 19th-century English newspapers and periodicals, using Pixtral 12B, a pre-trained image-to-text language model. The OCR capability of Pixtral was compared to 4 other OCR approaches, achieving a median character error rate of 1%, 5x lower than the next best model. The resulting NCSE v2.0 dataset features improved article identification, high-quality OCR, and text classified into four types and seventeen topics. The dataset contains 1.4 million entries, and 321 million words. Example use cases demonstrate analysis of topic similarity, readability, and event tracking. NCSE v2.0 is freely available to encourage historical and sociological research. As a result, 21st-century readers can now share Oscar Wilde's disappointment with 19th-century journalistic standards, reading the unreadable from the comfort of their own computers.
Scrambled text: training Language Models to correct OCR errors using synthetic data
Sep 29, 2024



OCR errors are common in digitised historical archives significantly affecting their usability and value. Generative Language Models (LMs) have shown potential for correcting these errors using the context provided by the corrupted text and the broader socio-cultural context, a process called Context Leveraging OCR Correction (CLOCR-C). However, getting sufficient training data for fine-tuning such models can prove challenging. This paper shows that fine-tuning a language model on synthetic data using an LM and using a character level Markov corruption process can significantly improve the ability to correct OCR errors. Models trained on synthetic data reduce the character error rate by 55% and word error rate by 32% over the base LM and outperform models trained on real data. Key findings include; training on under-corrupted data is better than over-corrupted data; non-uniform character level corruption is better than uniform corruption; More tokens-per-observation outperforms more observations for a fixed token budget. The outputs for this paper are a set of 8 heuristics for training effective CLOCR-C models, a dataset of 11,000 synthetic 19th century newspaper articles and scrambledtext a python library for creating synthetic corrupted data.
CLOCR-C: Context Leveraging OCR Correction with Pre-trained Language Models
Aug 30, 2024



The digitisation of historical print media archives is crucial for increasing accessibility to contemporary records. However, the process of Optical Character Recognition (OCR) used to convert physical records to digital text is prone to errors, particularly in the case of newspapers and periodicals due to their complex layouts. This paper introduces Context Leveraging OCR Correction (CLOCR-C), which utilises the infilling and context-adaptive abilities of transformer-based language models (LMs) to improve OCR quality. The study aims to determine if LMs can perform post-OCR correction, improve downstream NLP tasks, and the value of providing the socio-cultural context as part of the correction process. Experiments were conducted using seven LMs on three datasets: the 19th Century Serials Edition (NCSE) and two datasets from the Overproof collection. The results demonstrate that some LMs can significantly reduce error rates, with the top-performing model achieving over a 60% reduction in character error rate on the NCSE dataset. The OCR improvements extend to downstream tasks, such as Named Entity Recognition, with increased Cosine Named Entity Similarity. Furthermore, the study shows that providing socio-cultural context in the prompts improves performance, while misleading prompts lower performance. In addition to the findings, this study releases a dataset of 91 transcribed articles from the NCSE, containing a total of 40 thousand words, to support further research in this area. The findings suggest that CLOCR-C is a promising approach for enhancing the quality of existing digital archives by leveraging the socio-cultural information embedded in the LMs and the text requiring correction.
What's in the laundromat? Mapping and characterising offshore owned domestic property in London
Jul 22, 2022
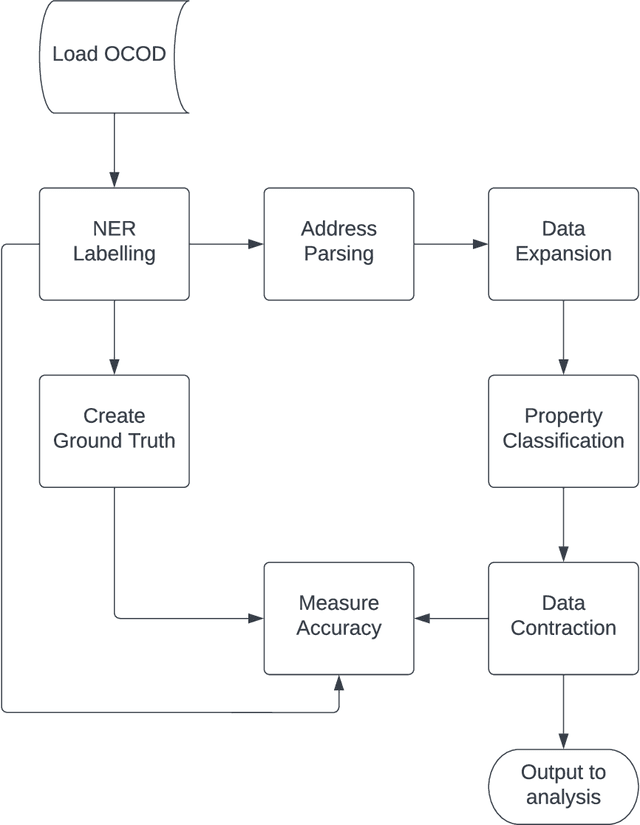


The UK, particularly London, is a global hub for money laundering, a significant portion of which uses domestic property. However, understanding the distribution and characteristics of offshore domestic property in the UK is challenging due to data availability. This paper attempts to remedy that situation by enhancing a publicly available dataset of UK property owned by offshore companies. We create a data processing pipeline which draws on several datasets and machine learning techniques to create a parsed set of addresses classified into six use classes. The enhanced dataset contains 138,000 properties 44,000 more than the original dataset. The majority are domestic (95k), with a disproportionate amount of those in London (42k). The average offshore domestic property in London is worth 1.33 million GBP collectively this amounts to approximately 56 Billion GBP. We perform an in-depth analysis of the offshore domestic property in London, comparing the price, distribution and entropy/concentration with Airbnb property, low-use/empty property and conventional domestic property. We estimate that the total amount of offshore, low-use and airbnb property in London is between 144,000 and 164,000 and that they are collectively worth between 145-174 billion GBP. Furthermore, offshore domestic property is more expensive and has higher entropy/concentration than all other property types. In addition, we identify two different types of offshore property, nested and individual, which have different price and distribution characteristics. Finally, we release the enhanced offshore property dataset, the complete low-use London dataset and the pipeline for creating the enhanced dataset to reduce the barriers to studying this topic.