 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Domain Shift for Deep Learning in Histopathology
Sep 26, 2019

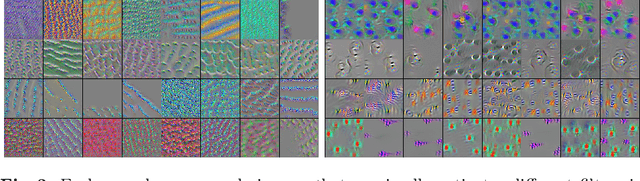
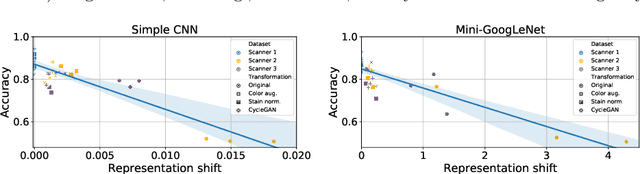
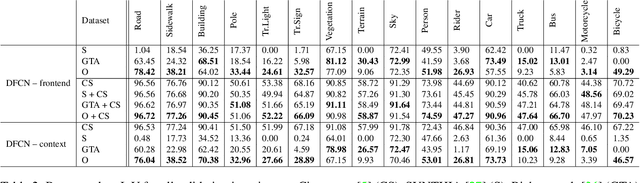
Domain shift is a significant problem in histopathology. There can be large differences in data characteristics of whole-slide images between medical centers and scanners, making generalization of deep learning to unseen data difficult. To gain a better understanding of the problem, we present a study on convolutional neural networks trained for tumor classification of H&E stained whole-slide images. We analyze how augmentation and normalization strategies affect performance and learned representations, and what features a trained model respond to. Most centrally, we present a novel measure for evaluating the distance between domains in the context of the learned representation of a particular model. This measure can reveal how sensitive a model is to domain variations, and can be used to detect new data that a model will have problems generalizing to. The results show how learning is heavily influenced by the preparation of training data, and that the latent representation used to do classification is sensitive to changes in data distribution, especially when training without augmentation or normalization.
Single-frame Regularization for Temporally Stable CNNs
Feb 27, 2019


Convolutional neural networks (CNNs) can model complicated non-linear relations between images. However, they are notoriously sensitive to small changes in the input. Most CNNs trained to describe image-to-image mappings generate temporally unstable results when applied to video sequences, leading to flickering artifacts and other inconsistencies over time. In order to use CNNs for video material, previous methods have relied on estimating dense frame-to-frame motion information (optical flow) in the training and/or the inference phase, or by exploring recurrent learning structures. We take a different approach to the problem, posing temporal stability as a regularization of the cost function. The regularization is formulated to account for different types of motion that can occur between frames, so that temporally stable CNNs can be trained without the need for video material or expensive motion estimation. The training can be performed as a fine-tuning operation, without architectural modifications of the CNN. Our evaluation shows that the training strategy leads to large improvements in temporal smoothness. Moreover, in situations where the quantity of training data is limited, the regularization can help in boosting the generalization performance to a much larger extent than what is possible with na\"ive augmentation strategies.
Synscapes: A Photorealistic Synthetic Dataset for Street Scene Parsing
Oct 19, 2018

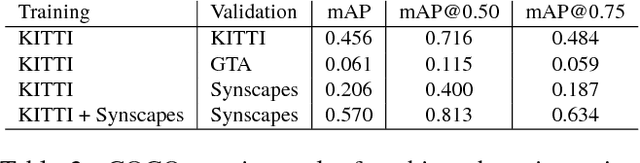
We introduce Synscapes -- a synthetic dataset for street scene parsing created using photorealistic rendering techniques, and show state-of-the-art results for training and validation as well as new types of analysis. We study the behavior of networks trained on real data when performing inference on synthetic data: a key factor in determining the equivalence of simulation environments. We also compare the behavior of networks trained on synthetic data and evaluated on real-world data. Additionally, by analyzing pre-trained, existing segmentation and detection models, we illustrate how uncorrelated images along with a detailed set of annotations open up new avenues for analysis of computer vision systems, providing fine-grain information about how a model's performance changes according to factors such as distance, occlusion and relative object orientation.
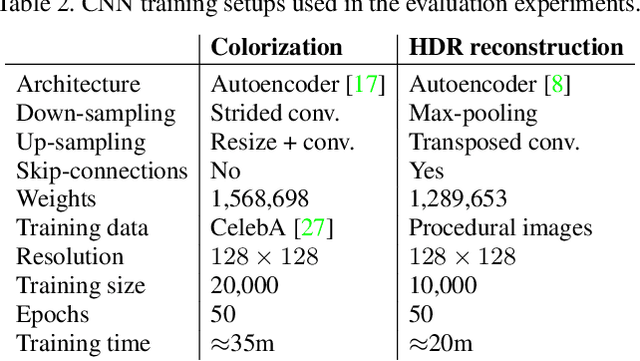
HDR image reconstruction from a single exposure using deep CNNs
Oct 20, 2017
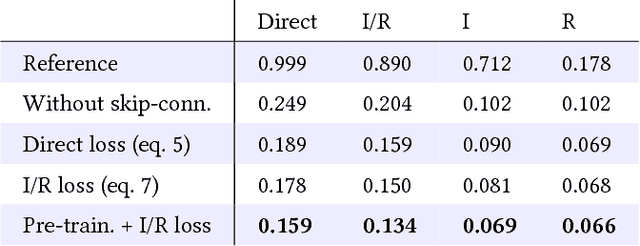
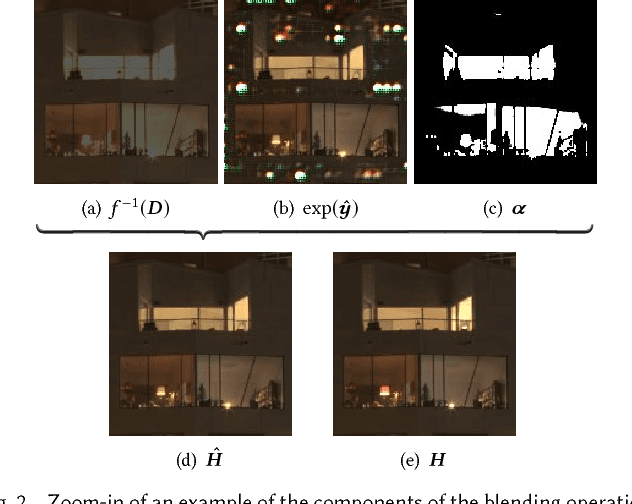
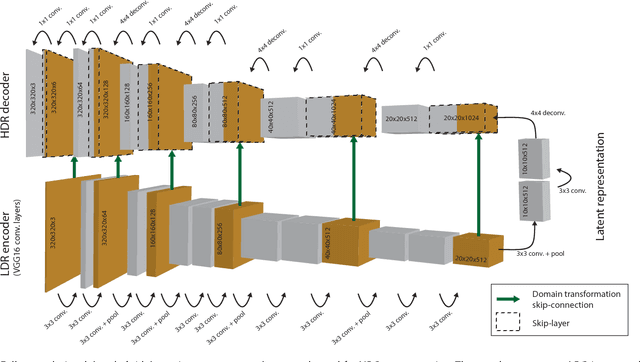
Camera sensors can only capture a limited range of luminance simultaneously, and in order to create high dynamic range (HDR) images a set of different exposures are typically combined. In this paper we address the problem of predicting information that have been lost in saturated image areas, in order to enable HDR reconstruction from a single exposure. We show that this problem is well-suited for deep learning algorithms, and propose a deep convolutional neural network (CNN) that is specifically designed taking into account the challenges in predicting HDR values. To train the CNN we gather a large dataset of HDR images, which we augment by simulating sensor saturation for a range of cameras. To further boost robustness, we pre-train the CNN on a simulated HDR dataset created from a subset of the MIT Places database. We demonstrate that our approach can reconstruct high-resolution visually convincing HDR results in a wide range of situations, and that it generalizes well to reconstruction of images captured with arbitrary and low-end cameras that use unknown camera response functions and post-processing. Furthermore, we compare to existing methods for HDR expansion, and show high quality results also for image based lighting. Finally, we evaluate the results in a subjective experiment performed on an HDR display. This shows that the reconstructed HDR images are visually convincing, with large improvements as compared to existing methods.
* 15 pages, 19 figures, Siggraph Asia 2017. Project webpage located at http://hdrv.org/hdrcnn/ where paper with high quality images is available, as well as supplementary material (document, images, video and source code)
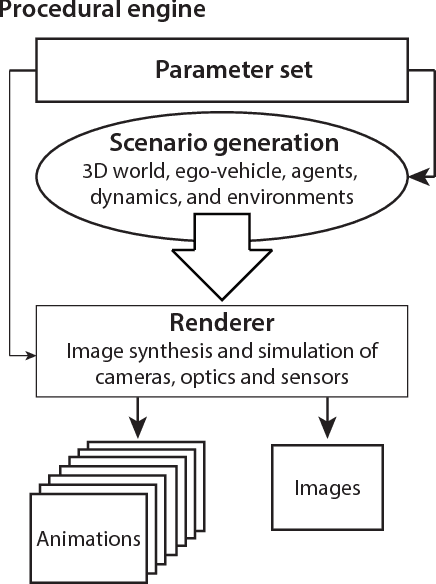
Procedural Modeling and Physically Based Rendering for Synthetic Data Generation in Automotive Applications
Oct 18, 2017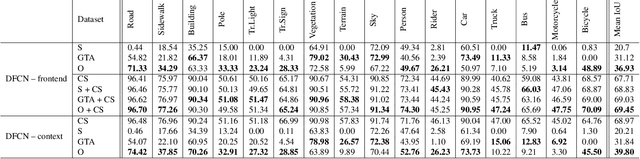

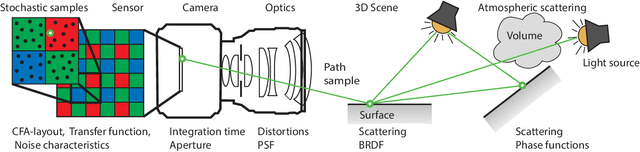
We present an overview and evaluation of a new, systematic approach for generation of highly realistic, annotated synthetic data for training of deep neural networks in computer vision tasks. The main contribution is a procedural world modeling approach enabling high variability coupled with physically accurate image synthesis, and is a departure from the hand-modeled virtual worlds and approximate image synthesis methods used in real-time applications. The benefits of our approach include flexible, physically accurate and scalable image synthesis, implicit wide coverage of classes and features, and complete data introspection for annotations, which all contribute to quality and cost efficiency. To evaluate our approach and the efficacy of the resulting data, we use semantic segmentation for autonomous vehicles and robotic navigation as the main application, and we train multiple deep learning architectures using synthetic data with and without fine tuning on organic (i.e. real-world) data. The evaluation shows that our approach improves the neural network's performance and that even modest implementation efforts produce state-of-the-art results.
A Unified Framework for Multi-Sensor HDR Video Reconstruction
Aug 22, 2013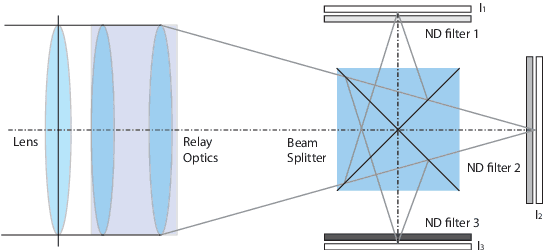
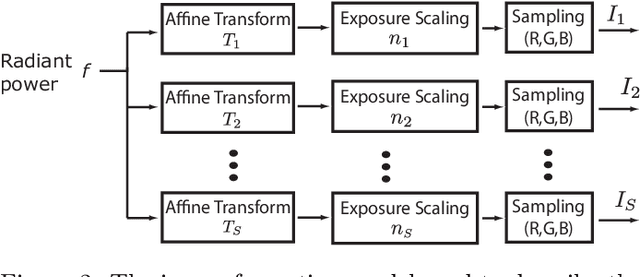
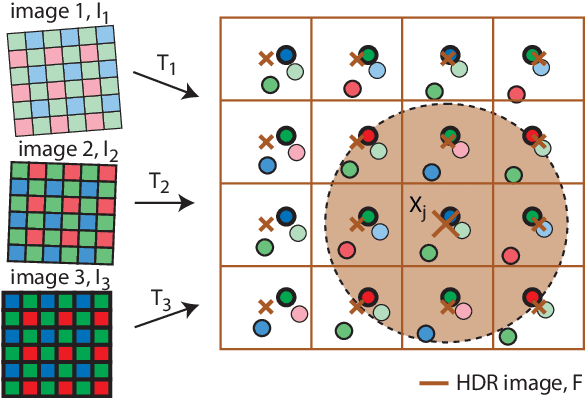
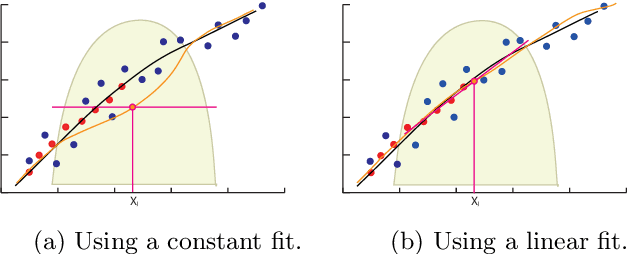
One of the most successful approaches to modern high quality HDR-video capture is to use camera setups with multiple sensors imaging the scene through a common optical system. However, such systems pose several challenges for HDR reconstruction algorithms. Previous reconstruction techniques have considered debayering, denoising, resampling (align- ment) and exposure fusion as separate problems. In contrast, in this paper we present a unifying approach, performing HDR assembly directly from raw sensor data. Our framework includes a camera noise model adapted to HDR video and an algorithm for spatially adaptive HDR reconstruction based on fitting of local polynomial approximations to observed sensor data. The method is easy to implement and allows reconstruction to an arbitrary resolution and output mapping. We present an implementation in CUDA and show real-time performance for an experimental 4 Mpixel multi-sensor HDR video system. We further show that our algorithm has clear advantages over existing methods, both in terms of flexibility and reconstruction quality.