 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Monoculture and Social Welfare
Jan 14, 2021
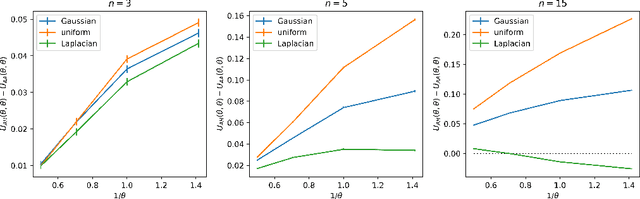
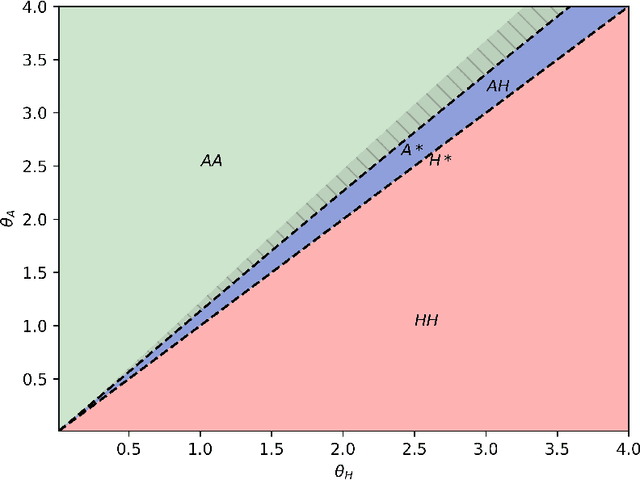
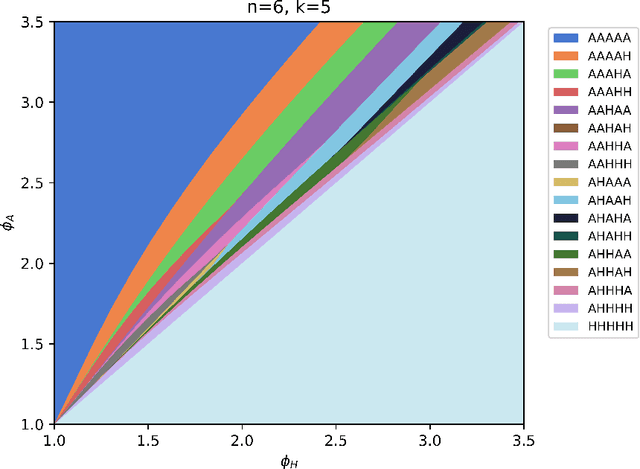
As algorithms are increasingly applied to screen applicants for high-stakes decisions in employment, lending, and other domains, concerns have been raised about the effects of algorithmic monoculture, in which many decision-makers all rely on the same algorithm. This concern invokes analogies to agriculture, where a monocultural system runs the risk of severe harm from unexpected shocks. Here we show that the dangers of algorithmic monoculture run much deeper, in that monocultural convergence on a single algorithm by a group of decision-making agents, even when the algorithm is more accurate for any one agent in isolation, can reduce the overall quality of the decisions being made by the full collection of agents. Unexpected shocks are therefore not needed to expose the risks of monoculture; it can hurt accuracy even under "normal" operations, and even for algorithms that are more accurate when used by only a single decision-maker. Our results rely on minimal assumptions, and involve the development of a probabilistic framework for analyzing systems that use multiple noisy estimates of a set of alternatives.
Model-sharing Games: Analyzing Federated Learning Under Voluntary Participation
Oct 18, 2020
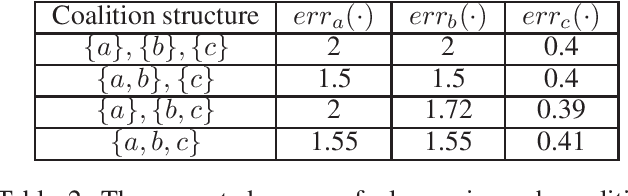
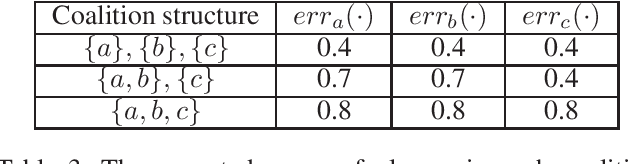
Federated learning is a setting where agents, each with access to their own data source, combine models learned from local data to create a global model. If agents are drawing their data from different distributions, though, federated learning might produce a biased global model that is not optimal for each agent. This means that agents face a fundamental question: should they join the global model or stay with their local model? In this work, we show how this situation can be naturally analyzed through the framework of coalitional game theory. Motivated by these considerations, we propose the following game: there are heterogeneous players with different model parameters governing their data distribution and different amounts of data they have noisily drawn from their own distribution. Each player's goal is to obtain a model with minimal expected mean squared error (MSE) on their own distribution. They have a choice of fitting a model based solely on their own data, or combining their learned parameters with those of some subset of the other players. Combining models reduces the variance component of their error through access to more data, but increases the bias because of the heterogeneity of distributions. In this work, we derive exact expected MSE values for problems in linear regression and mean estimation. We use these values to analyze the resulting game in the framework of hedonic game theory; we study how players might divide into coalitions, where each set of players within a coalition jointly constructs a single model. In a case with arbitrarily many players that each have either a "small" or "large" amount of data, we constructively show that there always exists a stable partition of players into coalitions.
Learning Personalized Models of Human Behavior in Chess
Aug 23, 2020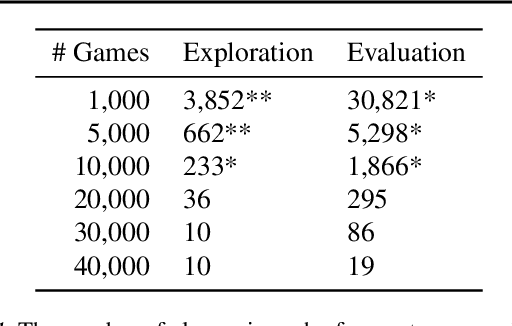
Even when machine learning systems surpass human ability in a domain, there are many reasons why AI systems that capture human-like behavior would be desirable: humans may want to learn from them, they may need to collaborate with them, or they may expect them to serve as partners in an extended interaction. Motivated by this goal of human-like AI systems, the problem of predicting human actions -- as opposed to predicting optimal actions -- has become an increasingly useful task. We extend this line of work by developing highly accurate personalized models of human behavior in the context of chess. Chess is a rich domain for exploring these questions, since it combines a set of appealing features: AI systems have achieved superhuman performance but still interact closely with human chess players both as opponents and preparation tools, and there is an enormous amount of recorded data on individual players. Starting with an open-source version of AlphaZero trained on a population of human players, we demonstrate that we can significantly improve prediction of a particular player's moves by applying a series of fine-tuning adjustments. The differences in prediction accuracy between our personalized models and unpersonalized models are at least as large as the differences between unpersonalized models and a simple baseline. Furthermore, we can accurately perform stylometry -- predicting who made a given set of actions -- indicating that our personalized models capture human decision-making at an individual level.
Aligning Superhuman AI and Human Behavior: Chess as a Model System
Jun 19, 2020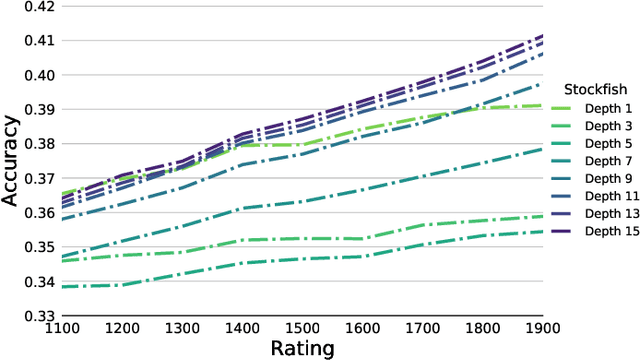
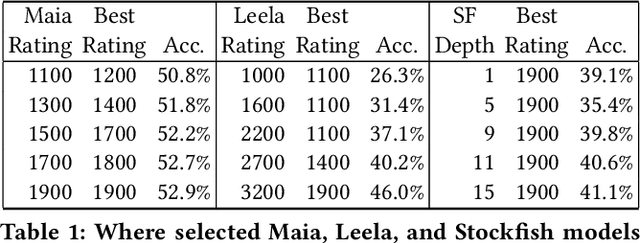
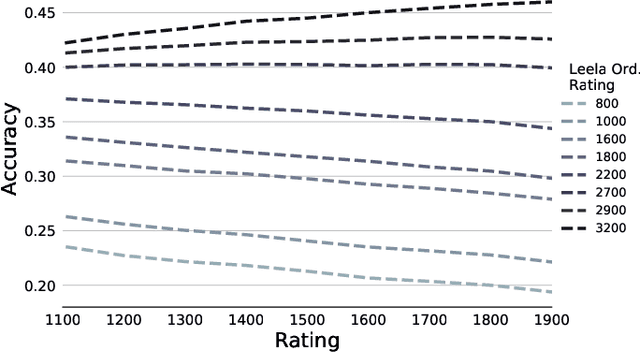
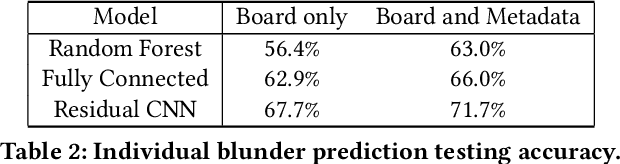
As artificial intelligence becomes increasingly intelligent---in some cases, achieving superhuman performance---there is growing potential for humans to learn from and collaborate with algorithms. However, the ways in which AI systems approach problems are often different from the ways people do, and thus may be uninterpretable and hard to learn from. A crucial step in bridging this gap between human and artificial intelligence is modeling the granular actions that constitute human behavior, rather than simply matching aggregate human performance. We pursue this goal in a model system with a long history in artificial intelligence: chess. The aggregate performance of a chess player unfolds as they make decisions over the course of a game. The hundreds of millions of games played online by players at every skill level form a rich source of data in which these decisions, and their exact context, are recorded in minute detail. Applying existing chess engines to this data, including an open-source implementation of AlphaZero, we find that they do not predict human moves well. We develop and introduce Maia, a customized version of Alpha-Zero trained on human chess games, that predicts human moves at a much higher accuracy than existing engines, and can achieve maximum accuracy when predicting decisions made by players at a specific skill level in a tuneable way. For a dual task of predicting whether a human will make a large mistake on the next move, we develop a deep neural network that significantly outperforms competitive baselines. Taken together, our results suggest that there is substantial promise in designing artificial intelligence systems with human collaboration in mind by first accurately modeling granular human decision-making.
Frozen Binomials on the Web: Word Ordering and Language Conventions in Online Text
Mar 07, 2020
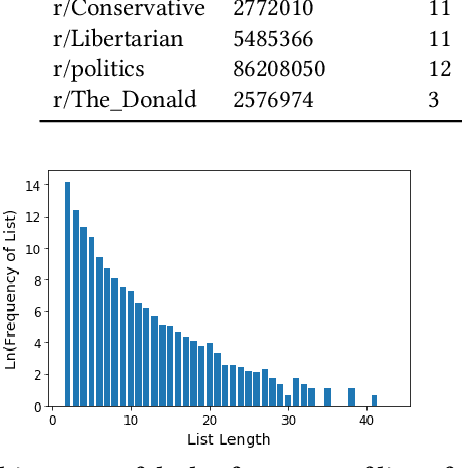
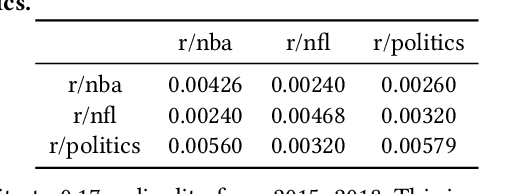
There is inherent information captured in the order in which we write words in a list. The orderings of binomials --- lists of two words separated by `and' or `or' --- has been studied for more than a century. These binomials are common across many areas of speech, in both formal and informal text. In the last century, numerous explanations have been given to describe what order people use for these binomials, from differences in semantics to differences in phonology. These rules describe primarily `frozen' binomials that exist in exactly one ordering and have lacked large-scale trials to determine efficacy. Online text provides a unique opportunity to study these lists in the context of informal text at a very large scale. In this work, we expand the view of binomials to include a large-scale analysis of both frozen and non-frozen binomials in a quantitative way. Using this data, we then demonstrate that most previously proposed rules are ineffective at predicting binomial ordering. By tracking the order of these binomials across time and communities we are able to establish additional, unexplored dimensions central to these predictions. Expanding beyond the question of individual binomials, we also explore the global structure of binomials in various communities, establishing a new model for these lists and analyzing this structure for non-frozen and frozen binomials. Additionally, novel analysis of trinomials --- lists of length three --- suggests that none of the binomials analysis applies in these cases. Finally, we demonstrate how large data sets gleaned from the web can be used in conjunction with older theories to expand and improve on old questions.
Localized Flow-Based Clustering in Hypergraphs
Feb 21, 2020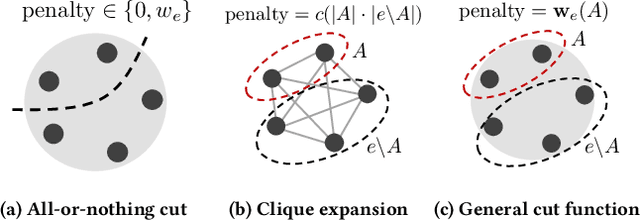
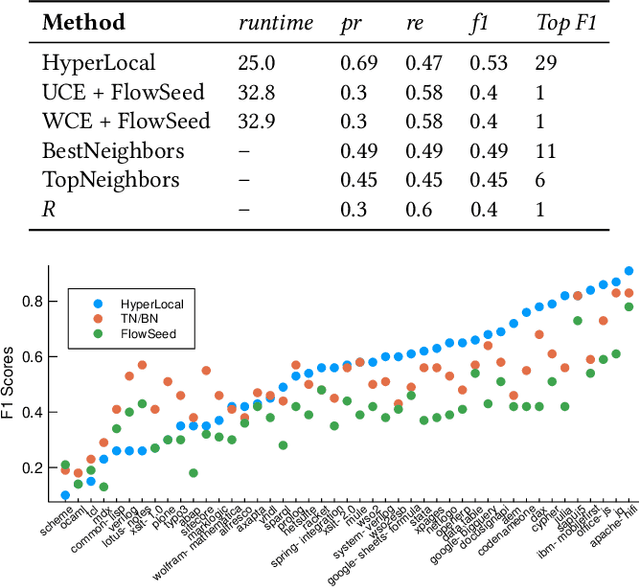
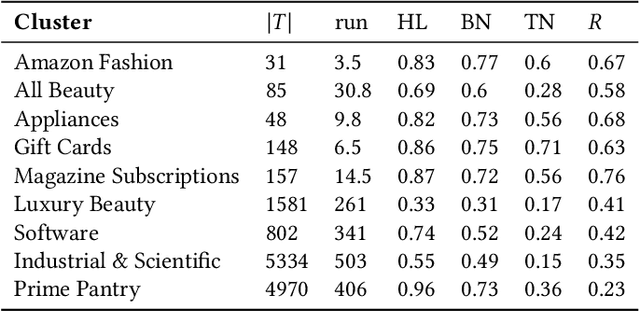
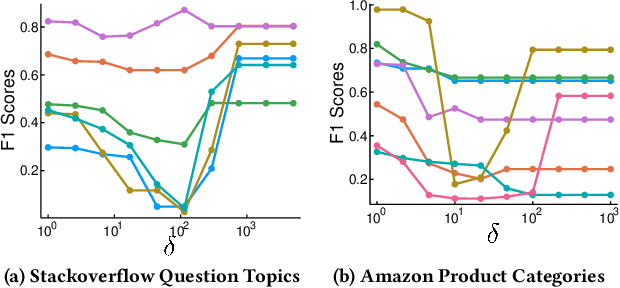
Local graph clustering algorithms are designed to efficiently detect small clusters of nodes that are biased to a localized region of a large graph. Although many techniques have been developed for local clustering in graphs, very few algorithms have been designed to detect local clusters in hypergraphs, which better model complex systems involving multiway relationships between data objects. In this paper we present a framework for local clustering in hypergraphs based on minimum cuts and maximum flows. Our approach extends previous research on flow-based local graph clustering, but has been generalized in a number of key ways. First of all, we demonstrate how to incorporate recent results on generalized hypergraph $s$-$t$ cut problems. This allows us to accommodate a wide range of different hypergraph cut functions, which can assign different penalties based on how each hyperedge is split across different clusters. Furthermore, our algorithm comes with a number of attractive theoretical properties in terms of recovering nodes sets with low hypergraph conductance and hypergraph normalized cut scores. Finally, and most importantly, our method is strongly-local, meaning that its runtime depends only on the size of an input set. In practice this allows our method to quickly find localized clusters without exploring an entire input hypergraph. We demonstrate the power of our method in local cluster detection experiments on an Amazon product hypergraph and a Stack Overflow question hypergraph. Although both datasets involve millions of nodes, millions of edges, and a large average hyperedge size, we are able to detect local clusters in a matter of a few seconds or a few minutes, depending on the size of the cluster.
Measuring the Completeness of Theories
Oct 15, 2019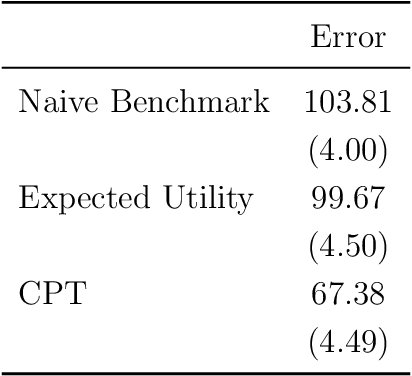
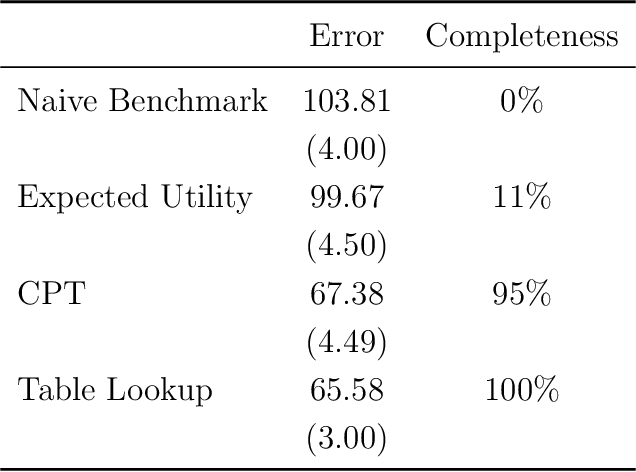
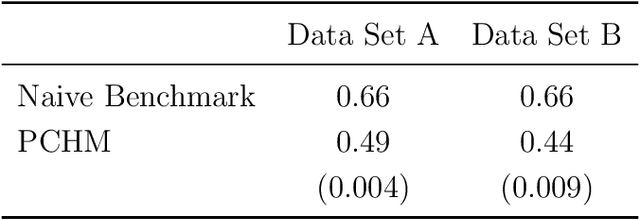
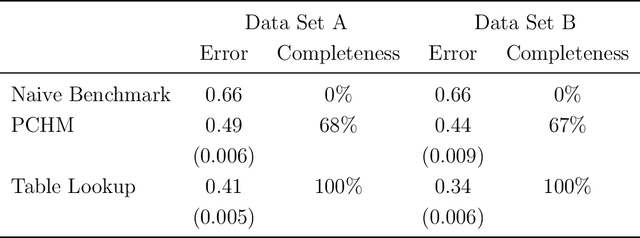
We use machine learning to provide a tractable measure of the amount of predictable variation in the data that a theory captures, which we call its "completeness." We apply this measure to three problems: assigning certain equivalents to lotteries, initial play in games, and human generation of random sequences. We discover considerable variation in the completeness of existing models, which sheds light on whether to focus on developing better models with the same features or instead to look for new features that will improve predictions. We also illustrate how and why completeness varies with the experiments considered, which highlights the role played in choosing which experiments to run.
Mitigating Bias in Algorithmic Employment Screening: Evaluating Claims and Practices
Jun 21, 2019
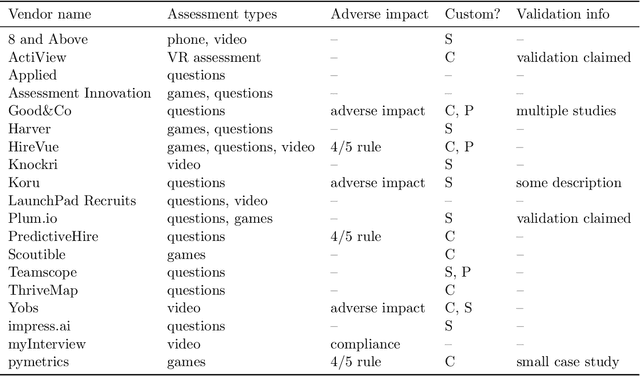

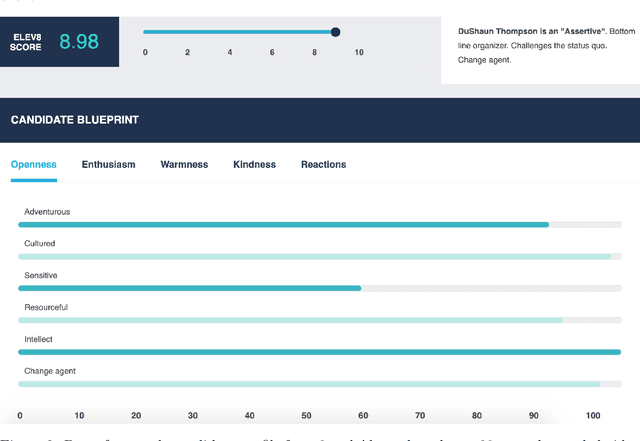
There has been rapidly growing interest in the use of algorithms for employment assessment, especially as a means to address or mitigate bias in hiring. Yet, to date, little is known about how these methods are being used in practice. How are algorithmic assessments built, validated, and examined for bias? In this work, we document and assess the claims and practices of companies offering algorithms for employment assessment, using a methodology that can be applied to evaluate similar applications and issues of bias in other domains. In particular, we identify vendors of algorithmic pre-employment assessments (i.e., algorithms to screen candidates), document what they have disclosed about their development and validation procedures, and evaluate their techniques for detecting and mitigating bias. We find that companies' formulation of "bias" varies, as do their approaches to dealing with it. We also discuss the various choices vendors make regarding data collection and prediction targets, in light of the risks and trade-offs that these choices pose. We consider the implications of these choices and we raise a number of technical and legal considerations.
Planted Hitting Set Recovery in Hypergraphs
May 14, 2019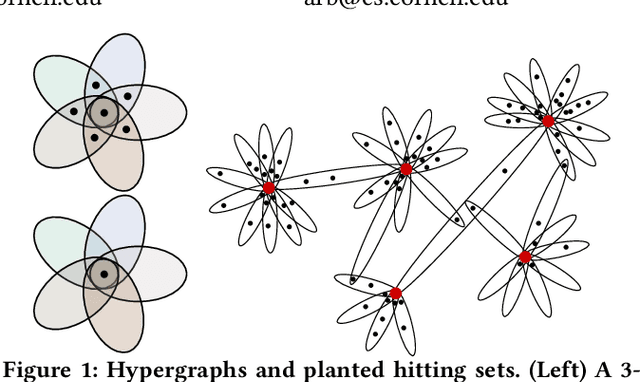
In various application areas, networked data is collected by measuring interactions involving some specific set of core nodes. This results in a network dataset containing the core nodes along with a potentially much larger set of fringe nodes that all have at least one interaction with a core node. In many settings, this type of data arises for structures that are richer than graphs, because they involve the interactions of larger sets; for example, the core nodes might be a set of individuals under surveillance, where we observe the attendees of meetings involving at least one of the core individuals. We model such scenarios using hypergraphs, and we study the problem of core recovery: if we observe the hypergraph but not the labels of core and fringe nodes, can we recover the "planted" set of core nodes in the hypergraph? We provide a theoretical framework for analyzing the recovery of such a set of core nodes and use our theory to develop a practical and scalable algorithm for core recovery. The crux of our analysis and algorithm is that the core nodes are a hitting set of the hypergraph, meaning that every hyperedge has at least one node in the set of core nodes. We demonstrate the efficacy of our algorithm on a number of real-world datasets, outperforming competitive baselines derived from network centrality and core-periphery measures.
The Algorithmic Automation Problem: Prediction, Triage, and Human Effort
Mar 28, 2019
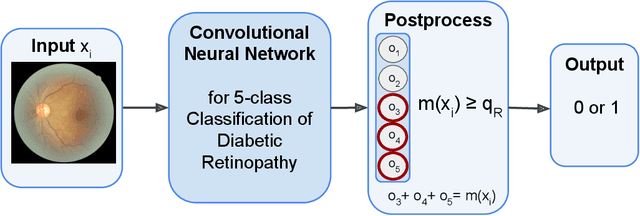
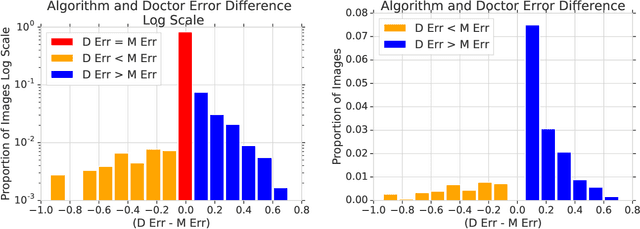
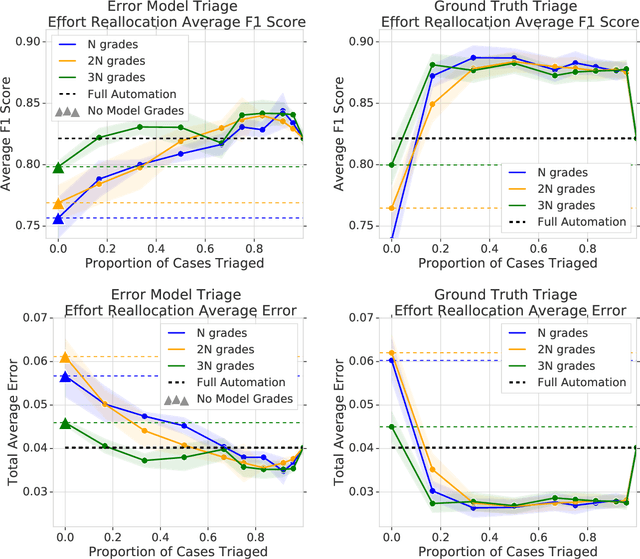
In a wide array of areas, algorithms are matching and surpassing the performance of human experts, leading to consideration of the roles of human judgment and algorithmic prediction in these domains. The discussion around these developments, however, has implicitly equated the specific task of prediction with the general task of automation. We argue here that automation is broader than just a comparison of human versus algorithmic performance on a task; it also involves the decision of which instances of the task to give to the algorithm in the first place. We develop a general framework that poses this latter decision as an optimization problem, and we show how basic heuristics for this optimization problem can lead to performance gains even on heavily-studied applications of AI in medicine. Our framework also serves to highlight how effective automation depends crucially on estimating both algorithmic and human error on an instance-by-instance basis, and our results show how improvements in these error estimation problems can yield significant gains for automation as well.