 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Likelihood on the Joint (Data, Condition) Distribution for Solving Ill-Posed Problems with Conditional Flow Models
Aug 24, 2022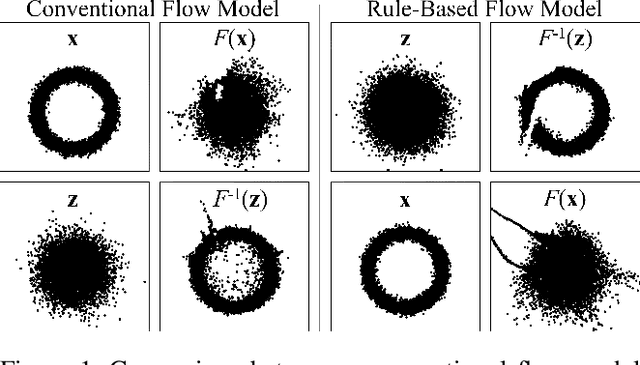
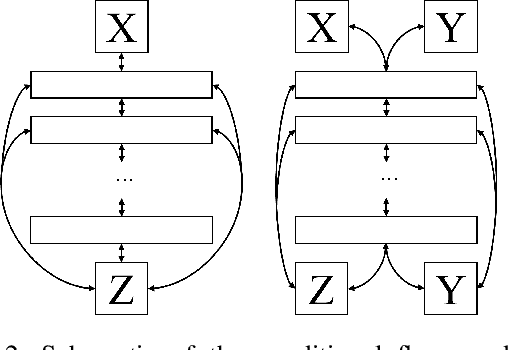
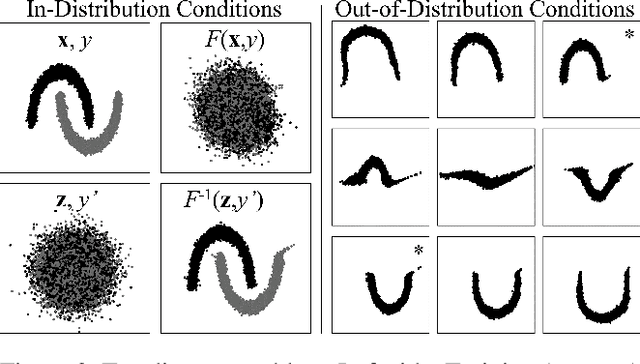
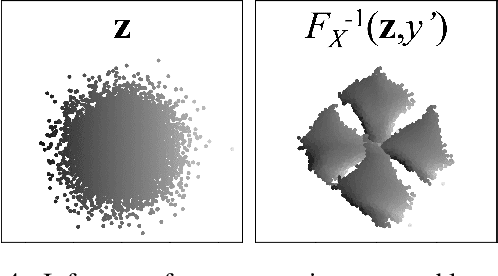
I describe a trick for training flow models using a prescribed rule as a surrogate for maximum likelihood. The utility of this trick is limited for non-conditional models, but an extension of the approach, applied to maximum likelihood of the joint probability distribution of data and conditioning information, can be used to train sophisticated \textit{conditional} flow models. Unlike previous approaches, this method is quite simple: it does not require explicit knowledge of the distribution of conditions, auxiliary networks or other specific architecture, or additional loss terms beyond maximum likelihood, and it preserves the correspondence between latent and data spaces. The resulting models have all the properties of non-conditional flow models, are robust to unexpected inputs, and can predict the distribution of solutions conditioned on a given input. They come with guarantees of prediction representativeness and are a natural and powerful way to solve highly uncertain problems. I demonstrate these properties on easily visualized toy problems, then use the method to successfully generate class-conditional images and to reconstruct highly degraded images via super-resolution.
Requirements for Developing Robust Neural Networks
Oct 04, 2019Validation accuracy is a necessary, but not sufficient, measure of a neural network classifier's quality. High validation accuracy during development does not guarantee that a model is free of serious flaws, such as vulnerability to adversarial attacks or a tendency to misclassify (with high confidence) data it was not trained on. The model may also be incomprehensible to a human or base its decisions on unreasonable criteria. These problems, which are not unique to classifiers, have been the focus of a substantial amount of recent research. However, they are not prioritized during model development, which almost always optimizes on validation accuracy to the exclusion of everything else. The product of this approach is likely to fail in unexpected ways outside of the training environment. We believe that, in addition to validation accuracy, the model development process must give added weight to other performance metrics such as explainability, resistance to adversarial attacks, and overconfidence on out-of-distribution data.