 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Point Proximity Encoding For Vector-Mode Geospatial Machine Learning
Jun 05, 2025Vector-mode geospatial data -- points, lines, and polygons -- must be encoded into an appropriate form in order to be used with traditional machine learning and artificial intelligence models. Encoding methods attempt to represent a given shape as a vector that captures its essential geometric properties. This paper presents an encoding method based on scaled distances from a shape to a set of reference points within a region of interest. The method, MultiPoint Proximity (MPP) encoding, can be applied to any type of shape, enabling the parameterization of machine learning models with encoded representations of vector-mode geospatial features. We show that MPP encoding possesses the desirable properties of shape-centricity and continuity, can be used to differentiate spatial objects based on their geometric features, and can capture pairwise spatial relationships with high precision. In all cases, MPP encoding is shown to perform better than an alternative method based on rasterization.
Multi-Level Anomaly Detection on Time-Varying Graph Data
Apr 20, 2015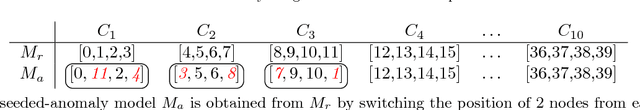
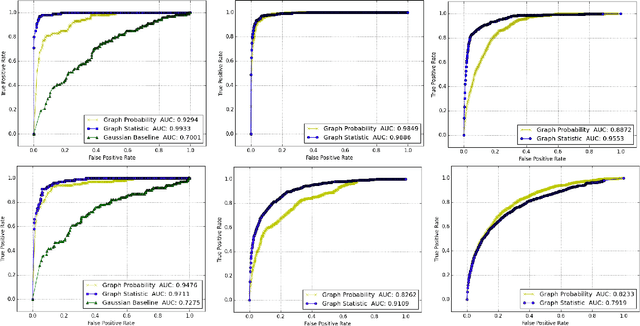
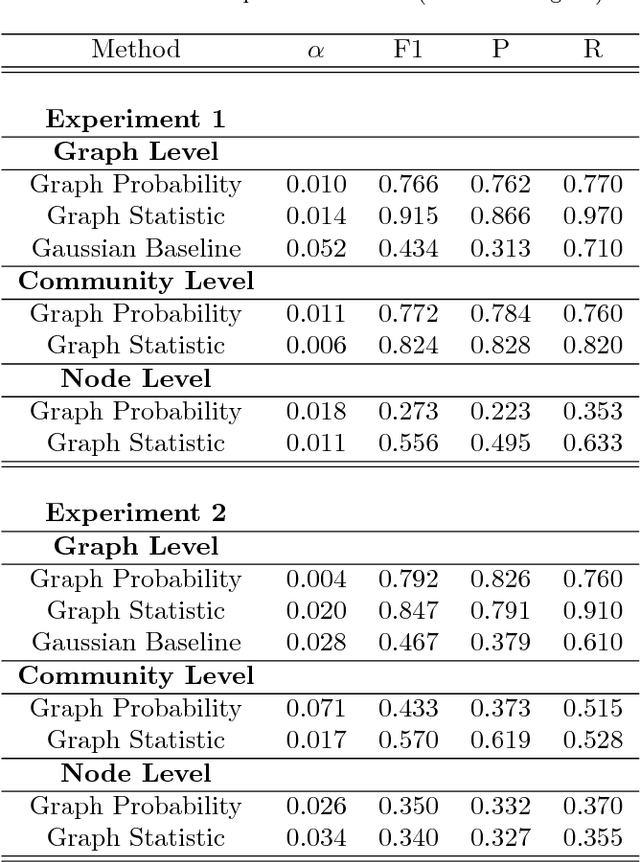
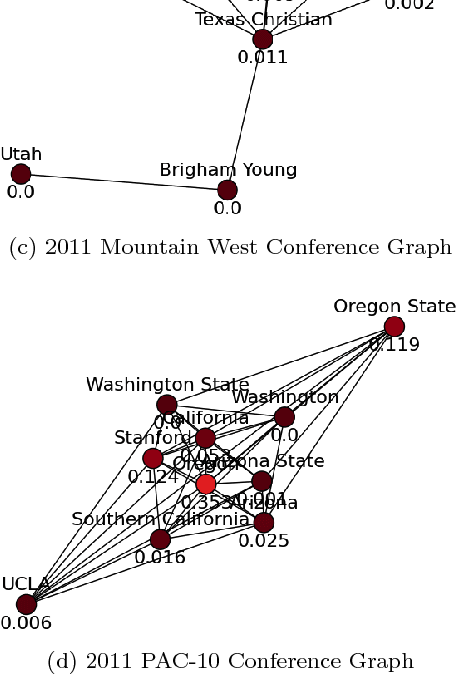
This work presents a novel modeling and analysis framework for graph sequences which addresses the challenge of detecting and contextualizing anomalies in labelled, streaming graph data. We introduce a generalization of the BTER model of Seshadhri et al. by adding flexibility to community structure, and use this model to perform multi-scale graph anomaly detection. Specifically, probability models describing coarse subgraphs are built by aggregating probabilities at finer levels, and these closely related hierarchical models simultaneously detect deviations from expectation. This technique provides insight into a graph's structure and internal context that may shed light on a detected event. Additionally, this multi-scale analysis facilitates intuitive visualizations by allowing users to narrow focus from an anomalous graph to particular subgraphs or nodes causing the anomaly. For evaluation, two hierarchical anomaly detectors are tested against a baseline Gaussian method on a series of sampled graphs. We demonstrate that our graph statistics-based approach outperforms both a distribution-based detector and the baseline in a labeled setting with community structure, and it accurately detects anomalies in synthetic and real-world datasets at the node, subgraph, and graph levels. To illustrate the accessibility of information made possible via this technique, the anomaly detector and an associated interactive visualization tool are tested on NCAA football data, where teams and conferences that moved within the league are identified with perfect recall, and precision greater than 0.786.