 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLDS: A Dataset for Weight-Space Analysis of Neural Networks
Apr 21, 2021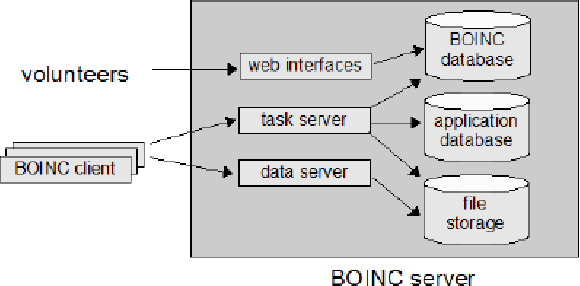


Neural networks are powerful models that solve a variety of complex real-world problems. However, the stochastic nature of training and large number of parameters in a typical neural model makes them difficult to evaluate via inspection. Research shows this opacity can hide latent undesirable behavior, be it from poorly representative training data or via malicious intent to subvert the behavior of the network, and that this behavior is difficult to detect via traditional indirect evaluation criteria such as loss. Therefore, it is time to explore direct ways to evaluate a trained neural model via its structure and weights. In this paper we present MLDS, a new dataset consisting of thousands of trained neural networks with carefully controlled parameters and generated via a global volunteer-based distributed computing platform. This dataset enables new insights into both model-to-model and model-to-training-data relationships. We use this dataset to show clustering of models in weight-space with identical training data and meaningful divergence in weight-space with even a small change to the training data, suggesting that weight-space analysis is a viable and effective alternative to loss for evaluating neural networks.
Learning Device Models with Recurrent Neural Networks
May 21, 2018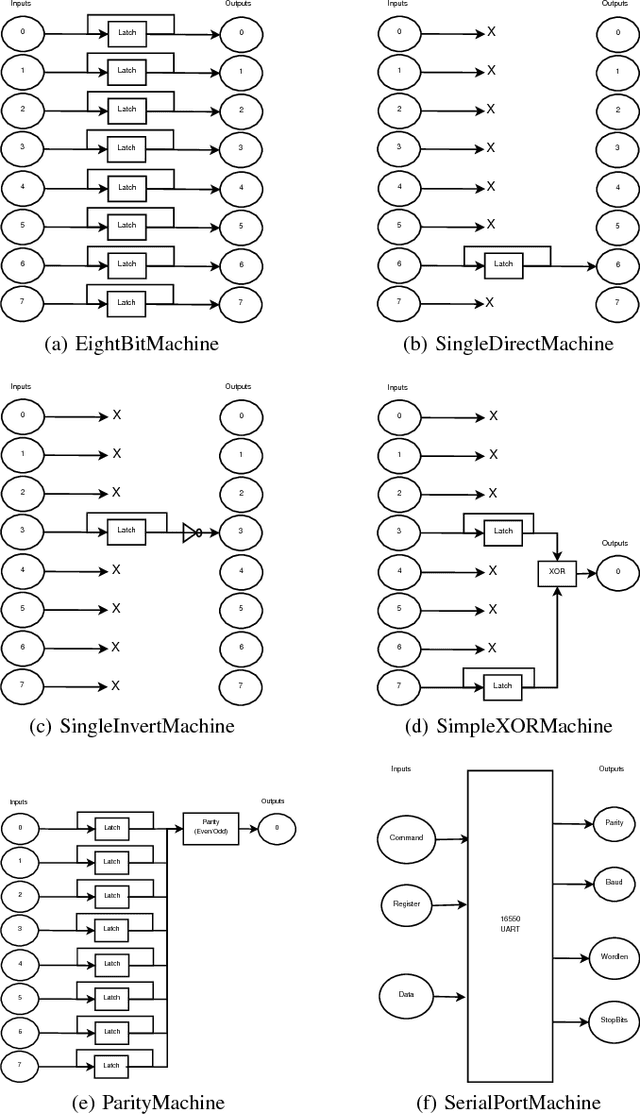



Recurrent neural networks (RNNs) are powerful constructs capable of modeling complex systems, up to and including Turing Machines. However, learning such complex models from finite training sets can be difficult. In this paper we empirically show that RNNs can learn models of computer peripheral devices through input and output state observation. This enables automated development of functional software-only models of hardware devices. Such models are applicable to any number of tasks, including device validation, driver development, code de-obfuscation, and reverse engineering. We show that the same RNN structure successfully models six different devices from simple test circuits up to a 16550 UART serial port, and verify that these models are capable of producing equivalent output to real hardware.
Automatic Classification of Object Code Using Machine Learning
May 06, 2018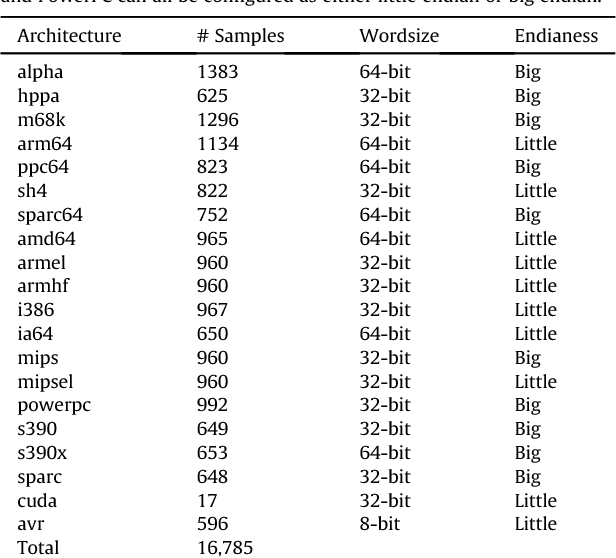
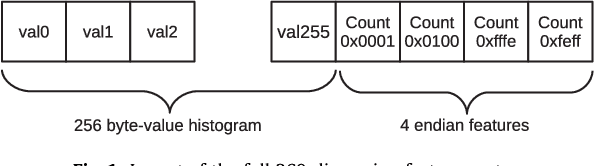

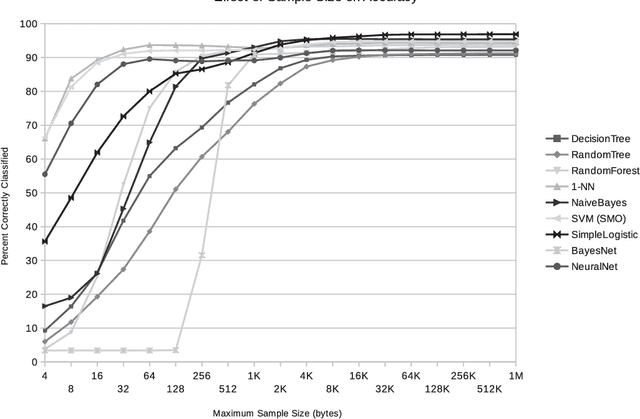
Recent research has repeatedly shown that machine learning techniques can be applied to either whole files or file fragments to classify them for analysis. We build upon these techniques to show that for samples of un-labeled compiled computer object code, one can apply the same type of analysis to classify important aspects of the code, such as its target architecture and endianess. We show that using simple byte-value histograms we retain enough information about the opcodes within a sample to classify the target architecture with high accuracy, and then discuss heuristic-based features that exploit information within the operands to determine endianess. We introduce a dataset with over 16000 code samples from 20 architectures and experimentally show that by using our features, classifiers can achieve very high accuracy with relatively small sample sizes.