 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Communication-Efficient Algorithm for Exponentially Fast Non-Bayesian Learning in Networks
Sep 04, 2019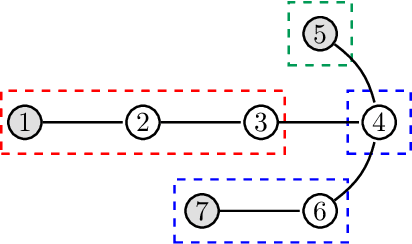
We introduce a simple time-triggered protocol to achieve communication-efficient non-Bayesian learning over a network. Specifically, we consider a scenario where a group of agents interact over a graph with the aim of discerning the true state of the world that generates their joint observation profiles. To address this problem, we propose a novel distributed learning rule wherein agents aggregate neighboring beliefs based on a min-protocol, and the inter-communication intervals grow geometrically at a rate $a \geq 1$. Despite such sparse communication, we show that each agent is still able to rule out every false hypothesis exponentially fast with probability $1$, as long as $a$ is finite. For the special case when communication occurs at every time-step, i.e., when $a=1$, we prove that the asymptotic learning rates resulting from our algorithm are network-structure independent, and a strict improvement upon those existing in the literature. In contrast, when $a>1$, our analysis reveals that the asymptotic learning rates vary across agents, and exhibit a non-trivial dependence on the network topology coupled with the relative entropies of the agents' likelihood models. This motivates us to consider the problem of allocating signal structures to agents to maximize appropriate performance metrics. In certain special cases, we show that the eccentricity centrality and the decay centrality of the underlying graph help identify optimal allocations; for more general scenarios, we bound the deviation from the optimal allocation as a function of the parameter $a$, and the diameter of the communication graph.
A New Approach to Distributed Hypothesis Testing and Non-Bayesian Learning: Improved Learning Rate and Byzantine-Resilience
Jul 05, 2019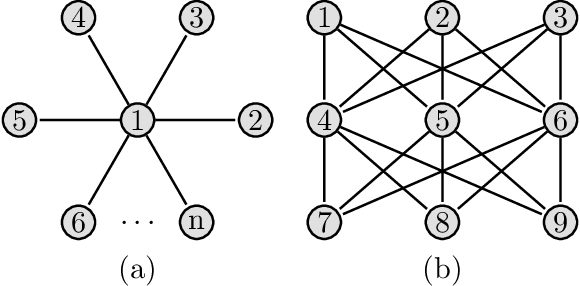
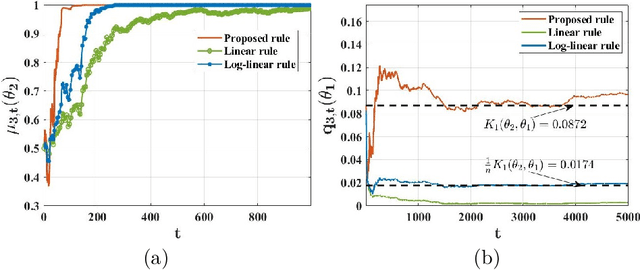
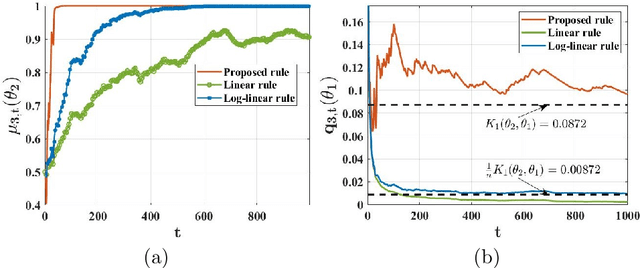
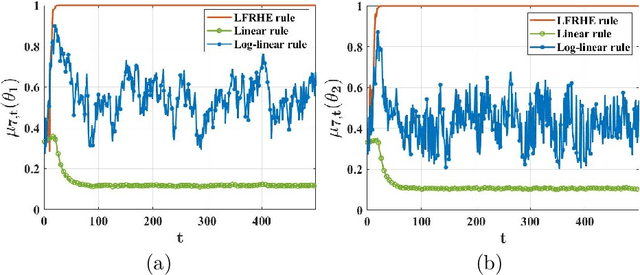
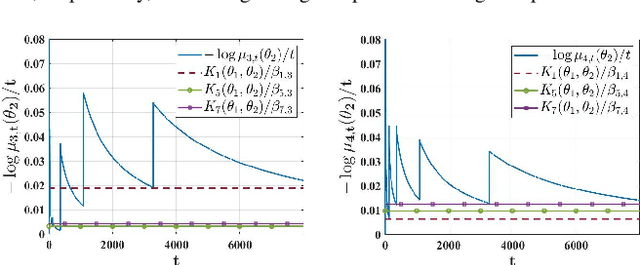
We study a setting where a group of agents, each receiving partially informative private signals, seek to collaboratively learn the true underlying state of the world (from a finite set of hypotheses) that generates their joint observation profiles. To solve this problem, we propose a distributed learning rule that differs fundamentally from existing approaches, in that it does not employ any form of "belief-averaging". Instead, agents update their beliefs based on a min-rule. Under standard assumptions on the observation model and the network structure, we establish that each agent learns the truth asymptotically almost surely. As our main contribution, we prove that with probability 1, each false hypothesis is ruled out by every agent exponentially fast at a network-independent rate that is strictly larger than existing rates. We then develop a computationally-efficient variant of our learning rule that is provably resilient to agents who do not behave as expected (as represented by a Byzantine adversary model) and deliberately try to spread misinformation.
A New Approach for Distributed Hypothesis Testing with Extensions to Byzantine-Resilience
Mar 14, 2019We study a setting where a group of agents, each receiving partially informative private observations, seek to collaboratively learn the true state (among a set of hypotheses) that explains their joint observation profiles over time. To solve this problem, we propose a distributed learning rule that differs fundamentally from existing approaches, in the sense, that it does not employ any form of "belief-averaging". Specifically, every agent maintains a local belief (on each hypothesis) that is updated in a Bayesian manner without any network influence, and an actual belief that is updated (up to normalization) as the minimum of its own local belief and the actual beliefs of its neighbors. Under minimal requirements on the signal structures of the agents and the underlying communication graph, we establish consistency of the proposed belief update rule, i.e., we show that the actual beliefs of the agents asymptotically concentrate on the true state almost surely. As one of the key benefits of our approach, we show that our learning rule can be extended to scenarios that capture misbehavior on the part of certain agents in the network, modeled via the Byzantine adversary model. In particular, we prove that each non-adversarial agent can asymptotically learn the true state of the world almost surely, under appropriate conditions on the observation model and the network topology.