 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementing Smart Contracts: The case of NFT-rental with pay-per-like
Jul 23, 2023



Non-fungible tokens(NFTs) are on the rise. They can represent artworks exhibited for marketing purposes on webpages of companies or online stores -- analogously to physical artworks. Lending of NFTs is an attractive form of passive income for owners but comes with risks (e.g., items are not returned) and costs for escrow agents. Similarly, renters have difficulties in anticipating the impact of artworks, e.g., how spectators of NFTs perceive them. To address these challenges, we introduce an NFT rental solution based on a pay-per-like pricing model using blockchain technology, i.e., smart contracts based on the Ethereum chain. We find that blockchain solutions enjoy many advantages also reported for other applications, but interestingly, we also observe dark sides of (large) blockchain fees. Blockchain solutions appear unfair to niche artists and potentially hamper cultural diversity. Furthermore, a trust-cost tradeoff arises to handle fraud caused by manipulation from parties outside the blockchain. All code for the solution is publicly available at: https://github.com/asopi/rental-project
SoK: Pragmatic Assessment of Machine Learning for Network Intrusion Detection
Apr 30, 2023Machine Learning (ML) has become a valuable asset to solve many real-world tasks. For Network Intrusion Detection (NID), however, scientific advances in ML are still seen with skepticism by practitioners. This disconnection is due to the intrinsically limited scope of research papers, many of which primarily aim to demonstrate new methods ``outperforming'' prior work -- oftentimes overlooking the practical implications for deploying the proposed solutions in real systems. Unfortunately, the value of ML for NID depends on a plethora of factors, such as hardware, that are often neglected in scientific literature. This paper aims to reduce the practitioners' skepticism towards ML for NID by "changing" the evaluation methodology adopted in research. After elucidating which "factors" influence the operational deployment of ML in NID, we propose the notion of "pragmatic assessment", which enable practitioners to gauge the real value of ML methods for NID. Then, we show that the state-of-research hardly allows one to estimate the value of ML for NID. As a constructive step forward, we carry out a pragmatic assessment. We re-assess existing ML methods for NID, focusing on the classification of malicious network traffic, and consider: hundreds of configuration settings; diverse adversarial scenarios; and four hardware platforms. Our large and reproducible evaluations enable estimating the quality of ML for NID. We also validate our claims through a user-study with security practitioners.
Efficient and Flexible Topic Modeling using Pretrained Embeddings and Bag of Sentences
Feb 18, 2023Pre-trained language models have led to a new state-of-the-art in many NLP tasks. However, for topic modeling, statistical generative models such as LDA are still prevalent, which do not easily allow incorporating contextual word vectors. They might yield topics that do not align very well with human judgment. In this work, we propose a novel topic modeling and inference algorithm. We suggest a bag of sentences (BoS) approach using sentences as the unit of analysis. We leverage pre-trained sentence embeddings by combining generative process models with clustering. We derive a fast inference algorithm based on expectation maximization, hard assignments, and an annealing process. Our evaluation shows that our method yields state-of-the art results with relatively little computational demands. Our methods is more flexible compared to prior works leveraging word embeddings, since it provides the possibility to customize topic-document distributions using priors. Code is at \url{https://github.com/JohnTailor/BertSenClu}.
A Survey of Deep Learning: From Activations to Transformers
Feb 01, 2023

Deep learning has made tremendous progress in the last decade. A key success factor is the large amount of architectures, layers, objectives, and optimization techniques that have emerged in recent years. They include a myriad of variants related to attention, normalization, skip connection, transformer and self-supervised learning schemes -- to name a few. We provide a comprehensive overview of the most important, recent works in these areas to those who already have a basic understanding of deep learning. We hope that a holistic and unified treatment of influential, recent works helps researchers to form new connections between diverse areas of deep learning.
Foundation models in brief: A historical, socio-technical focus
Dec 17, 2022Foundation models can be disruptive for future AI development by scaling up deep learning in terms of model size and training data's breadth and size. These models achieve state-of-the-art performance (often through further adaptation) on a variety of tasks in domains such as natural language processing and computer vision. Foundational models exhibit a novel {emergent behavior}: {In-context learning} enables users to provide a query and a few examples from which a model derives an answer without being trained on such queries. Additionally, {homogenization} of models might replace a myriad of task-specific models with fewer very large models controlled by few corporations leading to a shift in power and control over AI. This paper provides a short introduction to foundation models. It contributes by crafting a crisp distinction between foundation models and prior deep learning models, providing a history of machine learning leading to foundation models, elaborating more on socio-technical aspects, i.e., organizational issues and end-user interaction, and a discussion of future research.
Concept-based Adversarial Attacks: Tricking Humans and Classifiers Alike
Mar 18, 2022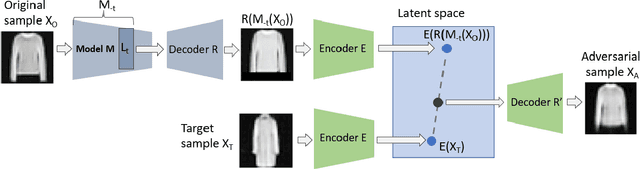
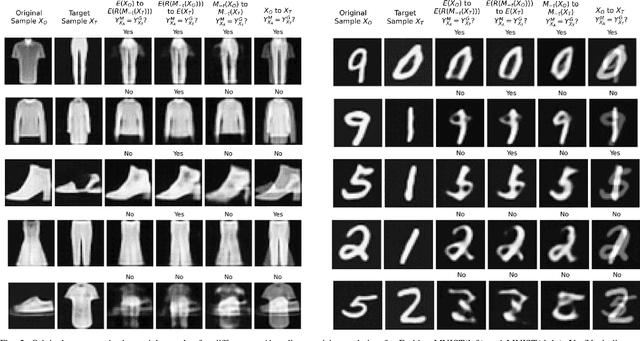
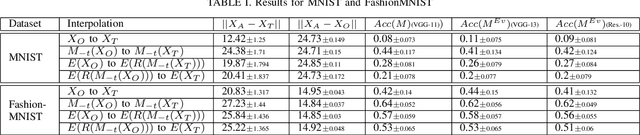
We propose to generate adversarial samples by modifying activations of upper layers encoding semantically meaningful concepts. The original sample is shifted towards a target sample, yielding an adversarial sample, by using the modified activations to reconstruct the original sample. A human might (and possibly should) notice differences between the original and the adversarial sample. Depending on the attacker-provided constraints, an adversarial sample can exhibit subtle differences or appear like a "forged" sample from another class. Our approach and goal are in stark contrast to common attacks involving perturbations of single pixels that are not recognizable by humans. Our approach is relevant in, e.g., multi-stage processing of inputs, where both humans and machines are involved in decision-making because invisible perturbations will not fool a human. Our evaluation focuses on deep neural networks. We also show the transferability of our adversarial examples among networks.
Explaining Classifiers by Constructing Familiar Concepts
Mar 07, 2022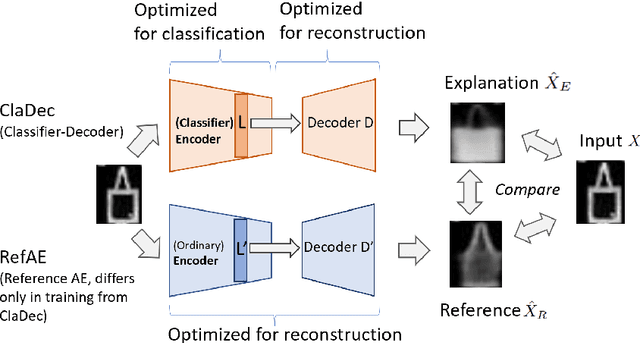
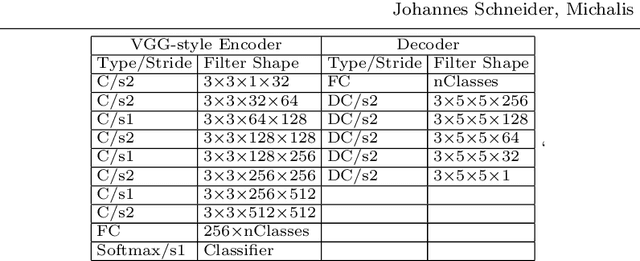
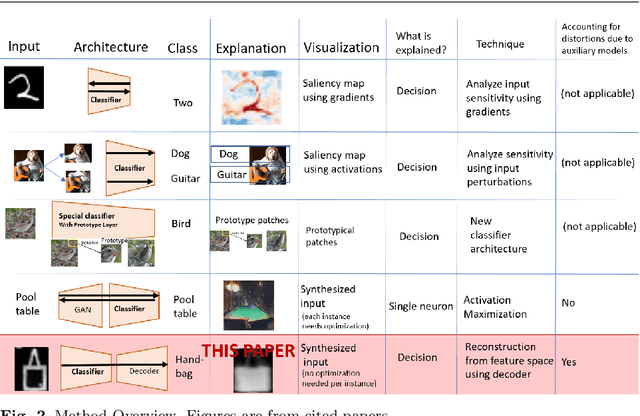
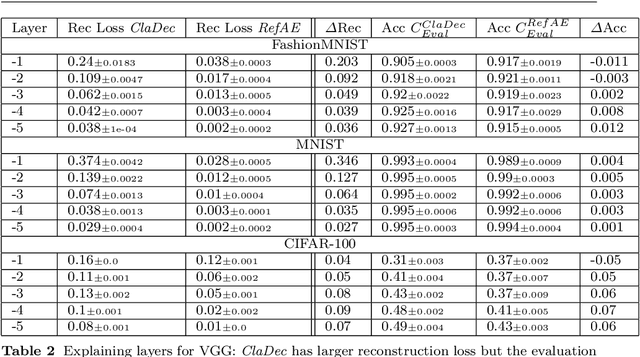
Interpreting a large number of neurons in deep learning is difficult. Our proposed `CLAssifier-DECoder' architecture (ClaDec) facilitates the understanding of the output of an arbitrary layer of neurons or subsets thereof. It uses a decoder that transforms the incomprehensible representation of the given neurons to a representation that is more similar to the domain a human is familiar with. In an image recognition problem, one can recognize what information (or concepts) a layer maintains by contrasting reconstructed images of ClaDec with those of a conventional auto-encoder(AE) serving as reference. An extension of ClaDec allows trading comprehensibility and fidelity. We evaluate our approach for image classification using convolutional neural networks. We show that reconstructed visualizations using encodings from a classifier capture more relevant classification information than conventional AEs. This holds although AEs contain more information on the original input. Our user study highlights that even non-experts can identify a diverse set of concepts contained in images that are relevant (or irrelevant) for the classifier. We also compare against saliency based methods that focus on pixel relevance rather than concepts. We show that ClaDec tends to highlight more relevant input areas to classification though outcomes depend on classifier architecture. Code is at \url{https://github.com/JohnTailor/ClaDec}
The learning phases in NN: From Fitting the Majority to Fitting a Few
Feb 16, 2022The learning dynamics of deep neural networks are subject to controversy. Using the information bottleneck (IB) theory separate fitting and compression phases have been put forward but have since been heavily debated. We approach learning dynamics by analyzing a layer's reconstruction ability of the input and prediction performance based on the evolution of parameters during training. We show that a prototyping phase decreasing reconstruction loss initially, followed by reducing classification loss of a few samples, which increases reconstruction loss, exists under mild assumptions on the data. Aside from providing a mathematical analysis of single layer classification networks, we also assess the behavior using common datasets and architectures from computer vision such as ResNet and VGG.
Towards Trustworthy AutoGrading of Short, Multi-lingual, Multi-type Answers
Jan 02, 2022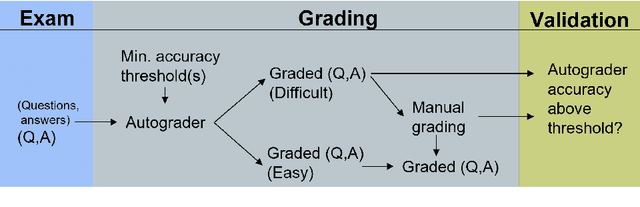
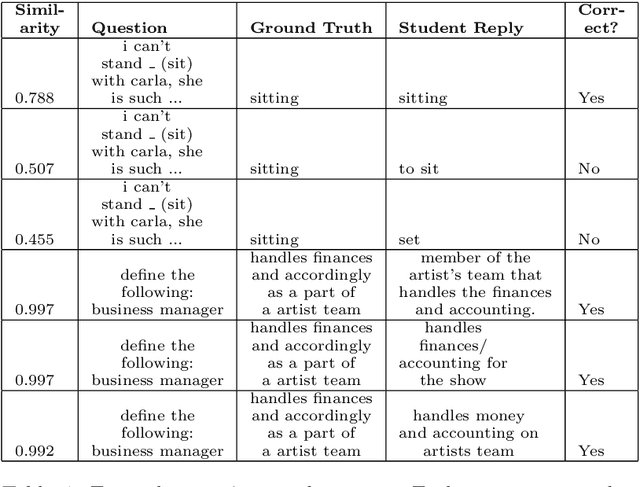
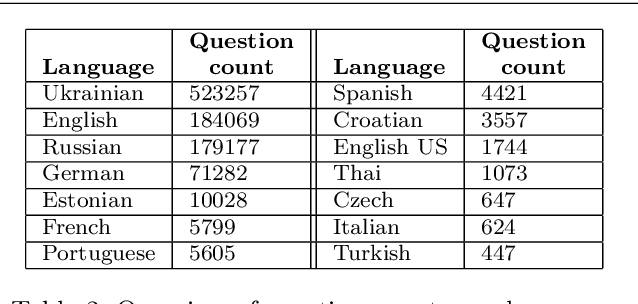
Autograding short textual answers has become much more feasible due to the rise of NLP and the increased availability of question-answer pairs brought about by a shift to online education. Autograding performance is still inferior to human grading. The statistical and black-box nature of state-of-the-art machine learning models makes them untrustworthy, raising ethical concerns and limiting their practical utility. Furthermore, the evaluation of autograding is typically confined to small, monolingual datasets for a specific question type. This study uses a large dataset consisting of about 10 million question-answer pairs from multiple languages covering diverse fields such as math and language, and strong variation in question and answer syntax. We demonstrate the effectiveness of fine-tuning transformer models for autograding for such complex datasets. Our best hyperparameter-tuned model yields an accuracy of about 86.5\%, comparable to the state-of-the-art models that are less general and more tuned to a specific type of question, subject, and language. More importantly, we address trust and ethical concerns. By involving humans in the autograding process, we show how to improve the accuracy of automatically graded answers, achieving accuracy equivalent to that of teaching assistants. We also show how teachers can effectively control the type of errors made by the system and how they can validate efficiently that the autograder's performance on individual exams is close to the expected performance.
Domain Transformer: Predicting Samples of Unseen, Future Domains
Jun 10, 2021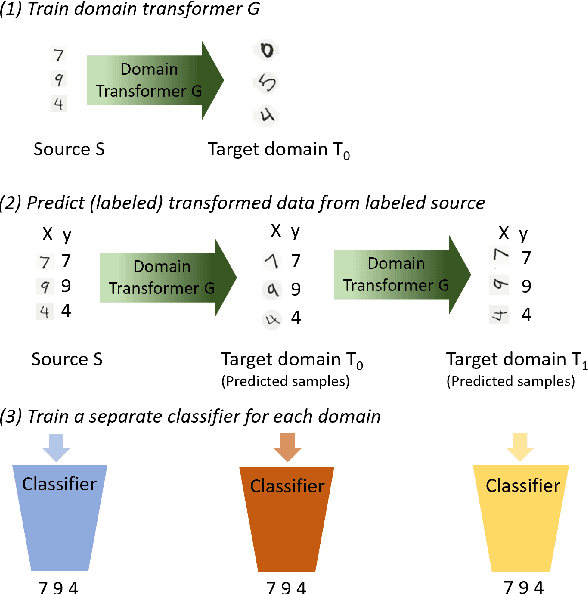
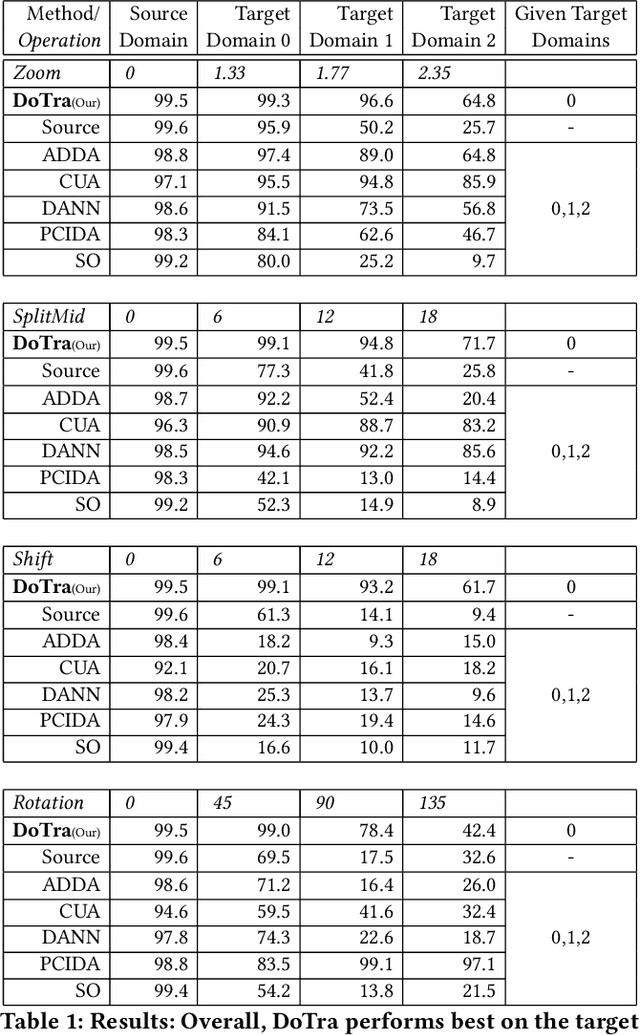
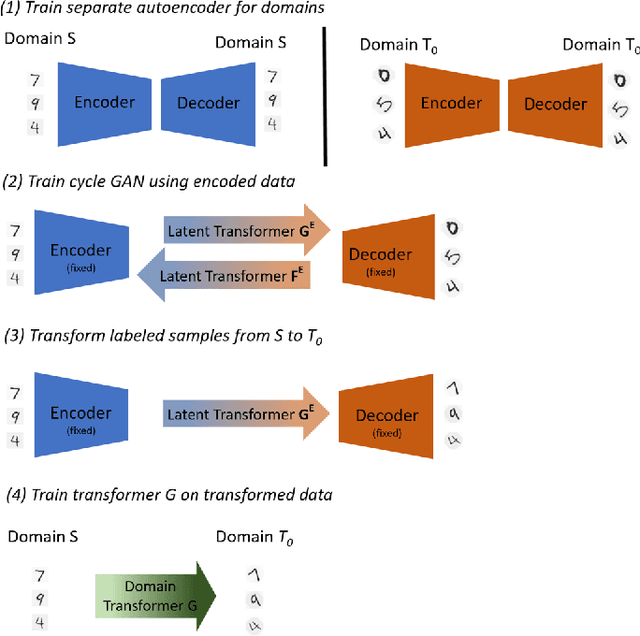

The data distribution commonly evolves over time leading to problems such as concept drift that often decrease classifier performance. We seek to predict unseen data (and their labels) allowing us to tackle challenges due to a non-constant data distribution in a \emph{proactive} manner rather than detecting and reacting to already existing changes that might already have led to errors. To this end, we learn a domain transformer in an unsupervised manner that allows generating data of unseen domains. Our approach first matches independently learned latent representations of two given domains obtained from an auto-encoder using a Cycle-GAN. In turn, a transformation of the original samples can be learned that can be applied iteratively to extrapolate to unseen domains. Our evaluation on CNNs on image data confirms the usefulness of the approach. It also achieves very good results on the well-known problem of unsupervised domain adaption, where labels but not samples have to be predicted.