 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUseful Compact Representations for Data-Fitting
Mar 18, 2024For minimization problems without 2nd derivative information, methods that estimate Hessian matrices can be very effective. However, conventional techniques generate dense matrices that are prohibitive for large problems. Limited-memory compact representations express the dense arrays in terms of a low rank representation and have become the state-of-the-art for software implementations on large deterministic problems. We develop new compact representations that are parameterized by a choice of vectors and that reduce to existing well known formulas for special choices. We demonstrate effectiveness of the compact representations for large eigenvalue computations, tensor factorizations and nonlinear regressions.
Nonlinear Least Squares for Large-Scale Machine Learning using Stochastic Jacobian Estimates
Jul 12, 2021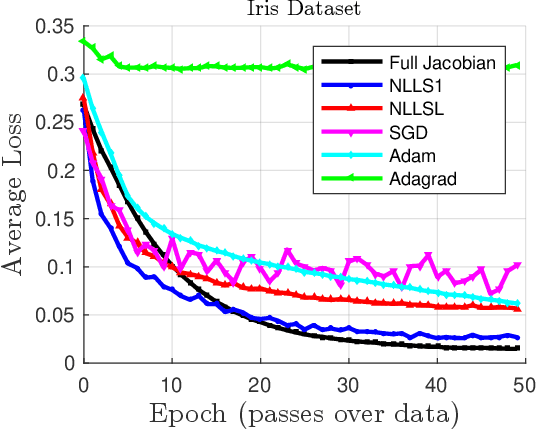
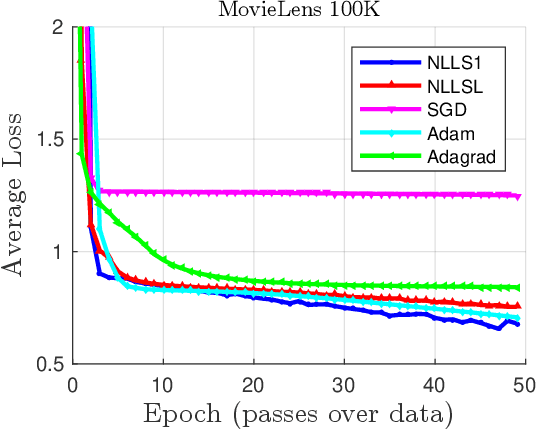
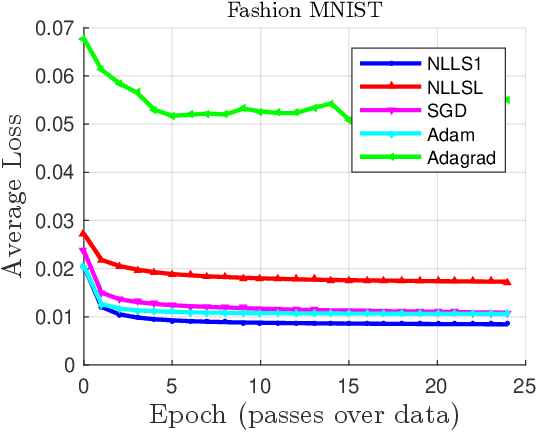
For large nonlinear least squares loss functions in machine learning we exploit the property that the number of model parameters typically exceeds the data in one batch. This implies a low-rank structure in the Hessian of the loss, which enables effective means to compute search directions. Using this property, we develop two algorithms that estimate Jacobian matrices and perform well when compared to state-of-the-art methods.