 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVec2Summ: Text Summarization via Probabilistic Sentence Embeddings
Aug 09, 2025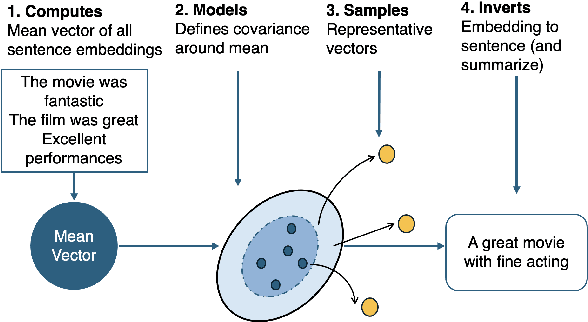
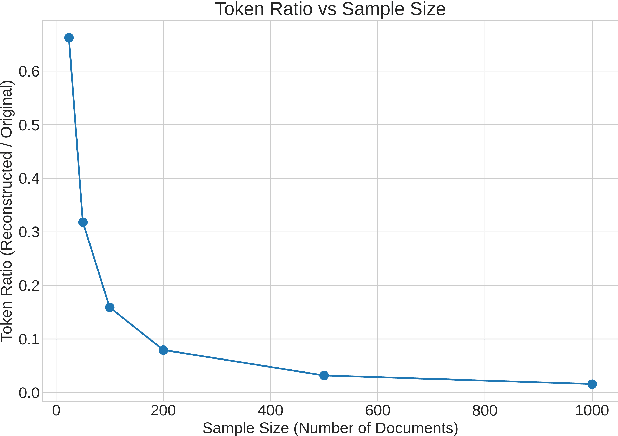
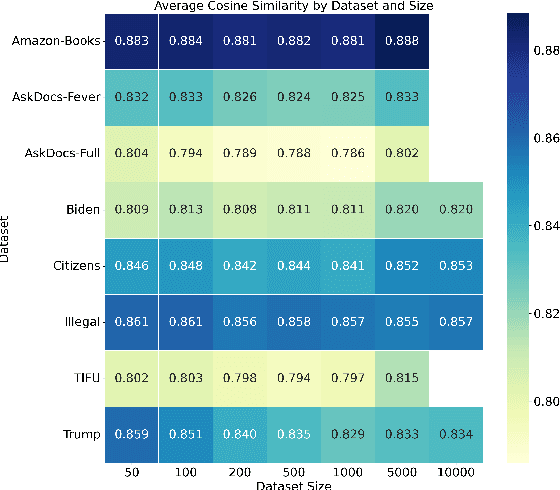
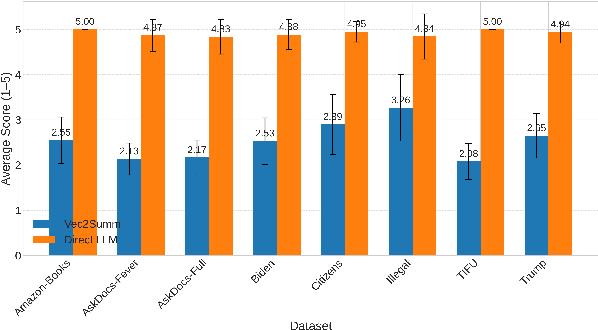
We propose Vec2Summ, a novel method for abstractive summarization that frames the task as semantic compression. Vec2Summ represents a document collection using a single mean vector in the semantic embedding space, capturing the central meaning of the corpus. To reconstruct fluent summaries, we perform embedding inversion -- decoding this mean vector into natural language using a generative language model. To improve reconstruction quality and capture some degree of topical variability, we introduce stochasticity by sampling from a Gaussian distribution centered on the mean. This approach is loosely analogous to bagging in ensemble learning, where controlled randomness encourages more robust and varied outputs. Vec2Summ addresses key limitations of LLM-based summarization methods. It avoids context-length constraints, enables interpretable and controllable generation via semantic parameters, and scales efficiently with corpus size -- requiring only $O(d + d^2)$ parameters. Empirical results show that Vec2Summ produces coherent summaries for topically focused, order-invariant corpora, with performance comparable to direct LLM summarization in terms of thematic coverage and efficiency, albeit with less fine-grained detail. These results underscore Vec2Summ's potential in settings where scalability, semantic control, and corpus-level abstraction are prioritized.
FastLexRank: Efficient Lexical Ranking for Structuring Social Media Posts
Oct 02, 2024



We present FastLexRank\footnote{https://github.com/LiMaoUM/FastLexRank}, an efficient and scalable implementation of the LexRank algorithm for text ranking. Designed to address the computational and memory complexities of the original LexRank method, FastLexRank significantly reduces time and memory requirements from $\mathcal{O}(n^2)$ to $\mathcal{O}(n)$ without compromising the quality or accuracy of the results. By employing an optimized approach to calculating the stationary distribution of sentence graphs, FastLexRank maintains an identical results with the original LexRank scores while enhancing computational efficiency. This paper details the algorithmic improvements that enable the processing of large datasets, such as social media corpora, in real-time. Empirical results demonstrate its effectiveness, and we propose its use in identifying central tweets, which can be further analyzed using advanced NLP techniques. FastLexRank offers a scalable solution for text centrality calculation, addressing the growing need for efficient processing of digital content.