 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Cultural Awareness in LLMs: A Case Study of Cross-Culture Aesthetic Stylistics
May 26, 2026Large Language Models (LLMs) are increasingly deployed in diverse cultural contexts, yet their ability to master aesthetic stylistics, i.e., the strategic use of language to evoke cultural resonance, remains underexplored. We curate C4STYLI, a benchmark of highly stylized translated movie titles and advertising slogans from Hong Kong and the Chinese Mainland, to evaluate LLMs via the lens of behavioral recognition and productive competence. Extensive evaluations show that LLMs differ from humans in stylistic recognition, and this recognition ability varies across text domains. In addition, stylistic recognition and generation performance in LLMs are not consistently aligned. To further examine whether LLMs genuinely capture stylistic information in stylistic recognition, we conduct structural ablation with logistic regression probes. We find that, in the Hong Kong setting, stylistic recognition in LLMs relies primarily on surface-level linguistic information rather than stylistic structure. This suggests limited sensitivity to Hong Kong-specific stylistic structure.
Foresight Optimization for Strategic Reasoning in Large Language Models
Apr 16, 2026Reasoning capabilities in large language models (LLMs) have generally advanced significantly. However, it is still challenging for existing reasoning-based LLMs to perform effective decision-making abilities in multi-agent environments, due to the absence of explicit foresight modeling. To this end, strategic reasoning, the most fundamental capability to anticipate the counterpart's behaviors and foresee its possible future actions, has been introduced to alleviate the above issues. Strategic reasoning is fundamental to effective decision-making in multi-agent environments, yet existing reasoning enhancement methods for LLMs do not explicitly capture its foresight nature. In this work, we introduce Foresight Policy Optimization (FoPO) to enhance strategic reasoning in LLMs, which integrates opponent modeling principles into policy optimization, thereby enabling explicit consideration of both self-interest and counterpart influence. Specifically, we construct two curated datasets, namely Cooperative RSA and Competitive Taboo, equipped with well-designed rules and moderate difficulty to facilitate a systematic investigation of FoPO in a self-play framework. Our experiments demonstrate that FoPO significantly enhances strategic reasoning across LLMs of varying sizes and origins. Moreover, models trained with FoPO exhibit strong generalization to out-of-domain strategic scenarios, substantially outperforming standard LLM reasoning optimization baselines.
Epistemic considerations when AI answers questions for us
Apr 23, 2023
In this position paper, we argue that careless reliance on AI to answer our questions and to judge our output is a violation of Grice's Maxim of Quality as well as a violation of Lemoine's legal Maxim of Innocence, performing an (unwarranted) authority fallacy, and while lacking assessment signals, committing Type II errors that result from fallacies of the inverse. What is missing in the focus on output and results of AI-generated and AI-evaluated content is, apart from paying proper tribute, the demand to follow a person's thought process (or a machine's decision processes). In deliberately avoiding Neural Networks that cannot explain how they come to their conclusions, we introduce logic-symbolic inference to handle any possible epistemics any human or artificial information processor may have. Our system can deal with various belief systems and shows how decisions may differ for what is true, false, realistic, unrealistic, literal, or anomalous. As is, stota AI such as ChatGPT is a sorcerer's apprentice.
The Media Inequality, Uncanny Mountain, and the Singularity is Far from Near: Iwaa and Sophia Robot versus a Real Human Being
Mar 16, 2023Design of Artificial Intelligence and robotics habitually assumes that adding more humanlike features improves the user experience, mainly kept in check by suspicion of uncanny effects. Three strands of theorizing are brought together for the first time and empirically put to the test: Media Equation (and in its wake, Computers Are Social Actors), Uncanny Valley theory, and as an extreme of human-likeness assumptions, the Singularity. We measured the user experience of real-life visitors of a number of seminars who were checked in either by Smart Dynamics' Iwaa, Hanson's Sophia robot, Sophia's on-screen avatar, or a human assistant. Results showed that human-likeness was not in appearance or behavior but in attributed qualities of being alive. Media Equation, Singularity, and Uncanny hypotheses were not confirmed. We discuss the imprecision in theorizing about human-likeness and rather opt for machines that 'function adequately.'
Robot Affect: the Amygdala as Bloch Sphere
Dec 02, 2019

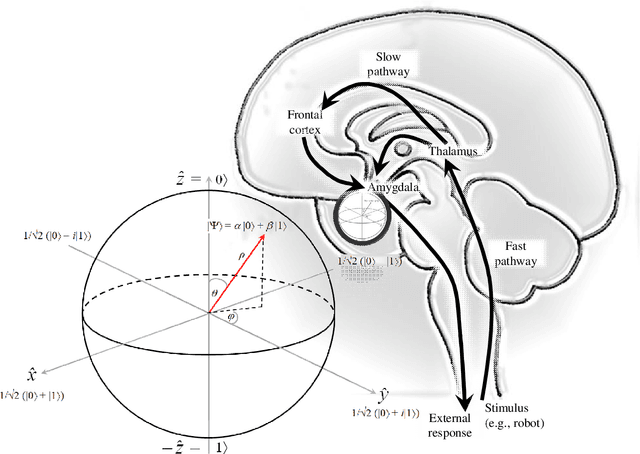

In the design of artificially sentient robots, an obstacle always has been that conventional computers cannot really process information in parallel, whereas the human affective system is capable of producing experiences of emotional concurrency (e.g., happy and sad). Another schism that has been in the way is the persistent Cartesian divide between cognition and affect, whereas people easily can reflect on their emotions or have feelings about a thought. As an essentially theoretical exercise, we posit that quantum physics at the basis of neurology explains observations in cognitive emotion psychology from the belief that the construct of reality is partially imagined (Im) in the complex coordinate space C^3. We propose a quantum computational account to mixed states of reflection and affect, while transforming known psychological dimensions into the actual quantum dynamics of electromotive forces. As a precursor to actual simulations, we show examples of possible robot behaviors, using Einstein-Podolsky-Rosen circuits. Keywords: emotion, reflection, modelling, quantum computing
A robot's sense-making of fallacies and rhetorical tropes. Creating ontologies of what humans try to say
Jun 24, 2019



In the design of user-friendly robots, human communication should be understood by the system beyond mere logics and literal meaning. Robot communication-design has long ignored the importance of communication and politeness rules that are 'forgiving' and 'suspending disbelief' and cannot handle the basically metaphorical way humans design their utterances. Through analysis of the psychological causes of illogical and non-literal statements, signal detection, fundamental attribution errors, and anthropomorphism, we developed a fail-safe protocol for fallacies and tropes that makes use of Frege's distinction between reference and sense, Beth's tableau analytics, Grice's maxim of quality, and epistemic considerations to have the robot politely make sense of a user's sometimes unintelligible demands. Keywords: social robots, logical fallacies, metaphors, reference, sense, maxim of quality, tableau reasoning, epistemics of the virtual