 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Large Language Model Errors Arise from Hallucinating Critical Problem Features
May 17, 2025Large language models have recently made great strides in reasoning task performance through chain-of-thought (CoT) strategies trained via reinforcement learning; however, these "reasoning large language models" (RLLMs) remain imperfect reasoners, and understanding the frequencies and causes of their failure modes is important for both users and developers. We test o1-mini, o3-mini, DeepSeek-R1, Claude 3.7 Sonnet, Gemini 2.5 Pro Preview, and Grok 3 Mini Beta on graph coloring as a variable-complexity constraint-satisfaction logic problem, and find evidence from both error rate comparisons and CoT/explanation text analysis that RLLMs are prone to hallucinate edges not specified in the prompt's description of the graph. This phenomenon persists across multiple problem complexity levels and semantic frames, and it appears to account for a significant fraction of the incorrect answers from every tested model, and the vast majority of them for some models. Our results indicate that RLLMs may possess broader issues with misrepresentation of problem specifics, and we offer suggestions for design choices to mitigate this weakness.
Evaluating the Systematic Reasoning Abilities of Large Language Models through Graph Coloring
Feb 10, 2025Contemporary large language models are powerful problem-solving tools, but they exhibit weaknesses in their reasoning abilities which ongoing research seeks to mitigate. We investigate graph coloring as a means of evaluating an LLM's capacities for systematic step-by-step reasoning and possibility space exploration, as well as effects of semantic problem framing. We test Claude 3.5 Sonnet, Llama 3.1 405B, Gemini 1.5 Pro, GPT-4o, o1-mini, and DeepSeek-R1 on a dataset of $k$-coloring problems with $2 \leq k \leq 4$ and vertex count $4 \leq n \leq 8$, using partial algorithmic solvers to further categorize problems by difficulty. In addition to substantial but varying framing effects, we find that all models except o1-mini and R1 exhibit $>60\%$ error rates on difficult problem types in all frames ($>15\%$ for o1-mini and $>10\%$ for R1), and no model achieves perfect accuracy even in the simple domain of 2-coloring 4-vertex graphs. Our results highlight both the considerable recent progress in LLM systematic reasoning and the limits of its reliability, especially in relation to increasing computational costs. We expect that more complex graph coloring problems, and procedural generation of arbitrary-complexity reasoning problems more broadly, offer further untapped potential for LLM benchmarking.
What's the Opposite of a Face? Finding Shared Decodable Concepts and their Negations in the Brain
May 27, 2024



Prior work has offered evidence for functional localization in the brain; different anatomical regions preferentially activate for certain types of visual input. For example, the fusiform face area preferentially activates for visual stimuli that include a face. However, the spectrum of visual semantics is extensive, and only a few semantically-tuned patches of cortex have so far been identified in the human brain. Using a multimodal (natural language and image) neural network architecture (CLIP) we train a highly accurate contrastive model that maps brain responses during naturalistic image viewing to CLIP embeddings. We then use a novel adaptation of the DBSCAN clustering algorithm to cluster the parameters of these participant-specific contrastive models. This reveals what we call Shared Decodable Concepts (SDCs): clusters in CLIP space that are decodable from common sets of voxels across multiple participants. Examining the images most and least associated with each SDC cluster gives us additional insight into the semantic properties of each SDC. We note SDCs for previously reported visual features (e.g. orientation tuning in early visual cortex) as well as visual semantic concepts such as faces, places and bodies. In cases where our method finds multiple clusters for a visuo-semantic concept, the least associated images allow us to dissociate between confounding factors. For example, we discovered two clusters of food images, one driven by color, the other by shape. We also uncover previously unreported areas such as regions of extrastriate body area (EBA) tuned for legs/hands and sensitivity to numerosity in right intraparietal sulcus, and more. Thus, our contrastive-learning methodology better characterizes new and existing visuo-semantic representations in the brain by leveraging multimodal neural network representations and a novel adaptation of clustering algorithms.
Correcting Biased Centered Kernel Alignment Measures in Biological and Artificial Neural Networks
May 02, 2024



Centred Kernel Alignment (CKA) has recently emerged as a popular metric to compare activations from biological and artificial neural networks (ANNs) in order to quantify the alignment between internal representations derived from stimuli sets (e.g. images, text, video) that are presented to both systems. In this paper we highlight issues that the community should take into account if using CKA as an alignment metric with neural data. Neural data are in the low-data high-dimensionality domain, which is one of the cases where (biased) CKA results in high similarity scores even for pairs of random matrices. Using fMRI and MEG data from the THINGS project, we show that if biased CKA is applied to representations of different sizes in the low-data high-dimensionality domain, they are not directly comparable due to biased CKA's sensitivity to differing feature-sample ratios and not stimuli-driven responses. This situation can arise both when comparing a pre-selected area of interest (e.g. ROI) to multiple ANN layers, as well as when determining to which ANN layer multiple regions of interest (ROIs) / sensor groups of different dimensionality are most similar. We show that biased CKA can be artificially driven to its maximum value when using independent random data of different sample-feature ratios. We further show that shuffling sample-feature pairs of real neural data does not drastically alter biased CKA similarity in comparison to unshuffled data, indicating an undesirable lack of sensitivity to stimuli-driven neural responses. Positive alignment of true stimuli-driven responses is only achieved by using debiased CKA. Lastly, we report findings that suggest biased CKA is sensitive to the inherent structure of neural data, only differing from shuffled data when debiased CKA detects stimuli-driven alignment.
Identifying Shared Decodable Concepts in the Human Brain Using Image-Language Foundation Models
Jun 06, 2023



We introduce a method that takes advantage of high-quality pretrained multimodal representations to explore fine-grained semantic networks in the human brain. Previous studies have documented evidence of functional localization in the brain, with different anatomical regions preferentially activating for different types of sensory input. Many such localized structures are known, including the fusiform face area and parahippocampal place area. This raises the question of whether additional brain regions (or conjunctions of brain regions) are also specialized for other important semantic concepts. To identify such brain regions, we developed a data-driven approach to uncover visual concepts that are decodable from a massive functional magnetic resonance imaging (fMRI) dataset. Our analysis is broadly split into three sections. First, a fully connected neural network is trained to map brain responses to the outputs of an image-language foundation model, CLIP (Radford et al., 2021). Subsequently, a contrastive-learning dimensionality reduction method reveals the brain-decodable components of CLIP space. In the final section of our analysis, we localize shared decodable concepts in the brain using a voxel-masking optimization method to produce a shared decodable concept (SDC) space. The accuracy of our procedure is validated by comparing it to previous localization experiments that identify regions for faces, bodies, and places. In addition to these concepts, whose corresponding brain regions were already known, we localize novel concept representations which are shared across participants to other areas of the human brain. We also demonstrate how this method can be used to inspect fine-grained semantic networks for individual participants. We envisage that this extensible method can also be adapted to explore other questions at the intersection of AI and neuroscience.
Improving the Accuracy and Robustness of CNNs Using a Deep CCA Neural Data Regularizer
Sep 06, 2022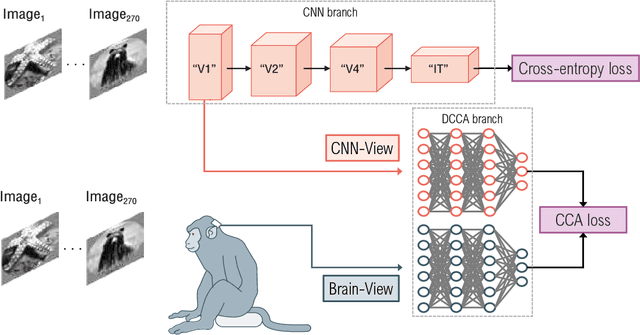
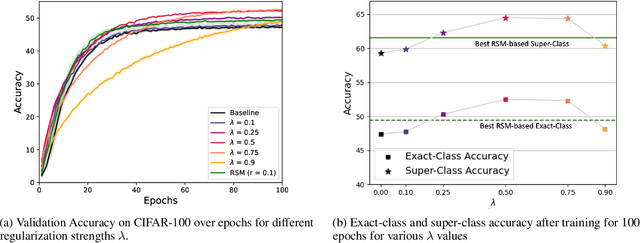
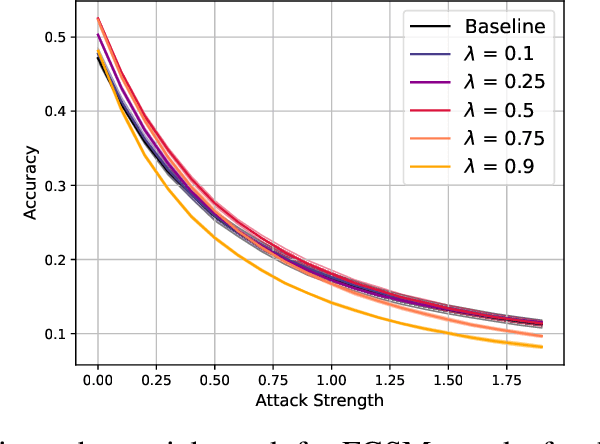
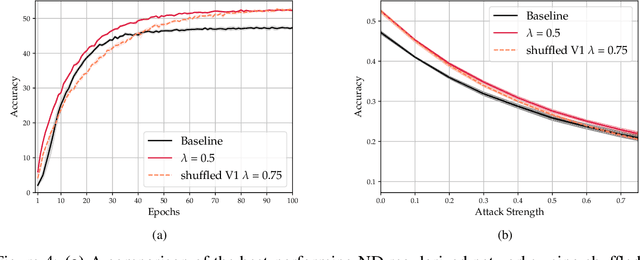
As convolutional neural networks (CNNs) become more accurate at object recognition, their representations become more similar to the primate visual system. This finding has inspired us and other researchers to ask if the implication also runs the other way: If CNN representations become more brain-like, does the network become more accurate? Previous attempts to address this question showed very modest gains in accuracy, owing in part to limitations of the regularization method. To overcome these limitations, we developed a new neural data regularizer for CNNs that uses Deep Canonical Correlation Analysis (DCCA) to optimize the resemblance of the CNN's image representations to that of the monkey visual cortex. Using this new neural data regularizer, we see much larger performance gains in both classification accuracy and within-super-class accuracy, as compared to the previous state-of-the-art neural data regularizers. These networks are also more robust to adversarial attacks than their unregularized counterparts. Together, these results confirm that neural data regularization can push CNN performance higher, and introduces a new method that obtains a larger performance boost.
Different Spectral Representations in Optimized Artificial Neural Networks and Brains
Aug 22, 2022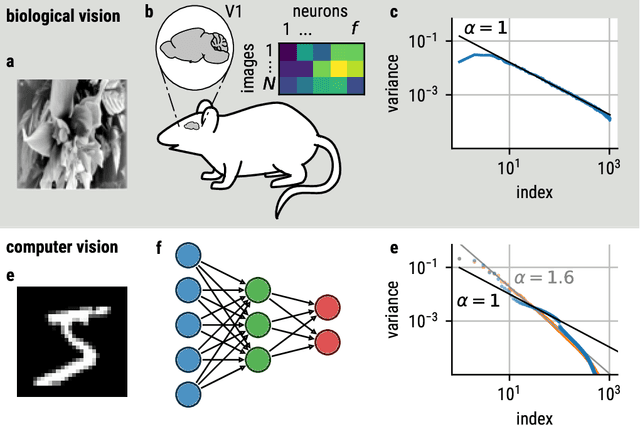
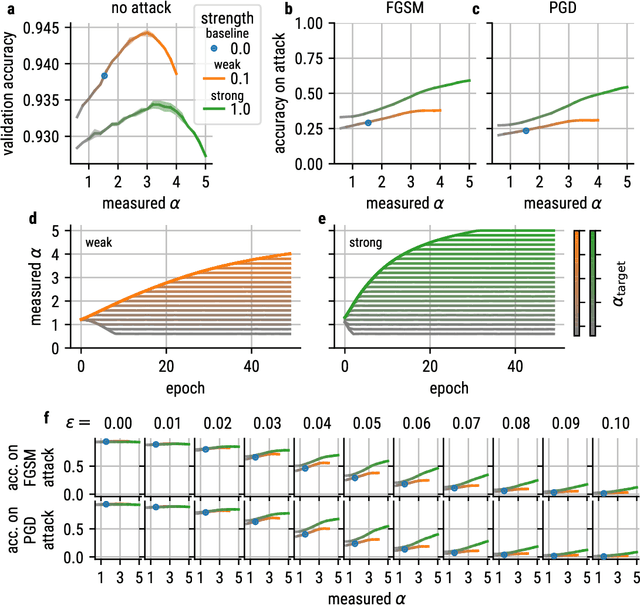
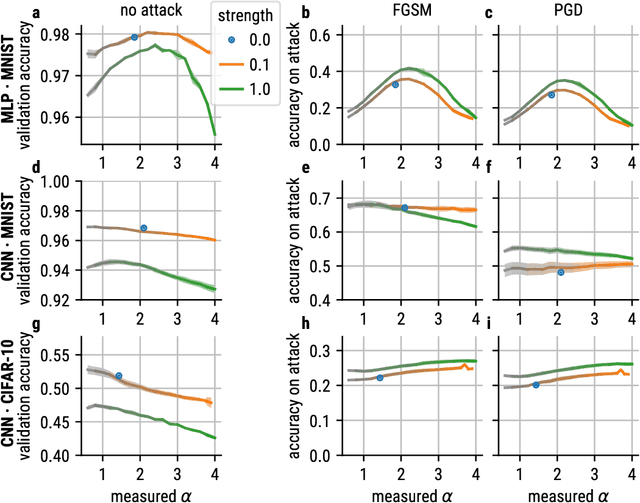
Recent studies suggest that artificial neural networks (ANNs) that match the spectral properties of the mammalian visual cortex -- namely, the $\sim 1/n$ eigenspectrum of the covariance matrix of neural activities -- achieve higher object recognition performance and robustness to adversarial attacks than those that do not. To our knowledge, however, no previous work systematically explored how modifying the ANN's spectral properties affects performance. To fill this gap, we performed a systematic search over spectral regularizers, forcing the ANN's eigenspectrum to follow $1/n^\alpha$ power laws with different exponents $\alpha$. We found that larger powers (around 2--3) lead to better validation accuracy and more robustness to adversarial attacks on dense networks. This surprising finding applied to both shallow and deep networks and it overturns the notion that the brain-like spectrum (corresponding to $\alpha \sim 1$) always optimizes ANN performance and/or robustness. For convolutional networks, the best $\alpha$ values depend on the task complexity and evaluation metric: lower $\alpha$ values optimized validation accuracy and robustness to adversarial attack for networks performing a simple object recognition task (categorizing MNIST images of handwritten digits); for a more complex task (categorizing CIFAR-10 natural images), we found that lower $\alpha$ values optimized validation accuracy whereas higher $\alpha$ values optimized adversarial robustness. These results have two main implications. First, they cast doubt on the notion that brain-like spectral properties ($\alpha \sim 1$) \emph{always} optimize ANN performance. Second, they demonstrate the potential for fine-tuned spectral regularizers to optimize a chosen design metric, i.e., accuracy and/or robustness.
Training neural networks to have brain-like representations improves object recognition performance
May 25, 2019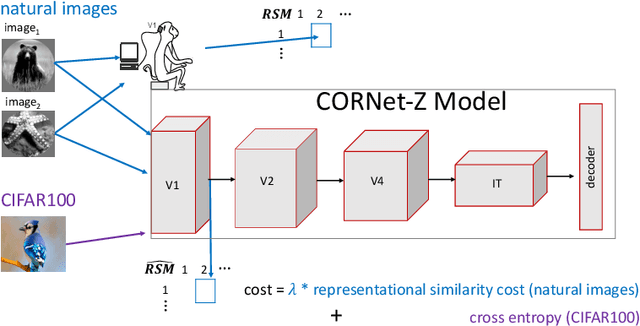
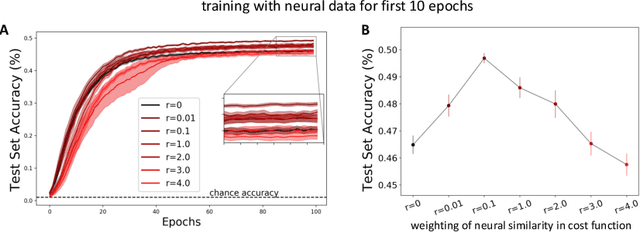
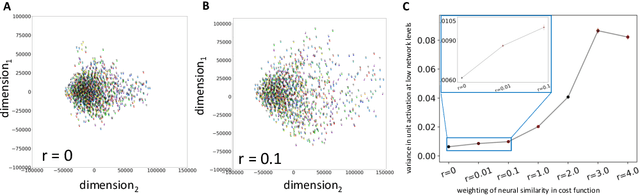
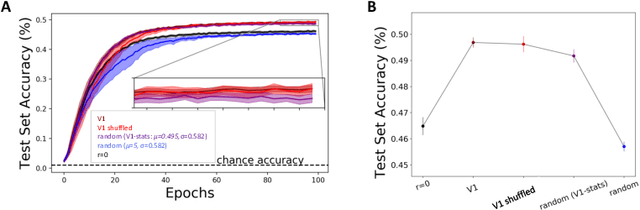
The current state-of-the-art object recognition algorithms, deep convolutional neural networks (DCNNs), are inspired by the architecture of the mammalian visual system [8], and capable of human-level performance on many tasks [15]. However, even these algorithms make errors. As DCNNs improve at object recognition tasks, they develop representations in their hidden layers that become more similar to those observed in the mammalian brains [24]. This led us to hypothesize that teaching DCNNs to achieve even more brain-like representations could improve their performance. To test this, we trained DCNNs on a composite task, wherein networks were trained to: a) classify images of objects; while b) having intermediate representations that resemble those observed in neural recordings from monkey visual cortex. Compared with DCNNs trained purely for object categorization, DCNNs trained on the composite task had better object recognition performance. Our results outline a new way to regularize object recognition networks, using transfer learning strategies in which the brain serves as a teacher for training DCNNs.
Using deep learning to reveal the neural code for images in primary visual cortex
Jun 19, 2017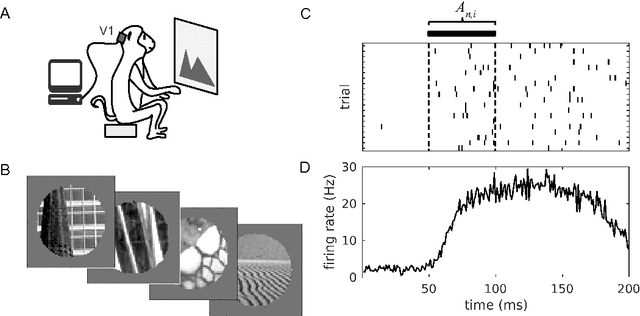
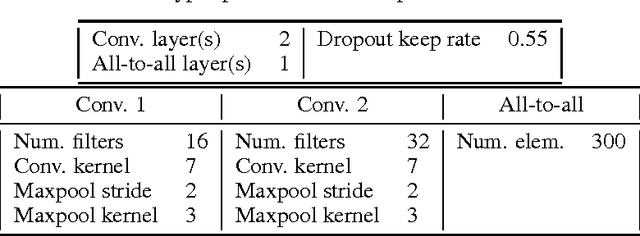
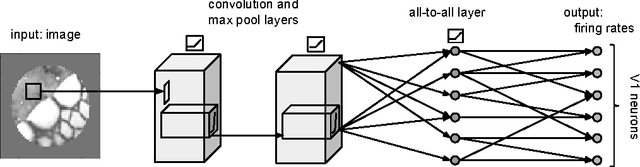
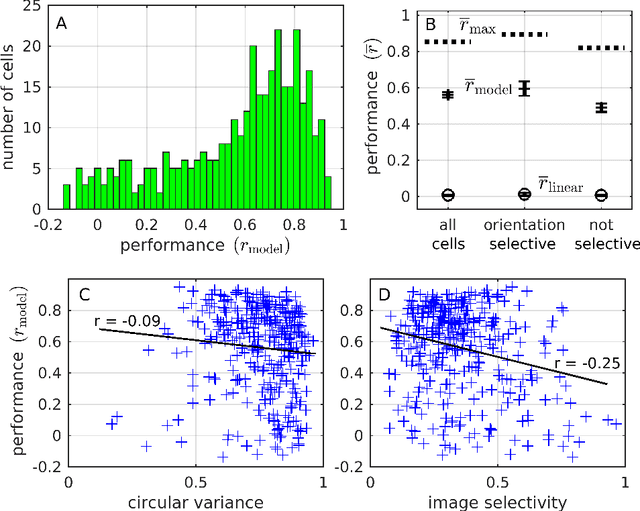
Primary visual cortex (V1) is the first stage of cortical image processing, and a major effort in systems neuroscience is devoted to understanding how it encodes information about visual stimuli. Within V1, many neurons respond selectively to edges of a given preferred orientation: these are known as simple or complex cells, and they are well-studied. Other neurons respond to localized center-surround image features. Still others respond selectively to certain image stimuli, but the specific features that excite them are unknown. Moreover, even for the simple and complex cells-- the best-understood V1 neurons-- it is challenging to predict how they will respond to natural image stimuli. Thus, there are important gaps in our understanding of how V1 encodes images. To fill this gap, we train deep convolutional neural networks to predict the firing rates of V1 neurons in response to natural image stimuli, and find that 15% of these neurons are within 10% of their theoretical limit of predictability. For these well predicted neurons, we invert the predictor network to identify the image features (receptive fields) that cause the V1 neurons to spike. In addition to those with previously-characterized receptive fields (Gabor wavelet and center-surround), we identify neurons that respond predictably to higher-level textural image features that are not localized to any particular region of the image.