 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning on images using a string-distance
May 17, 2013

We present a new method for image feature-extraction which is based on representing an image by a finite-dimensional vector of distances that measure how different the image is from a set of image prototypes. We use the recently introduced Universal Image Distance (UID) \cite{RatsabyChesterIEEE2012} to compare the similarity between an image and a prototype image. The advantage in using the UID is the fact that no domain knowledge nor any image analysis need to be done. Each image is represented by a finite dimensional feature vector whose components are the UID values between the image and a finite set of image prototypes from each of the feature categories. The method is automatic since once the user selects the prototype images, the feature vectors are automatically calculated without the need to do any image analysis. The prototype images can be of different size, in particular, different than the image size. Based on a collection of such cases any supervised or unsupervised learning algorithm can be used to train and produce an image classifier or image cluster analysis. In this paper we present the image feature-extraction method and use it on several supervised and unsupervised learning experiments for satellite image data.
How random are a learner's mistakes?
Jan 02, 2011Given a random binary sequence $X^{(n)}$ of random variables, $X_{t},$ $t=1,2,...,n$, for instance, one that is generated by a Markov source (teacher) of order $k^{*}$ (each state represented by $k^{*}$ bits). Assume that the probability of the event $X_{t}=1$ is constant and denote it by $\beta$. Consider a learner which is based on a parametric model, for instance a Markov model of order $k$, who trains on a sequence $x^{(m)}$ which is randomly drawn by the teacher. Test the learner's performance by giving it a sequence $x^{(n)}$ (generated by the teacher) and check its predictions on every bit of $x^{(n)}.$ An error occurs at time $t$ if the learner's prediction $Y_{t}$ differs from the true bit value $X_{t}$. Denote by $\xi^{(n)}$ the sequence of errors where the error bit $\xi_{t}$ at time $t$ equals 1 or 0 according to whether the event of an error occurs or not, respectively. Consider the subsequence $\xi^{(\nu)}$ of $\xi^{(n)}$ which corresponds to the errors of predicting a 0, i.e., $\xi^{(\nu)}$ consists of the bits of $\xi^{(n)}$ only at times $t$ such that $Y_{t}=0.$ In this paper we compute an estimate on the deviation of the frequency of 1s of $\xi^{(\nu)}$ from $\beta$. The result shows that the level of randomness of $\xi^{(\nu)}$ decreases relative to an increase in the complexity of the learner.
Descriptive-complexity based distance for fuzzy sets
Dec 15, 2010
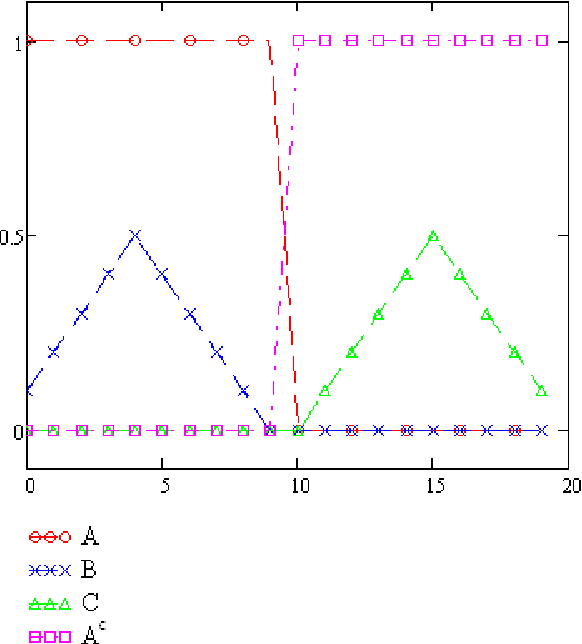
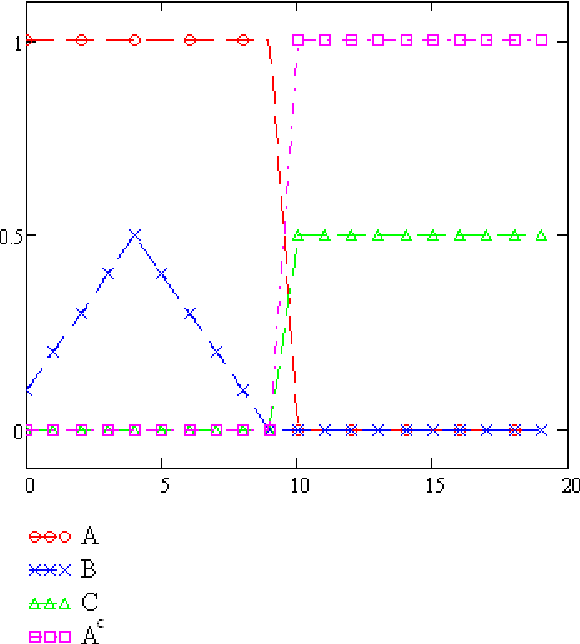
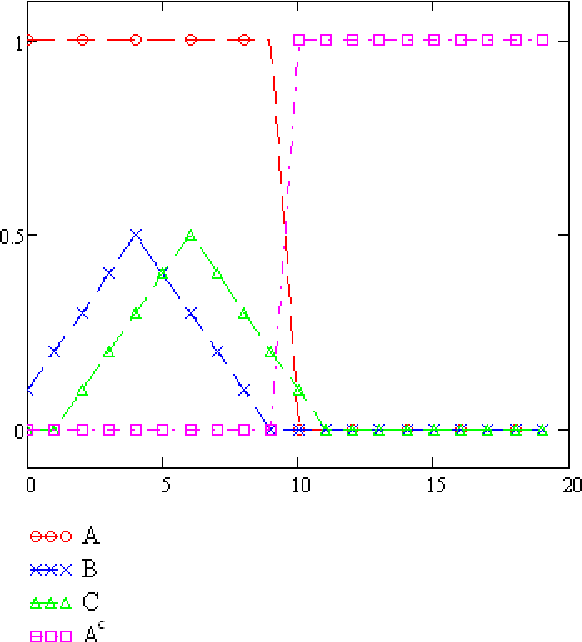
A new distance function dist(A,B) for fuzzy sets A and B is introduced. It is based on the descriptive complexity, i.e., the number of bits (on average) that are needed to describe an element in the symmetric difference of the two sets. The distance gives the amount of additional information needed to describe any one of the two sets given the other. We prove its mathematical properties and perform pattern clustering on data based on this distance.
Random scattering of bits by prediction
Oct 13, 2010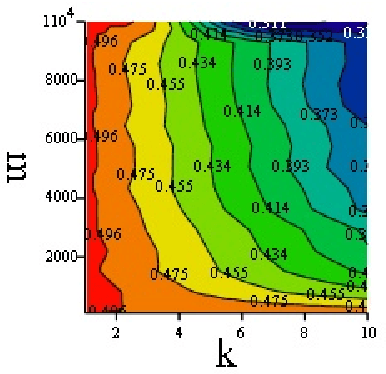
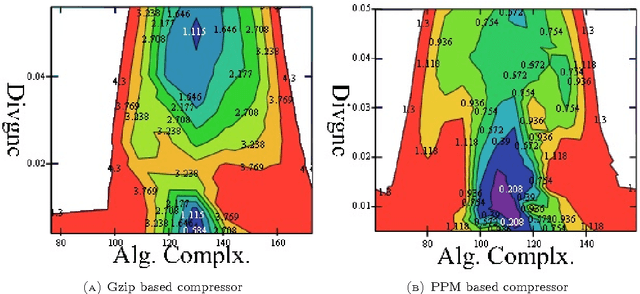
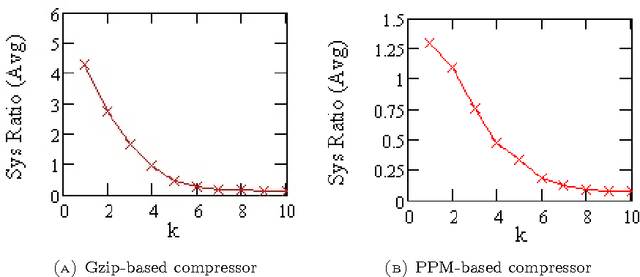
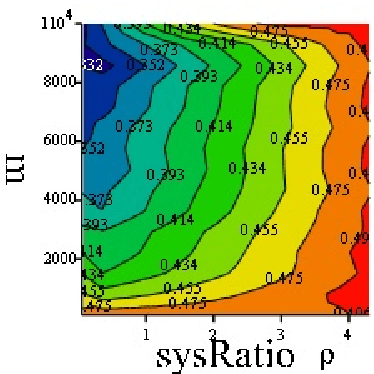
We investigate a population of binary mistake sequences that result from learning with parametric models of different order. We obtain estimates of their error, algorithmic complexity and divergence from a purely random Bernoulli sequence. We study the relationship of these variables to the learner's information density parameter which is defined as the ratio between the lengths of the compressed to uncompressed files that contain the learner's decision rule. The results indicate that good learners have a low information density$\rho$ while bad learners have a high $\rho$. Bad learners generate mistake sequences that are atypically complex or diverge stochastically from a purely random Bernoulli sequence. Good learners generate typically complex sequences with low divergence from Bernoulli sequences and they include mistake sequences generated by the Bayes optimal predictor. Based on the static algorithmic interference model of \cite{Ratsaby_entropy} the learner here acts as a static structure which "scatters" the bits of an input sequence (to be predicted) in proportion to its information density $\rho$ thereby deforming its randomness characteristics.
Prediction by Compression
Aug 30, 2010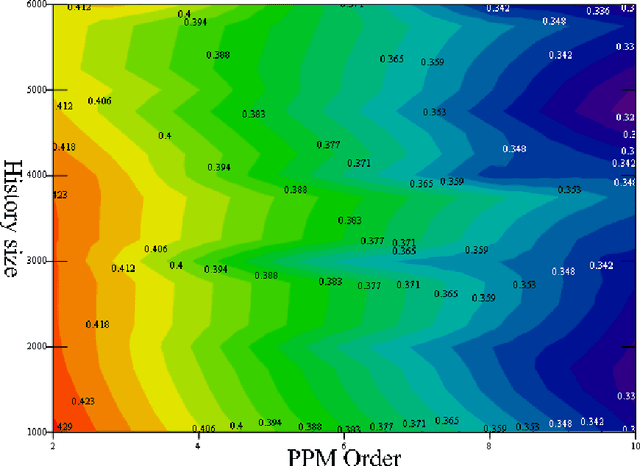
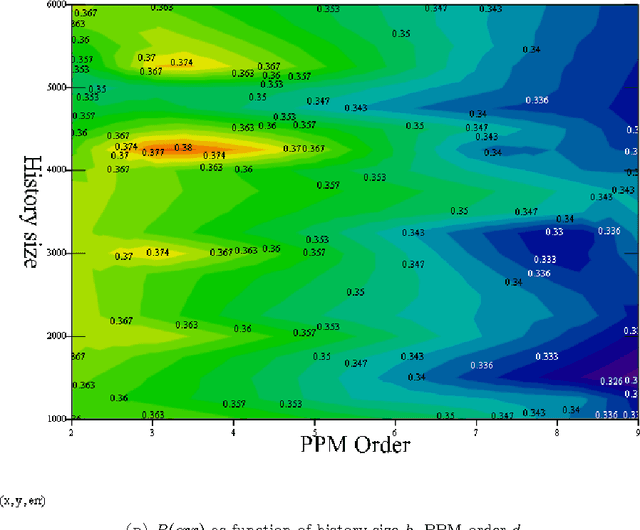
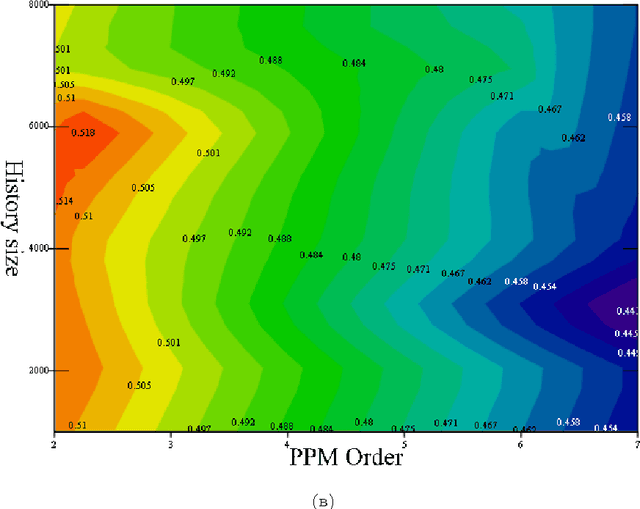
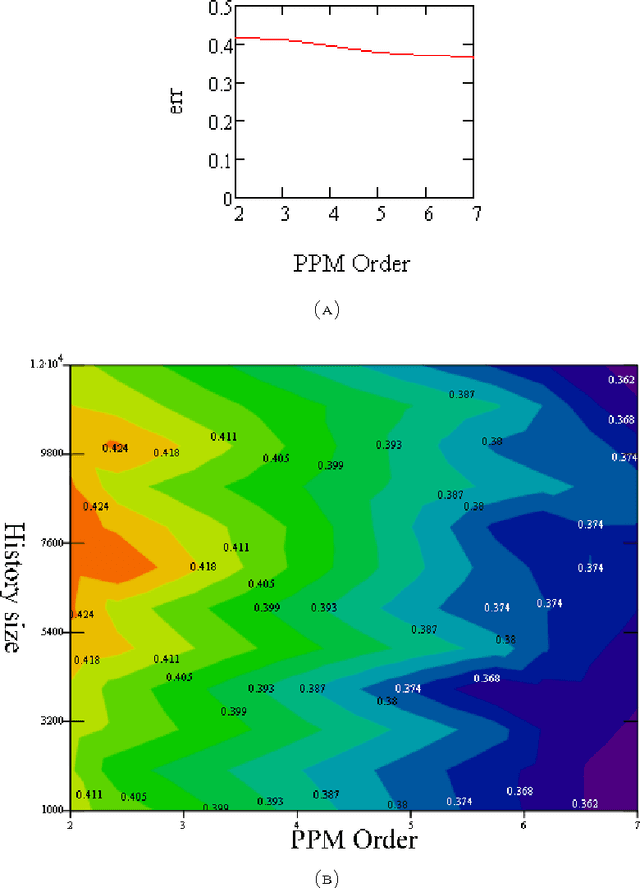
It is well known that text compression can be achieved by predicting the next symbol in the stream of text data based on the history seen up to the current symbol. The better the prediction the more skewed the conditional probability distribution of the next symbol and the shorter the codeword that needs to be assigned to represent this next symbol. What about the opposite direction ? suppose we have a black box that can compress text stream. Can it be used to predict the next symbol in the stream ? We introduce a criterion based on the length of the compressed data and use it to predict the next symbol. We examine empirically the prediction error rate and its dependency on some compression parameters.
Information Width
Jul 01, 2008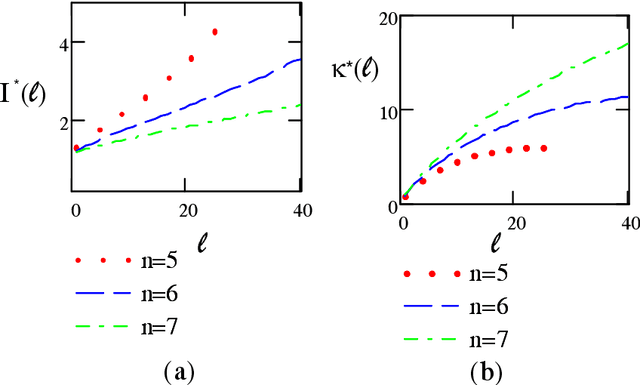
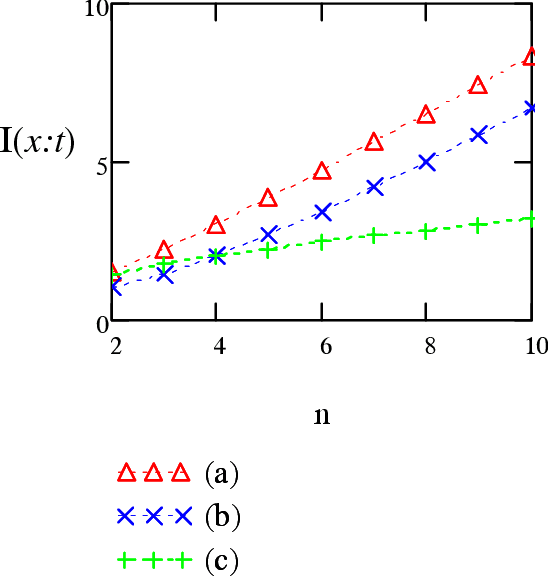
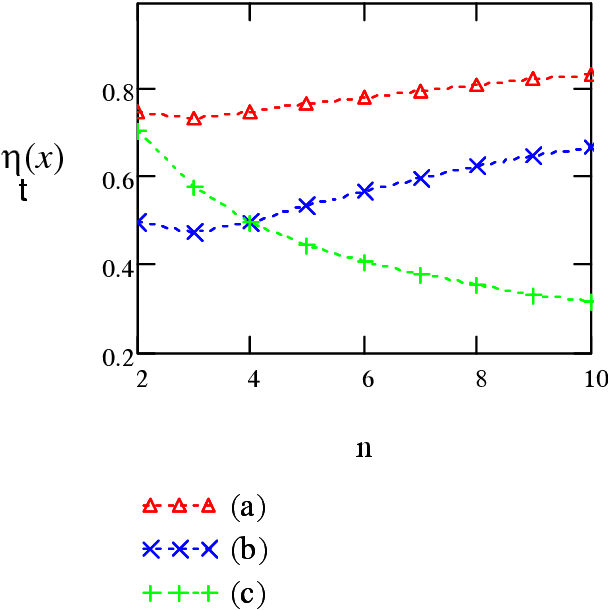
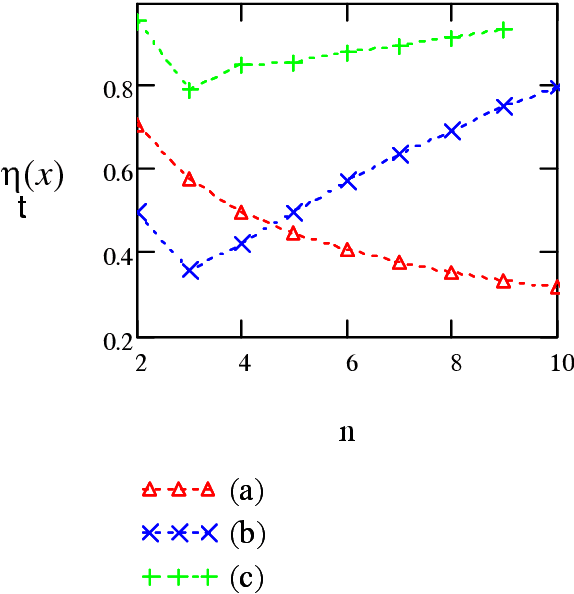
Kolmogorov argued that the concept of information exists also in problems with no underlying stochastic model (as Shannon's information representation) for instance, the information contained in an algorithm or in the genome. He introduced a combinatorial notion of entropy and information $I(x:\sy)$ conveyed by a binary string $x$ about the unknown value of a variable $\sy$. The current paper poses the following questions: what is the relationship between the information conveyed by $x$ about $\sy$ to the description complexity of $x$ ? is there a notion of cost of information ? are there limits on how efficient $x$ conveys information ? To answer these questions Kolmogorov's definition is extended and a new concept termed {\em information width} which is similar to $n$-widths in approximation theory is introduced. Information of any input source, e.g., sample-based, general side-information or a hybrid of both can be evaluated by a single common formula. An application to the space of binary functions is considered.
On the Complexity of Binary Samples
Jan 30, 2008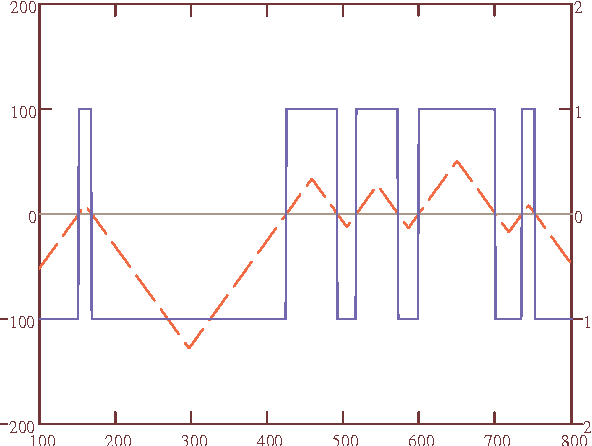
Consider a class $\mH$ of binary functions $h: X\to\{-1, +1\}$ on a finite interval $X=[0, B]\subset \Real$. Define the {\em sample width} of $h$ on a finite subset (a sample) $S\subset X$ as $\w_S(h) \equiv \min_{x\in S} |\w_h(x)|$, where $\w_h(x) = h(x) \max\{a\geq 0: h(z)=h(x), x-a\leq z\leq x+a\}$. Let $\mathbb{S}_\ell$ be the space of all samples in $X$ of cardinality $\ell$ and consider sets of wide samples, i.e., {\em hypersets} which are defined as $A_{\beta, h} = \{S\in \mathbb{S}_\ell: \w_{S}(h) \geq \beta\}$. Through an application of the Sauer-Shelah result on the density of sets an upper estimate is obtained on the growth function (or trace) of the class $\{A_{\beta, h}: h\in\mH\}$, $\beta>0$, i.e., on the number of possible dichotomies obtained by intersecting all hypersets with a fixed collection of samples $S\in\mathbb{S}_\ell$ of cardinality $m$. The estimate is $2\sum_{i=0}^{2\lfloor B/(2\beta)\rfloor}{m-\ell\choose i}$.