 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA flow-based IDS using Machine Learning in eBPF
Feb 19, 2021
eBPF is a new technology which allows dynamically loading pieces of code into the Linux kernel. It can greatly speed up networking since it enables the kernel to process certain packets without the involvement of a userspace program. So far eBPF has been used for simple packet filtering applications such as firewalls or Denial of Service protection. We show that it is possible to develop a flow based network intrusion detection system based on machine learning entirely in eBPF. Our solution uses a decision tree and decides for each packet whether it is malicious or not, considering the entire previous context of the network flow. We achieve a performance increase of over 20\% compared to the same solution implemented as a userspace program.
LFQ: Online Learning of Per-flow Queuing Policies using Deep Reinforcement Learning
Jul 08, 2020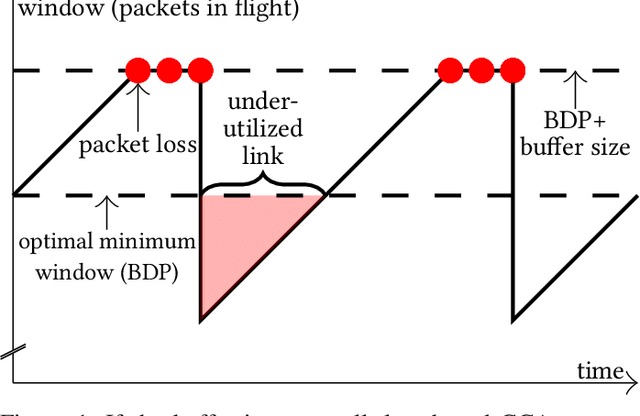
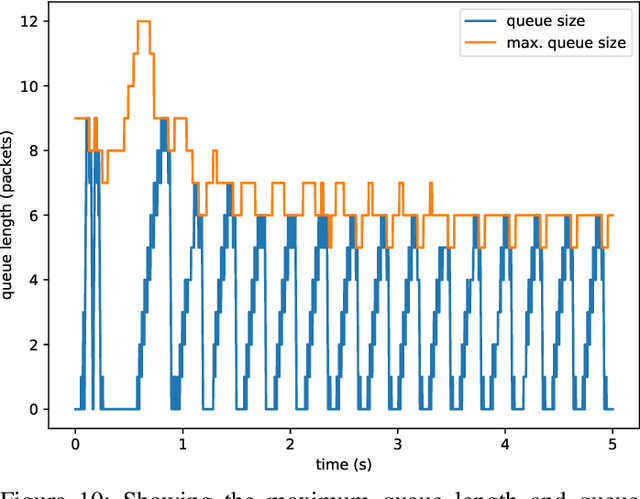
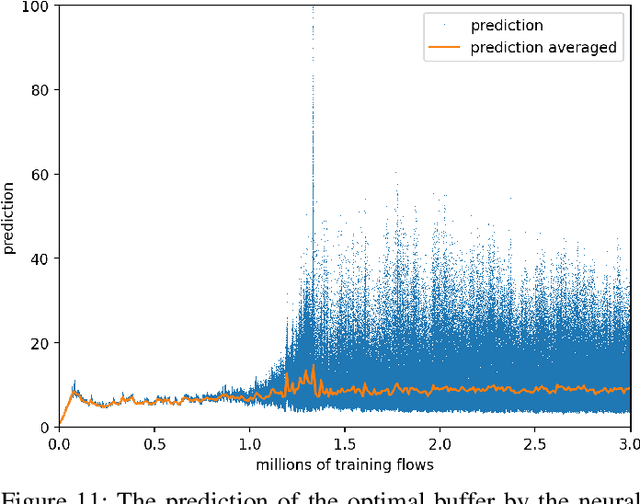
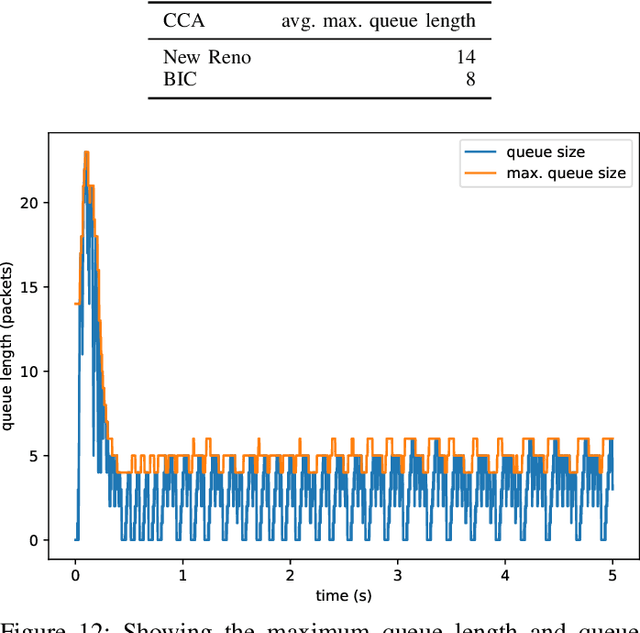
The increasing number of different, incompatible congestion control algorithms has led to an increased deployment of fair queuing. Fair queuing isolates each network flow and can thus guarantee fairness for each flow even if the flows' congestion controls are not inherently fair. So far, each queue in the fair queuing system either has a fixed, static maximum size or is managed by an Active Queue Management (AQM) algorithm like CoDel. In this paper we design an AQM mechanism (Learning Fair Qdisc (LFQ)) that dynamically learns the optimal buffer size for each flow according to a specified reward function online. We show that our Deep Learning based algorithm can dynamically assign the optimal queue size to each flow depending on its congestion control, delay and bandwidth. Comparing to competing fair AQM schedulers, it provides significantly smaller queues while achieving the same or higher throughput.
SparseIDS: Learning Packet Sampling with Reinforcement Learning
Feb 10, 2020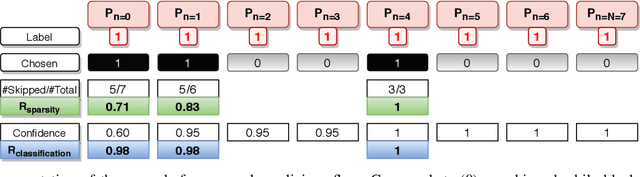
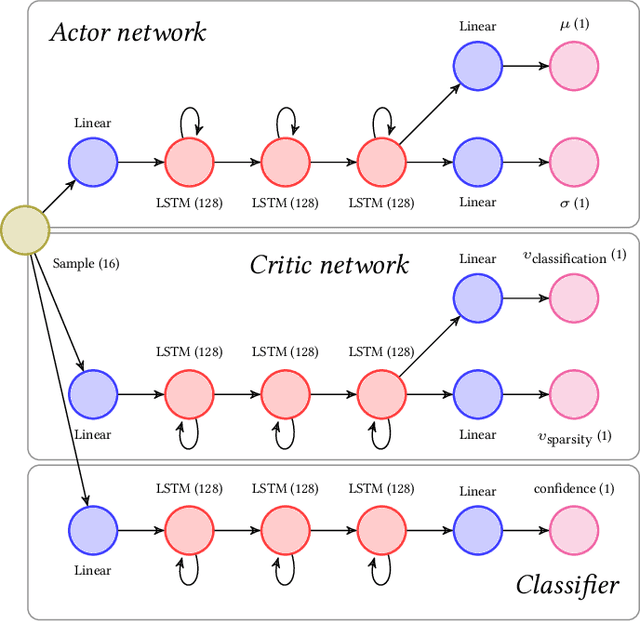
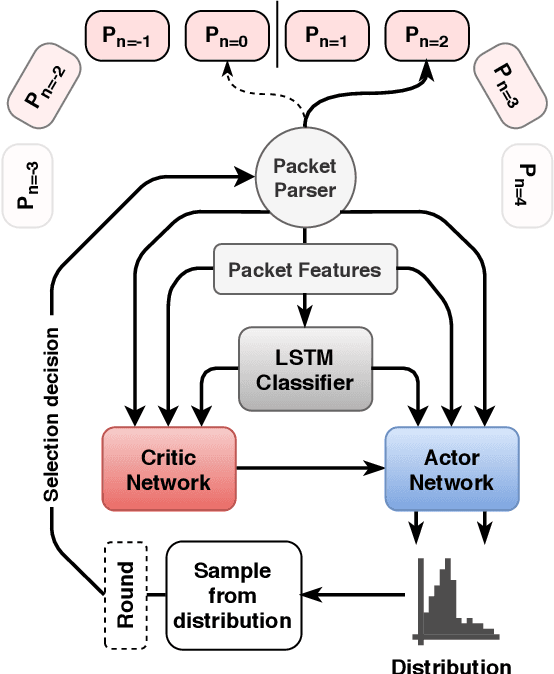
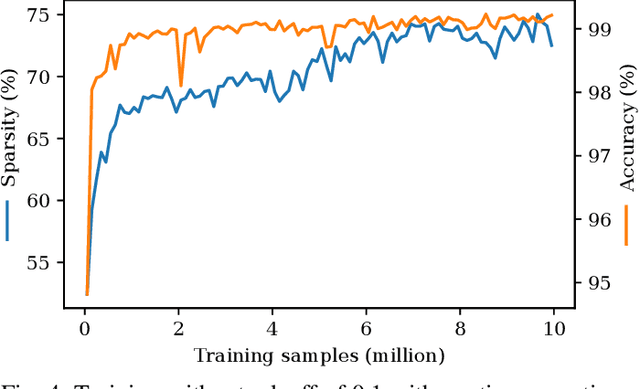
Recurrent Neural Networks (RNNs) have been shown to be valuable for constructing Intrusion Detection Systems (IDSs) for network data. They allow determining if a flow is malicious or not already before it is over, making it possible to take action immediately. However, considering the large number of packets that have to be inspected, the question of computational efficiency arises. We show that by using a novel Reinforcement Learning (RL)-based approach called SparseIDS, we can reduce the number of consumed packets by more than three fourths while keeping classification accuracy high. Comparing to various other sampling techniques, SparseIDS consistently achieves higher classification accuracy by learning to sample only relevant packets. A major novelty of our RL-based approach is that it can not only skip up to a predefined maximum number of samples like other approaches proposed in the domain of Natural Language Processing but can even skip arbitrarily many packets in one step. This enables saving even more computational resources for long sequences. Inspecting SparseIDS's behavior of choosing packets shows that it adopts different sampling strategies for different attack types and network flows. Finally we build an automatic steering mechanism that can guide SparseIDS in deployment to achieve a desired level of sparsity.
Explainability and Adversarial Robustness for RNNs
Dec 20, 2019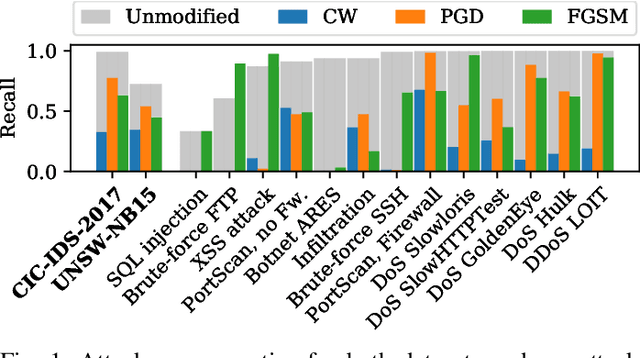
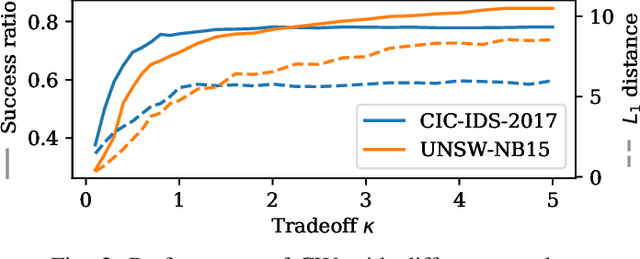
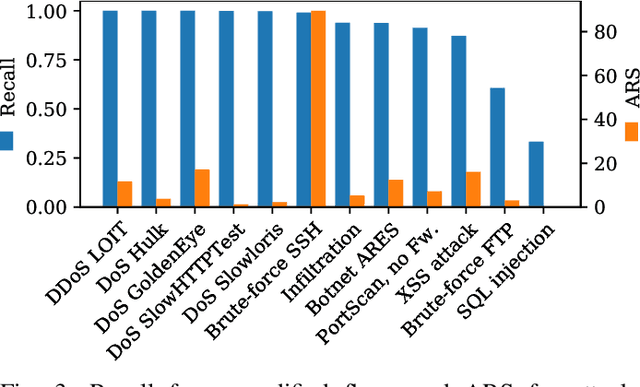
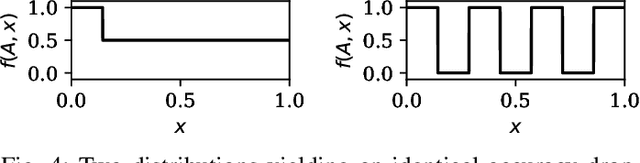
Recurrent Neural Networks (RNNs) yield attractive properties for constructing Intrusion Detection Systems (IDSs) for network data. With the rise of ubiquitous Machine Learning (ML) systems, malicious actors have been catching up quickly to find new ways to exploit ML vulnerabilities for profit. Recently developed adversarial ML techniques focus on computer vision and their applicability to network traffic is not straightforward: Network packets expose fewer features than an image, are sequential and impose several constraints on their features. We show that despite these completely different characteristics, adversarial samples can be generated reliably for RNNs. To understand a classifier's potential for misclassification, we extend existing explainability techniques and propose new ones, suitable particularly for sequential data. Applying them shows that already the first packets of a communication flow are of crucial importance and are likely to be targeted by attackers. Feature importance methods show that even relatively unimportant features can be effectively abused to generate adversarial samples. Since traditional evaluation metrics such as accuracy are not sufficient for quantifying the adversarial threat, we propose the Adversarial Robustness Score (ARS) for comparing IDSs, capturing a common notion of adversarial robustness, and show that an adversarial training procedure can significantly and successfully reduce the attack surface.
Walling up Backdoors in Intrusion Detection Systems
Oct 17, 2019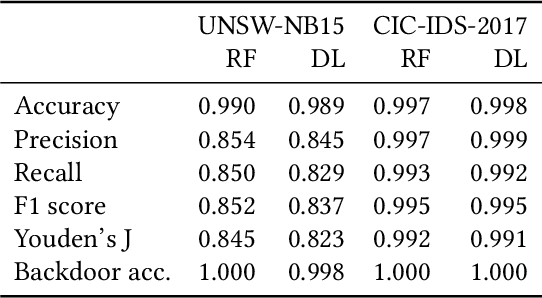
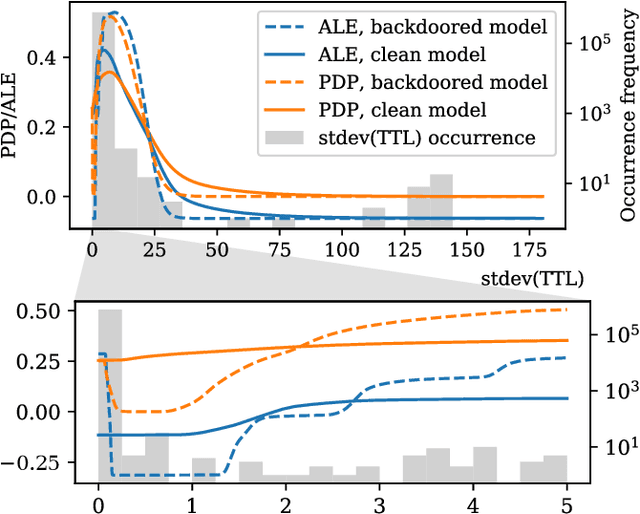
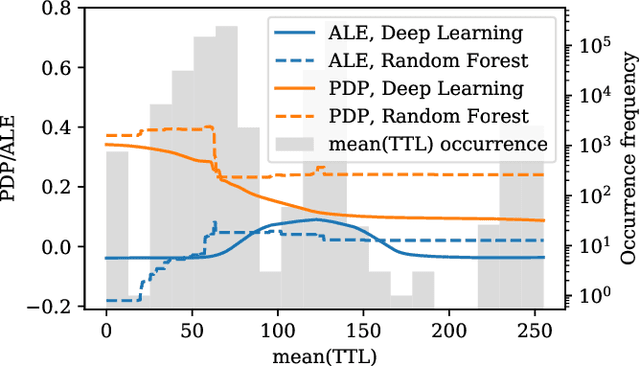
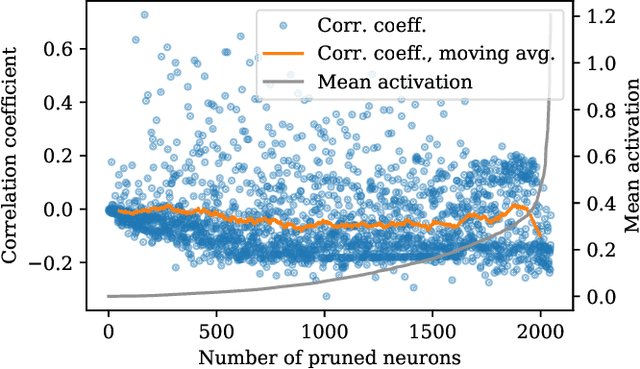
Interest in poisoning attacks and backdoors recently resurfaced for Deep Learning (DL) applications. Several successful defense mechanisms have been recently proposed for Convolutional Neural Networks (CNNs), for example in the context of autonomous driving. We show that visualization approaches can aid in identifying a backdoor independent of the used classifier. Surprisingly, we find that common defense mechanisms fail utterly to remove backdoors in DL for Intrusion Detection Systems (IDSs). Finally, we devise pruning-based approaches to remove backdoors for Decision Trees (DTs) and Random Forests (RFs) and demonstrate their effectiveness for two different network security datasets.