 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Attribute: Improving the Performance of LLMs Attribution Systems
May 19, 2025



Large Language Models (LLMs) are increasingly applied in various science domains, yet their broader adoption remains constrained by a critical challenge: the lack of trustworthy, verifiable outputs. Current LLMs often generate answers without reliable source attribution, or worse, with incorrect attributions, posing a barrier to their use in scientific and high-stakes settings, where traceability and accountability are non-negotiable. To be reliable, attribution systems need high accuracy and retrieve data with short lengths, i.e., attribute to a sentence within a document rather than a whole document. We propose a sentence-level pre-attribution step for Retrieve-Augmented Generation (RAG) systems that classify sentences into three categories: not attributable, attributable to a single quote, and attributable to multiple quotes. By separating sentences before attribution, a proper attribution method can be selected for the type of sentence, or the attribution can be skipped altogether. Our results indicate that classifiers are well-suited for this task. In this work, we propose a pre-attribution step to reduce the computational complexity of attribution, provide a clean version of the HAGRID dataset, and provide an end-to-end attribution system that works out of the box.
Embedding Domain-Specific Knowledge from LLMs into the Feature Engineering Pipeline
Mar 27, 2025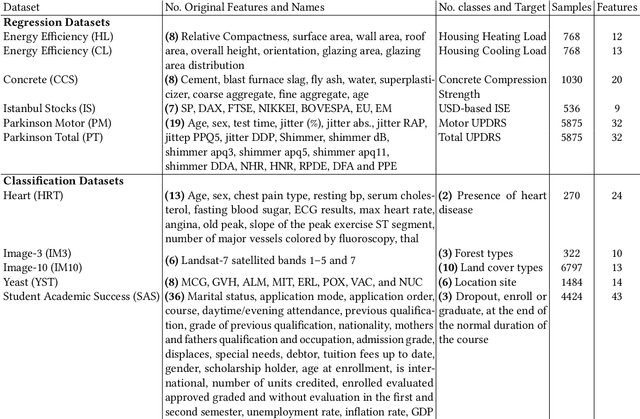
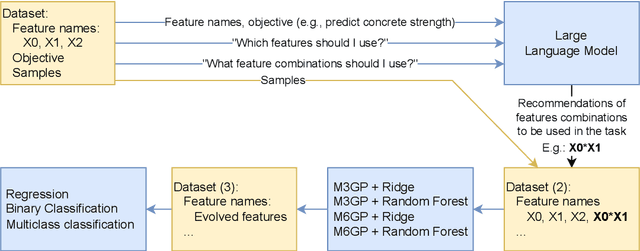
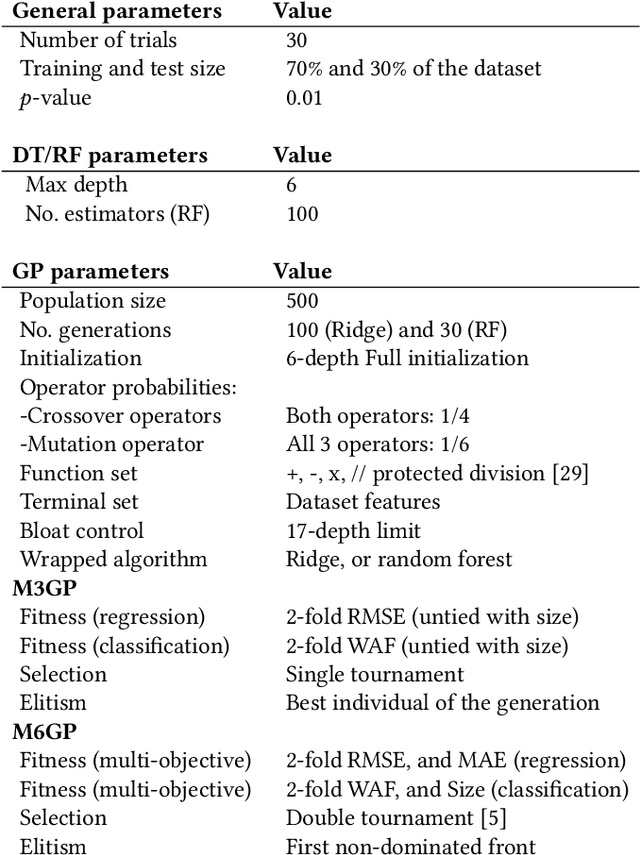
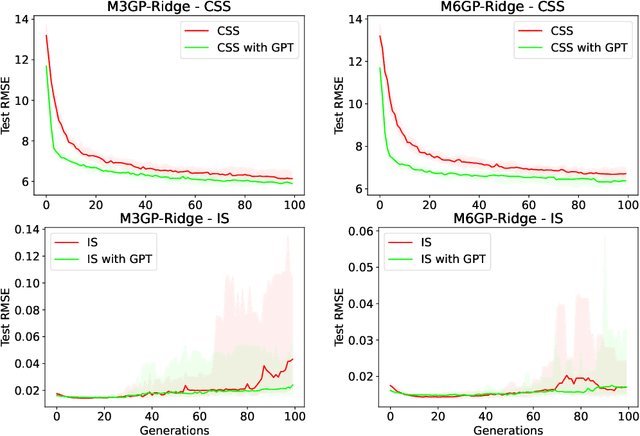
Feature engineering is mandatory in the machine learning pipeline to obtain robust models. While evolutionary computation is well-known for its great results both in feature selection and feature construction, its methods are computationally expensive due to the large number of evaluations required to induce the final model. Part of the reason why these algorithms require a large number of evaluations is their lack of domain-specific knowledge, resulting in a lot of random guessing during evolution. In this work, we propose using Large Language Models (LLMs) as an initial feature construction step to add knowledge to the dataset. By doing so, our results show that the evolution can converge faster, saving us computational resources. The proposed approach only provides the names of the features in the dataset and the target objective to the LLM, making it usable even when working with datasets containing private data. While consistent improvements to test performance were only observed for one-third of the datasets (CSS, PM, and IM10), possibly due to problems being easily explored by LLMs, this approach only decreased the model performance in 1/77 test cases. Additionally, this work introduces the M6GP feature engineering algorithm to symbolic regression, showing it can improve the results of the random forest regressor and produce competitive results with its predecessor, M3GP.