 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Features as Markers of Parkinson's Disease: The Issue of Clinical Interpretability
Mar 21, 2022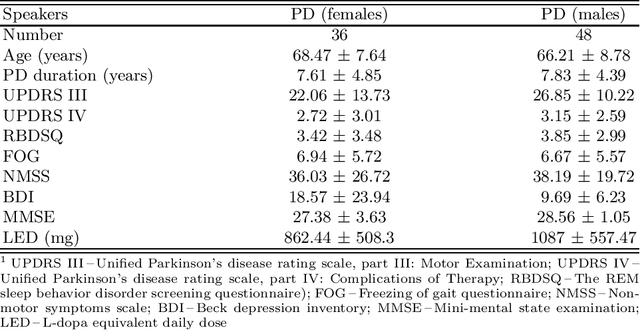
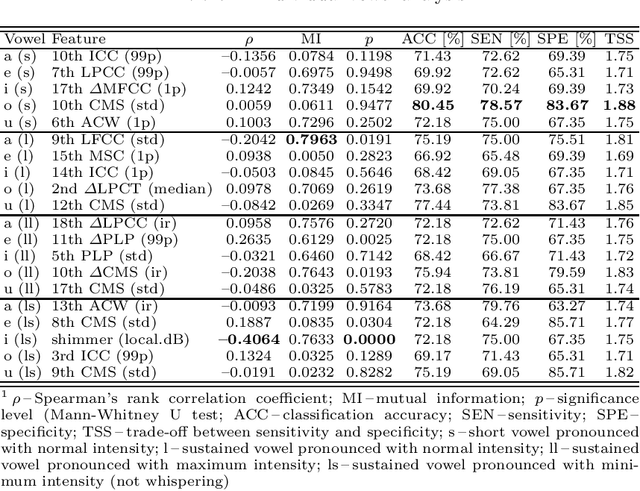
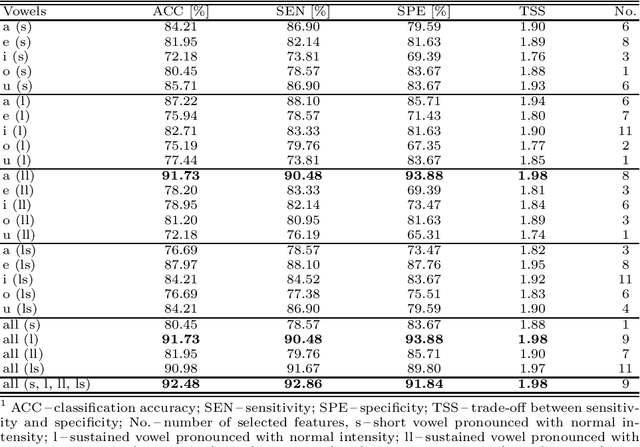
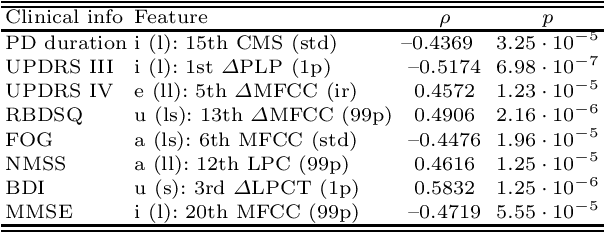
Up to 90% of patients with Parkinson's disease (PD) suffer from hypokinetic dysathria (HD) which is also manifested in the field of phonation. Clinical signs of HD like monoloudness, monopitch or hoarse voice are usually quantified by conventional clinical interpretable features (jitter, shimmer, harmonic-to-noise ratio, etc.). This paper provides large and robust insight into perceptual analysis of 5 Czech vowels of 84 PD patients and proves that despite the clinical inexplicability the perceptual features outperform the conventional ones, especially in terms of discrimination power (classification accuracy ACC = 92 %, sensitivity SEN = 93 %, specificity SPE = 92 %) and partial correlation with clinical scores like UPDRS (Unified Parkinson's disease rating scale), MMSE (Mini-mental state examination) or FOG (Freezing of gait questionnaire), where p < 0.0001.
* 8 pages, published in International Conference on NONLINEAR SPEECH PROCESSING, NOLISP 2015 jointly organized with the 25th Italian Workshop on Neural Networks, WIRN 2015, held at May 2015, Vietri sul Mare, Salerno, Italy
Identification of Hypokinetic Dysarthria Using Acoustic Analysis of Poem Recitation
Mar 18, 2022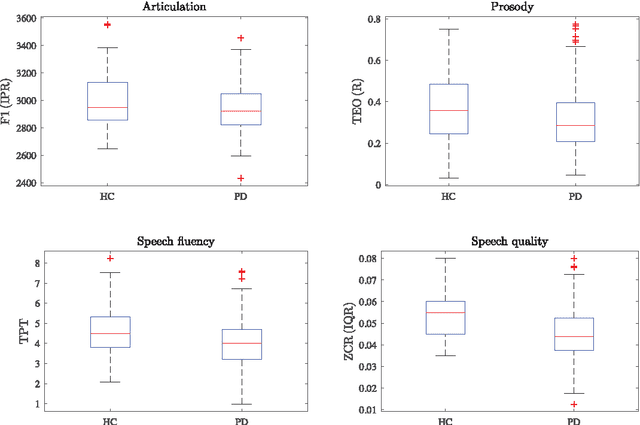
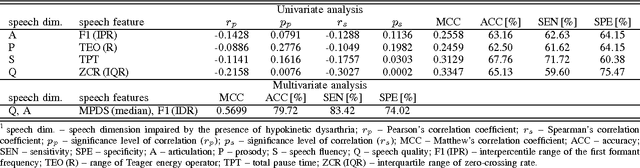
Up to 90 % of patients with Parkinson's disease (PD) suffer from hypokinetic dysarthria (HD). In this work, we analysed the power of conventional speech features quantifying imprecise articulation, dysprosody, speech dysfluency and speech quality deterioration extracted from a specialized poem recitation task to discriminate dysarthric and healthy speech. For this purpose, 152 speakers (53 healthy speakers, 99 PD patients) were examined. Only mildly strong correlation between speech features and clinical status of the speakers was observed. In the case of univariate classification analysis, sensitivity of 62.63% (imprecise articulation), 61.62% (dysprosody), 71.72% (speech dysfluency) and 59.60% (speech quality deterioration) was achieved. Multivariate classification analysis improved the classification performance. Sensitivity of 83.42% using only two features describing imprecise articulation and speech quality deterioration in HD was achieved. We showed the promising potential of the selected speech features and especially the use of poem recitation task to quantify and identify HD in PD.
Robust and Complex Approach of Pathological Speech Signal Analysis
Mar 17, 2022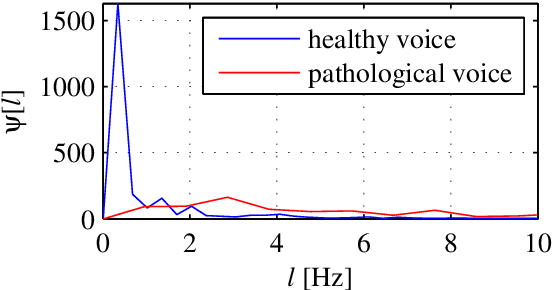
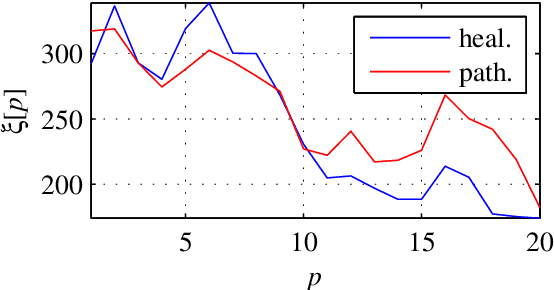
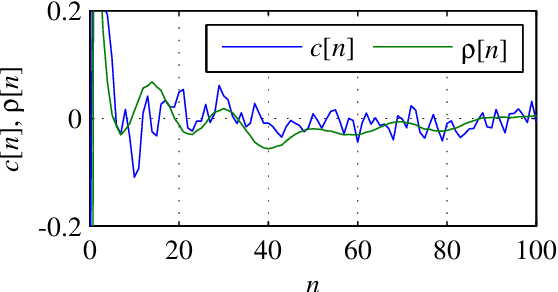
This paper presents a study of the approaches in the state-of-the-art in the field of pathological speech signal analysis with a special focus on parametrization techniques. It provides a description of 92 speech features where some of them are already widely used in this field of science and some of them have not been tried yet (they come from different areas of speech signal processing like speech recognition or coding). As an original contribution, this work introduces 36 completely new pathological voice measures based on modulation spectra, inferior colliculus coefficients, bicepstrum, sample and approximate entropy and empirical mode decomposition. The significance of these features was tested on 3 (English, Spanish and Czech) pathological voice databases with respect to classification accuracy, sensitivity and specificity.
* 41 pages, published in Neurocomputing, Volume 167, 2015, Pages 94-111, ISSN 0925-2312
Assessing Progress of Parkinson s Disease Using Acoustic Analysis of Phonation
Mar 17, 2022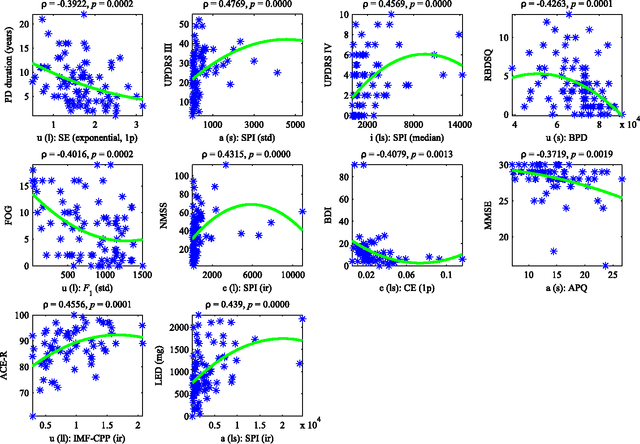
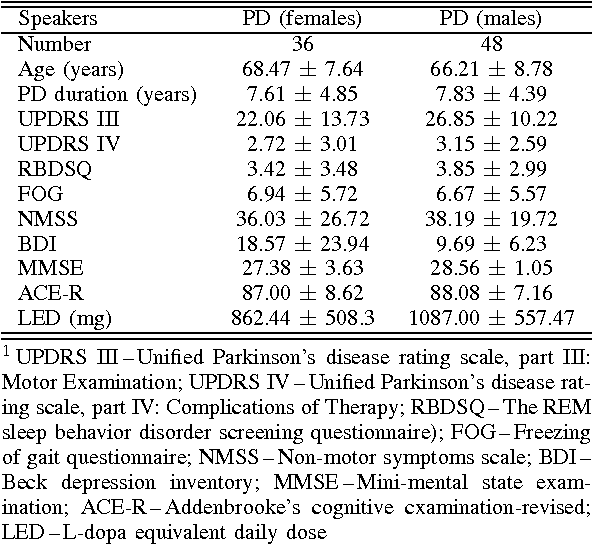
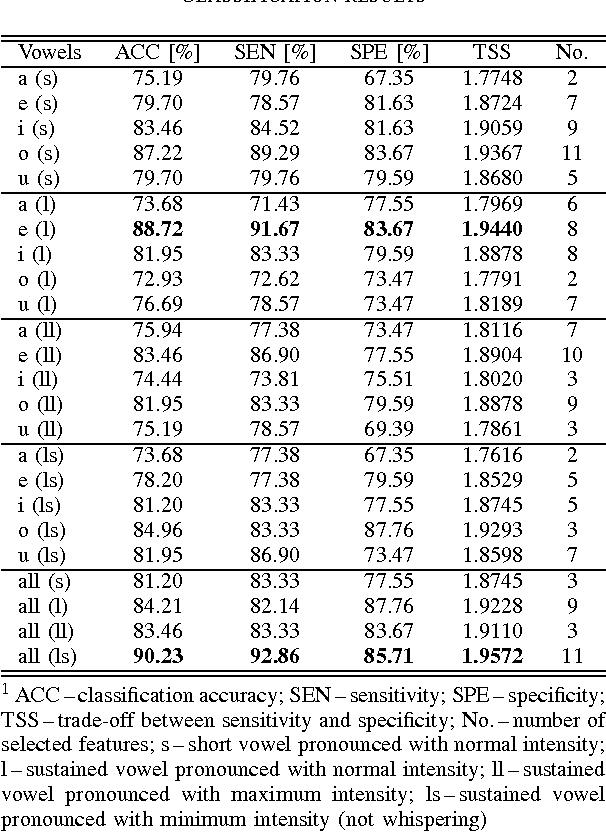
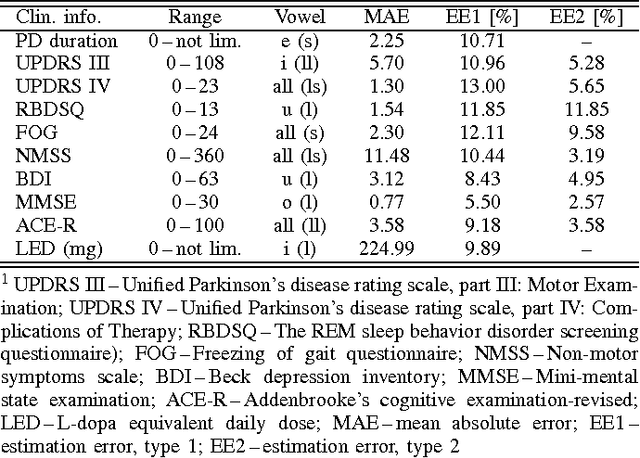
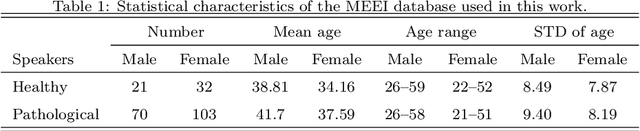
This paper deals with a complex acoustic analysis of phonation in patients with Parkinson's disease (PD) with a special focus on estimation of disease progress that is described by 7 different clinical scales ,e. g. Unified Parkinson's disease rating scale or Beck depression inventory. The analysis is based on parametrization of 5 Czech vowels pronounced by 84 PD patients. Using classification and regression trees we estimated all clinical scores with maximal error lower or equal to 13 %. Best estimation was observed in the case of Mini-mental state examination (MAE = 0.77, estimation error 5.50 %. Finally, we proposed a binary classification based on random forests that is able to identify Parkinson's disease with sensitivity SEN = 92.86 % (SPE = 85.71 %). The parametrization process was based on extraction of 107 speech features quantifying different clinical signs of hypokinetic dysarthria present in PD.
* 8 pages published in the 4th IEEE IWOBI 2015, pp. 115-122, 10-12 June, 2015 Donostia-San Sebastian. ISBN: 978-84-606-8733-7
Multi-focus thermal image fusion
Mar 16, 2022
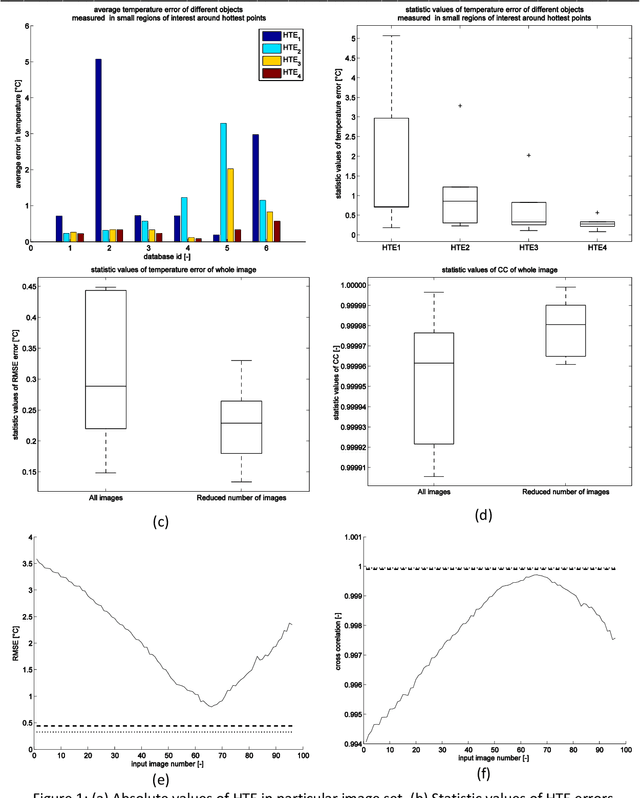

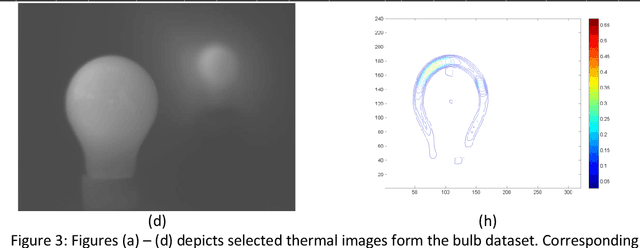
This paper proposes a novel algorithm for multi-focus thermal image fusion. The algorithm is based on local activity analysis and advanced pre-selection of images into fusion process. The algorithm improves the object temperature measurement error up to 5 Celsius degrees. The proposed algorithm is evaluated by half total error rate, root mean squared error, cross correlation and visual inspection. To the best of our knowledge, this is the first work devoted to multi-focus thermal image fusion. For testing of proposed algorithm we acquire six thermal image set with objects at different focal depth.
* 16 pages, published in Pattern Recognition Letters, Volume 34, Issue 5, 2013, Pages 536-544, ISSN 0167-8655
A multimodal approach for Parkinson disease analysis
Mar 10, 2022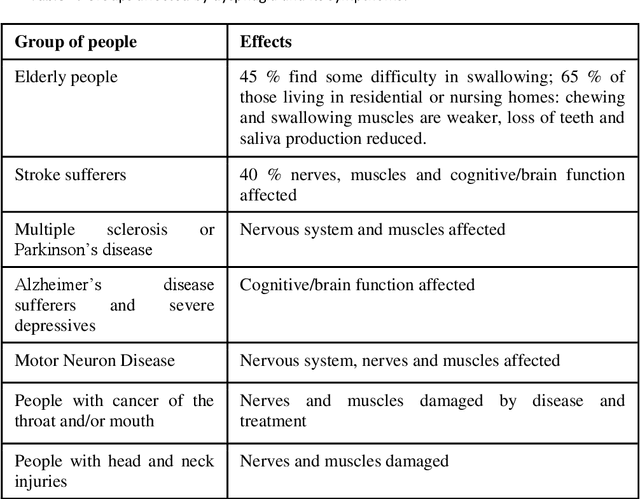
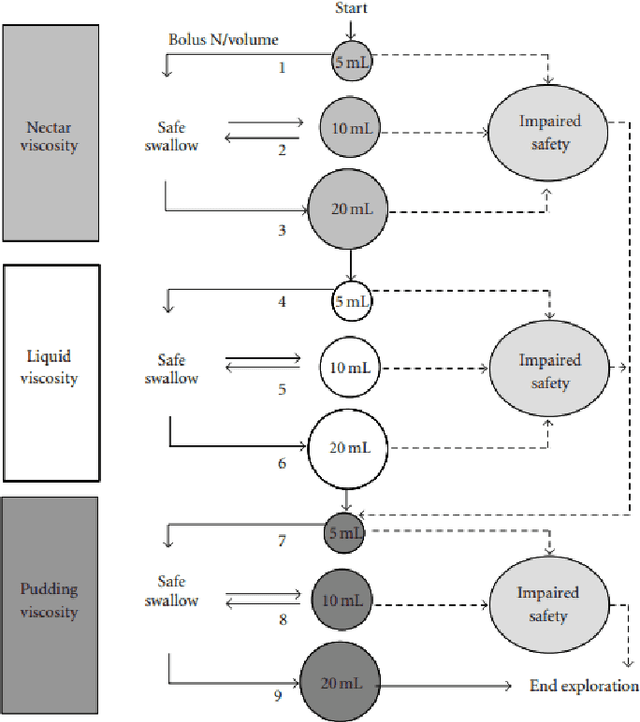
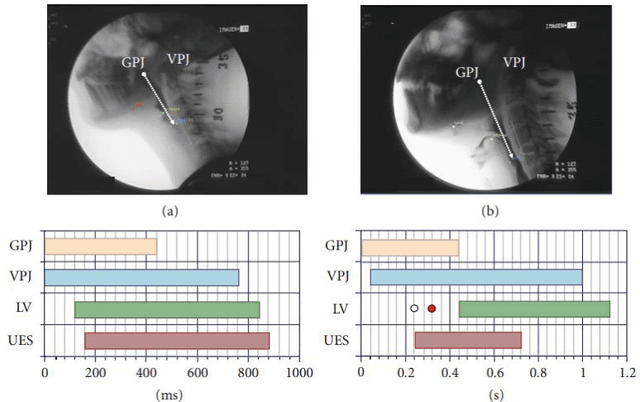
Parkinson's disease (PD) is the second most frequent neurodegenerative disease with prevalence among general population reaching 0.1-1 %, and an annual incidence between 1.3-2.0/10000 inhabitants. The mean age at diagnosis of PD is 55 and most patients are between 50 and 80 years old. The most obvious symptoms are movement-related; these include tremor, rigidity, slowness of movement and walking difficulties. Frequently these are the symptoms that lead to the PD diagnoses. Later, thinking and behavioral problems may arise, and other symptoms include cognitive impairment and sensory, sleep and emotional problems. In this paper we will present an ongoing project that will evaluate if voice and handwriting analysis can be reliable predictors/indicators of swallowing and balance impairments in PD. An important advantage of voice and handwritten analysis is its low intrusiveness and easy implementation in clinical practice. Thus, if a significant correlation between these simple analyses and the gold standard video-fluoroscopic analysis will imply simpler and less stressing diagnostic test for the patients as well as the use of cheaper analysis systems.
* 10 pages
A Preliminary Study on Aging Examining Online Handwriting
Mar 08, 2022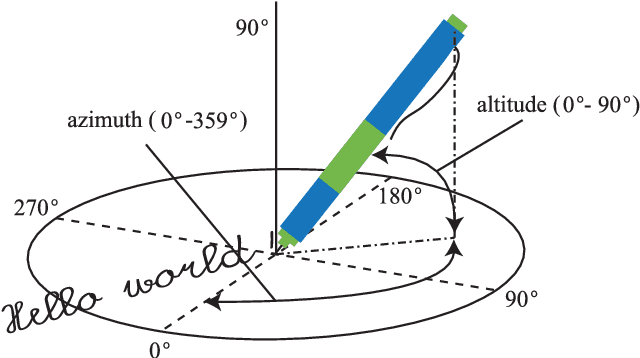

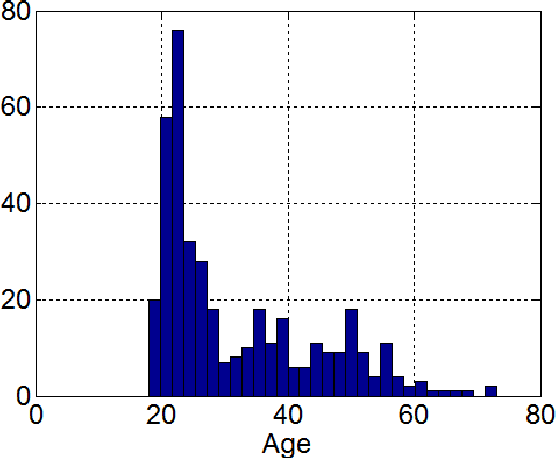
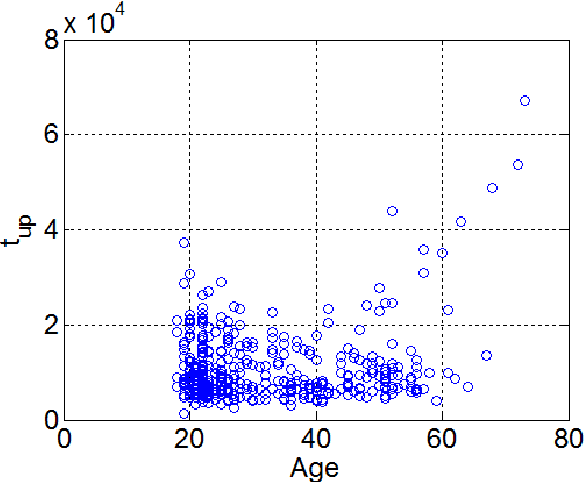
In order to develop infocommunications devices so that the capabilities of the human brain may interact with the capabilities of any artificially cognitive system a deeper knowledge of aging is necessary. Especially if society does not want to exclude elder people and wants to develop automatic systems able to help and improve the quality of life of this group of population, healthy individuals as well as those with cognitive decline or other pathologies. This paper tries to establish the variations in handwriting tasks with the goal to obtain a better knowledge about aging. We present the correlation results between several parameters extracted from online handwriting and the age of the writers. It is based on BIOSECURID database, which consists of 400 people that provided several biometric traits, including online handwriting. The main idea is to identify those parameters that are more stable and those more age dependent. One challenging topic for disease diagnose is the differentiation between healthy and pathological aging. For this purpose, it is necessary to be aware of handwriting parameters that are, in general, not affected by aging and those who experiment changes, increase or decrease their values, because of it. This paper contributes to this research line analyzing a selected set of online handwriting parameters provided by a healthy group of population aged from 18 to 70 years. Preliminary results show that these parameters are not affected by aging and therefore, changes in their values can only be attributed to motor or cognitive disorders.
* 4 pages
Online handwriting, signature and touch dynamics: tasks and potential applications in the field of security and health
Feb 24, 2022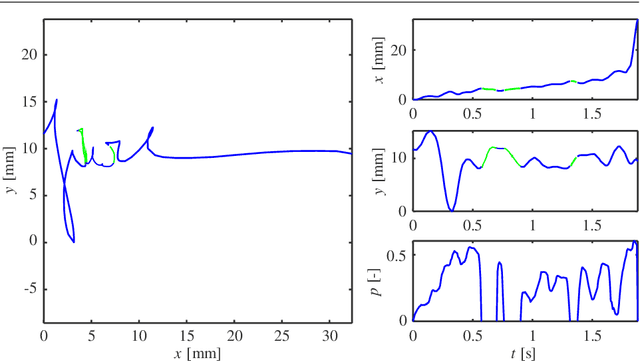

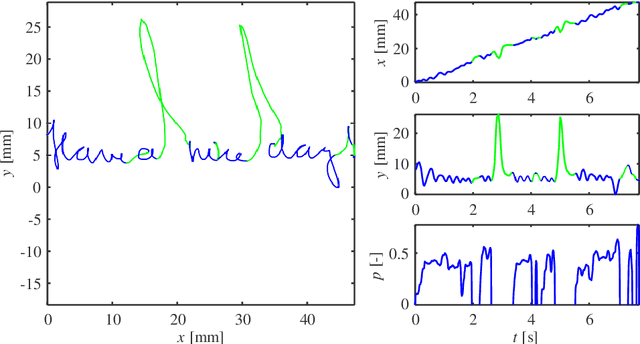
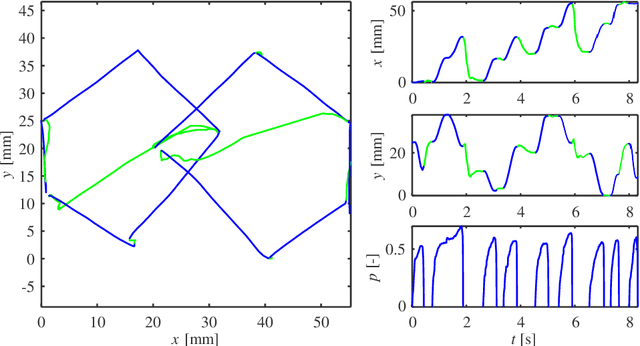
Background: An advantageous property of behavioural signals ,e.g. handwriting, in contrast to morphological ones, such as iris, fingerprint, hand geometry, etc., is the possibility to ask a user for a very rich amount of different tasks. Methods: This article summarises recent findings and applications of different handwriting and drawing tasks in the field of security and health. More specifically, it is focused on on-line handwriting and hand-based interaction, i.e. signals that utilise a digitizing device (specific devoted or general-purpose tablet/smartphone) during the realization of the tasks. Such devices permit the acquisition of on-surface dynamics as well as in-air movements in time, thus providing complex and richer information when compared to the conventional pen and paper method. Conclusions: Although the scientific literature reports a wide range of tasks and applications, in this paper, we summarize only those providing competitive results (e.g. in terms of discrimination power) and having a significant impact in the field.
* 27 pages
A comparative study of in-air trajectories at short and long distances in online handwriting
Feb 23, 2022
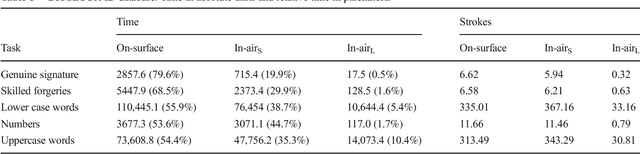
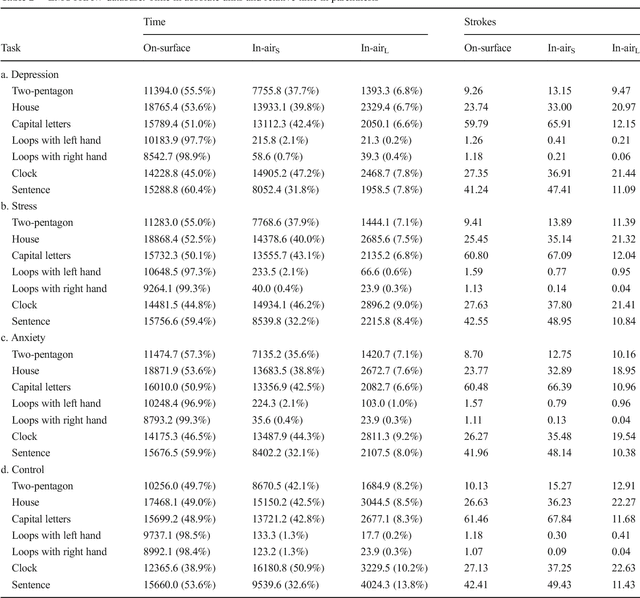
Introduction Existing literature about online handwriting analysis to support pathology diagnosis has taken advantage of in-air trajectories. A similar situation occurred in biometric security applications where the goal is to identify or verify an individual using his signature or handwriting. These studies do not consider the distance of the pen tip to the writing surface. This is due to the fact that current acquisition devices do not provide height formation. However, it is quite straightforward to differentiate movements at two different heights: a) short distance: height lower or equal to 1 cm above a surface of digitizer, the digitizer provides x and y coordinates. b) long distance: height exceeding 1 cm, the only information available is a time stamp that indicates the time that a specific stroke has spent at long distance. Although short distance has been used in several papers, long distances have been ignored and will be investigated in this paper. Methods In this paper, we will analyze a large set of databases (BIOSECURID, EMOTHAW, PaHaW, Oxygen-Therapy and SALT), which contain a total amount of 663 users and 17951 files. We have specifically studied: a) the percentage of time spent on-surface, in-air at short distance, and in-air at long distance for different user profiles (pathological and healthy users) and different tasks; b) The potential use of these signals to improve classification rates. Results and conclusions Our experimental results reveal that long-distance movements represent a very small portion of the total execution time (0.5 % in the case of signatures and 10.4% for uppercase words of BIOSECUR-ID, which is the largest database). In addition, significant differences have been found in the comparison of pathological versus control group for letter l in PaHaW database (p=0.0157) and crossed pentagons in SALT database (p=0.0122)
* 11 pages
Thermal hand image segmentation for biometric recognition
Feb 23, 2022
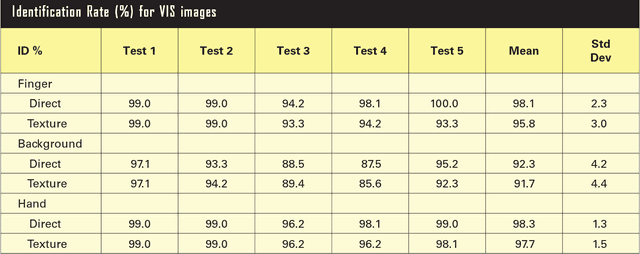
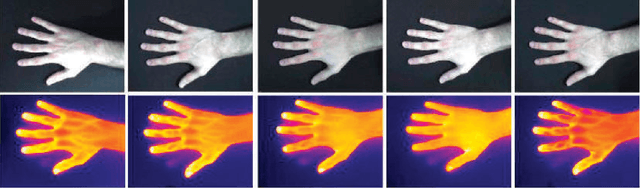

In this paper we present a method to identify people by means of thermal (TH) and visible (VIS) hand images acquired simultaneously with a TESTO 882-3 camera. In addition, we also present a new database specially acquired for this work. The real challenge when dealing with TH images is the cold finger areas, which can be confused with the acquisition surface. This problem is solved by taking advantage of the VIS information. We have performed different tests to show how TH and VIS images work in identification problems. Experimental results reveal that TH hand image is as suitable for biometric recognition systems as VIS hand images, and better results are obtained when combining this information. A Biometric Dispersion Matcher has been used as a feature vector dimensionality reduction technique as well as a classification task. Its selection criteria helps to reduce the length of the vectors used to perform identification up to a hundred measurements. Identification rates reach a maximum value of 98.3% under these conditions, when using a database of 104 people.
* 12 pages