 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Blending: Rethinking Alpha Blending in 3D Gaussian Splatting
Nov 19, 2025



The recent introduction of 3D Gaussian Splatting (3DGS) has significantly advanced novel view synthesis. Several studies have further improved the rendering quality of 3DGS, yet they still exhibit noticeable visual discrepancies when synthesizing views at sampling rates unseen during training. Specifically, they suffer from (i) erosion-induced blurring artifacts when zooming in and (ii) dilation-induced staircase artifacts when zooming out. We speculate that these artifacts arise from the fundamental limitation of the alpha blending adopted in 3DGS methods. Instead of the conventional alpha blending that computes alpha and transmittance as scalar quantities over a pixel, we propose to replace it with our novel Gaussian Blending that treats alpha and transmittance as spatially varying distributions. Thus, transmittances can be updated considering the spatial distribution of alpha values across the pixel area, allowing nearby background splats to contribute to the final rendering. Our Gaussian Blending maintains real-time rendering speed and requires no additional memory cost, while being easily integrated as a drop-in replacement into existing 3DGS-based or other NVS frameworks. Extensive experiments demonstrate that Gaussian Blending effectively captures fine details at various sampling rates unseen during training, consistently outperforming existing novel view synthesis models across both unseen and seen sampling rates.
ESR-NeRF: Emissive Source Reconstruction Using LDR Multi-view Images
Apr 24, 2024



Existing NeRF-based inverse rendering methods suppose that scenes are exclusively illuminated by distant light sources, neglecting the potential influence of emissive sources within a scene. In this work, we confront this limitation using LDR multi-view images captured with emissive sources turned on and off. Two key issues must be addressed: 1) ambiguity arising from the limited dynamic range along with unknown lighting details, and 2) the expensive computational cost in volume rendering to backtrace the paths leading to final object colors. We present a novel approach, ESR-NeRF, leveraging neural networks as learnable functions to represent ray-traced fields. By training networks to satisfy light transport segments, we regulate outgoing radiances, progressively identifying emissive sources while being aware of reflection areas. The results on scenes encompassing emissive sources with various properties demonstrate the superiority of ESR-NeRF in qualitative and quantitative ways. Our approach also extends its applicability to the scenes devoid of emissive sources, achieving lower CD metrics on the DTU dataset.
Continual Learning on Noisy Data Streams via Self-Purified Replay
Oct 14, 2021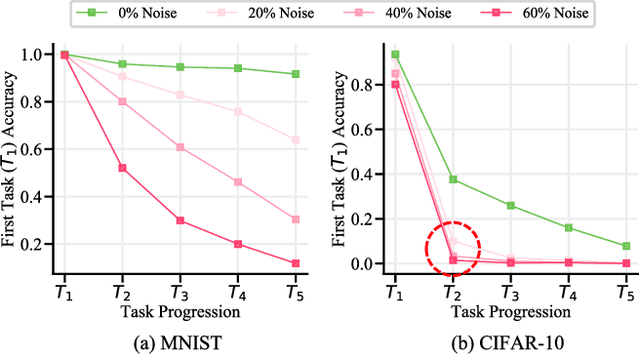
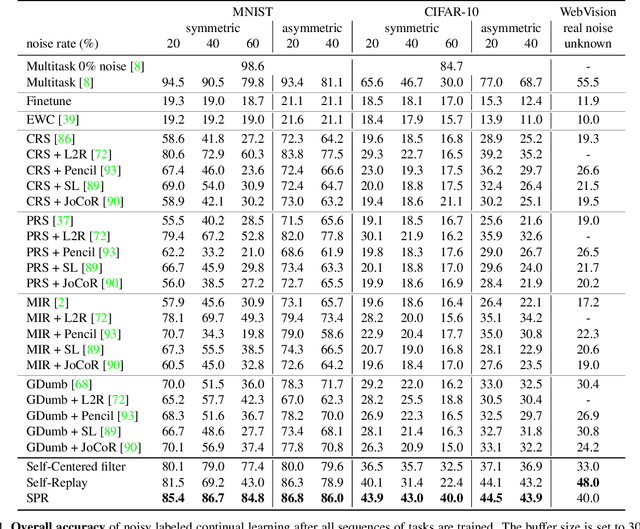
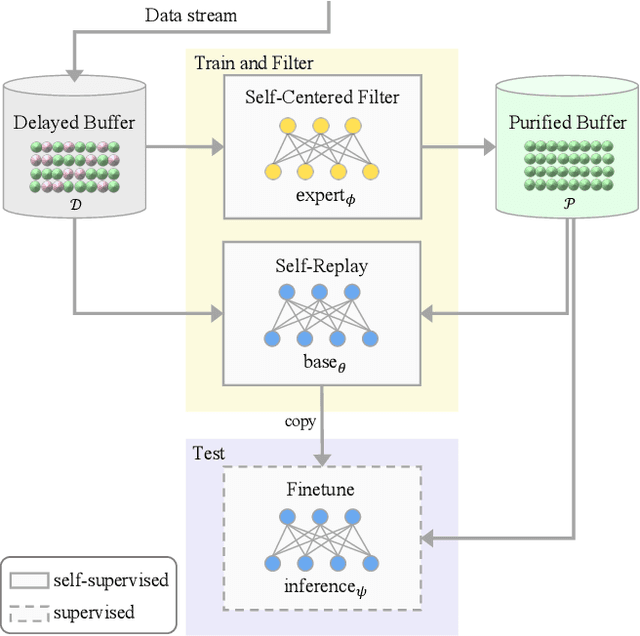
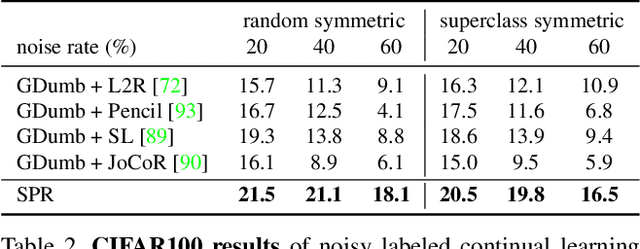
Continually learning in the real world must overcome many challenges, among which noisy labels are a common and inevitable issue. In this work, we present a repla-ybased continual learning framework that simultaneously addresses both catastrophic forgetting and noisy labels for the first time. Our solution is based on two observations; (i) forgetting can be mitigated even with noisy labels via self-supervised learning, and (ii) the purity of the replay buffer is crucial. Building on this regard, we propose two key components of our method: (i) a self-supervised replay technique named Self-Replay which can circumvent erroneous training signals arising from noisy labeled data, and (ii) the Self-Centered filter that maintains a purified replay buffer via centrality-based stochastic graph ensembles. The empirical results on MNIST, CIFAR-10, CIFAR-100, and WebVision with real-world noise demonstrate that our framework can maintain a highly pure replay buffer amidst noisy streamed data while greatly outperforming the combinations of the state-of-the-art continual learning and noisy label learning methods. The source code is available at http://vision.snu.ac.kr/projects/SPR
Imbalanced Continual Learning with Partitioning Reservoir Sampling
Sep 08, 2020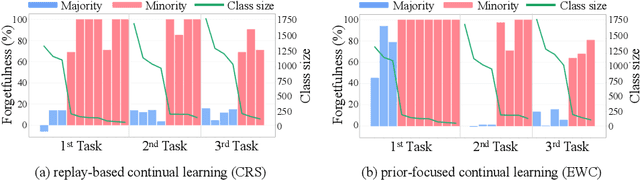
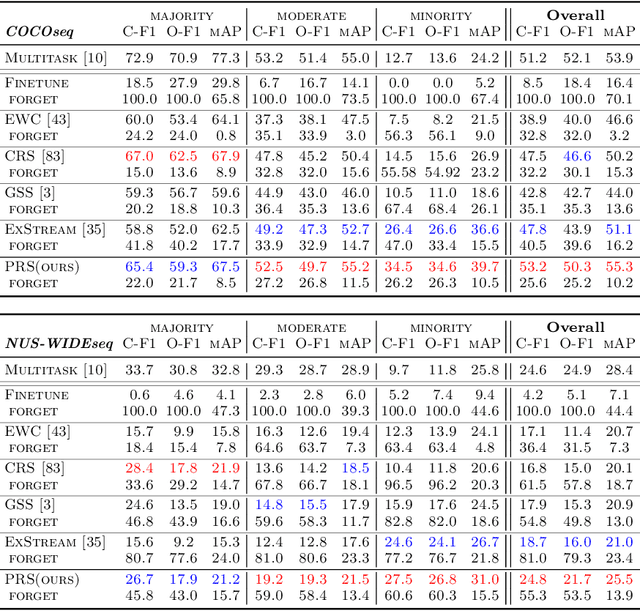
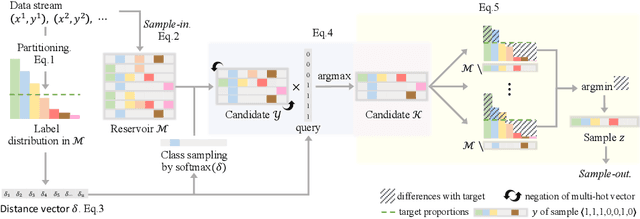
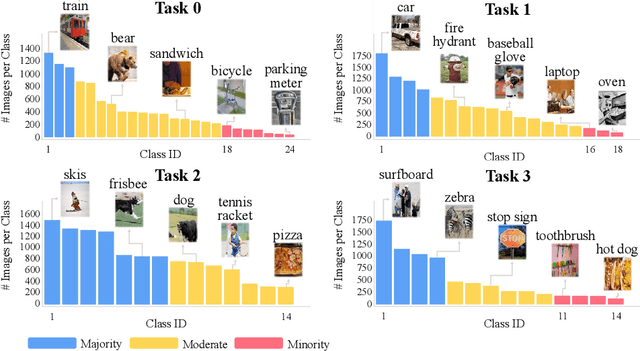
Continual learning from a sequential stream of data is a crucial challenge for machine learning research. Most studies have been conducted on this topic under the single-label classification setting along with an assumption of balanced label distribution. This work expands this research horizon towards multi-label classification. In doing so, we identify unanticipated adversity innately existent in many multi-label datasets, the long-tailed distribution. We jointly address the two independently solved problems, Catastropic Forgetting and the long-tailed label distribution by first empirically showing a new challenge of destructive forgetting of the minority concepts on the tail. Then, we curate two benchmark datasets, COCOseq and NUS-WIDEseq, that allow the study of both intra- and inter-task imbalances. Lastly, we propose a new sampling strategy for replay-based approach named Partitioning Reservoir Sampling (PRS), which allows the model to maintain a balanced knowledge of both head and tail classes. We publicly release the dataset and the code in our project page.