 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtend3D: Town-Scale 3D Generation
Mar 31, 2026In this paper, we propose Extend3D, a training-free pipeline for 3D scene generation from a single image, built upon an object-centric 3D generative model. To overcome the limitations of fixed-size latent spaces in object-centric models for representing wide scenes, we extend the latent space in the $x$ and $y$ directions. Then, by dividing the extended latent space into overlapping patches, we apply the object-centric 3D generative model to each patch and couple them at each time step. Since patch-wise 3D generation with image conditioning requires strict spatial alignment between image and latent patches, we initialize the scene using a point cloud prior from a monocular depth estimator and iteratively refine occluded regions through SDEdit. We discovered that treating the incompleteness of 3D structure as noise during 3D refinement enables 3D completion via a concept, which we term under-noising. Furthermore, to address the sub-optimality of object-centric models for sub-scene generation, we optimize the extended latent during denoising, ensuring that the denoising trajectories remain consistent with the sub-scene dynamics. To this end, we introduce 3D-aware optimization objectives for improved geometric structure and texture fidelity. We demonstrate that our method yields better results than prior methods, as evidenced by human preference and quantitative experiments.
Generating automatically labeled data for author name disambiguation: An iterative clustering method
Feb 05, 2021

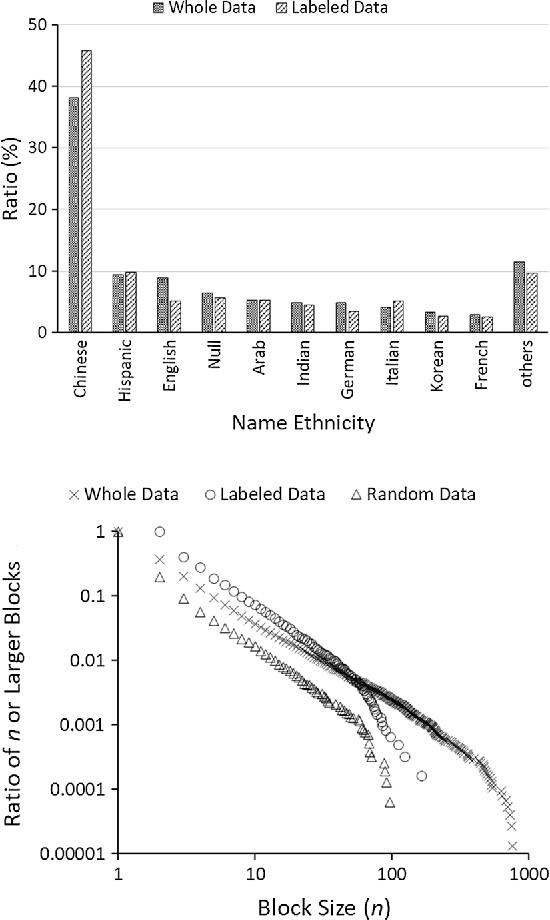

To train algorithms for supervised author name disambiguation, many studies have relied on hand-labeled truth data that are very laborious to generate. This paper shows that labeled training data can be automatically generated using information features such as email address, coauthor names, and cited references that are available from publication records. For this purpose, high-precision rules for matching name instances on each feature are decided using an external-authority database. Then, selected name instances in target ambiguous data go through the process of pairwise matching based on the rules. Next, they are merged into clusters by a generic entity resolution algorithm. The clustering procedure is repeated over other features until further merging is impossible. Tested on 26,566 instances out of the population of 228K author name instances, this iterative clustering produced accurately labeled data with pairwise F1 = 0.99. The labeled data represented the population data in terms of name ethnicity and co-disambiguating name group size distributions. In addition, trained on the labeled data, machine learning algorithms disambiguated 24K names in test data with performance of pairwise F1 = 0.90 ~ 0.92. Several challenges are discussed for applying this method to resolving author name ambiguity in large-scale scholarly data.
* 25 pages