 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Coupled Generative Adversarial Networks for Zero-Shot Domain Adaptation
Sep 11, 2020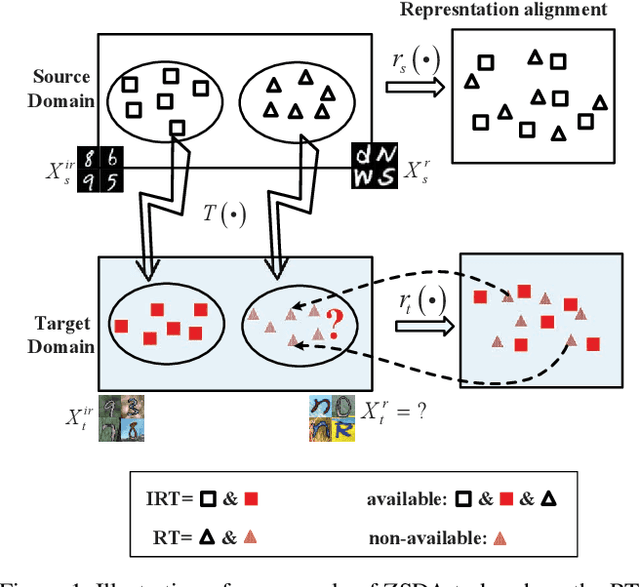
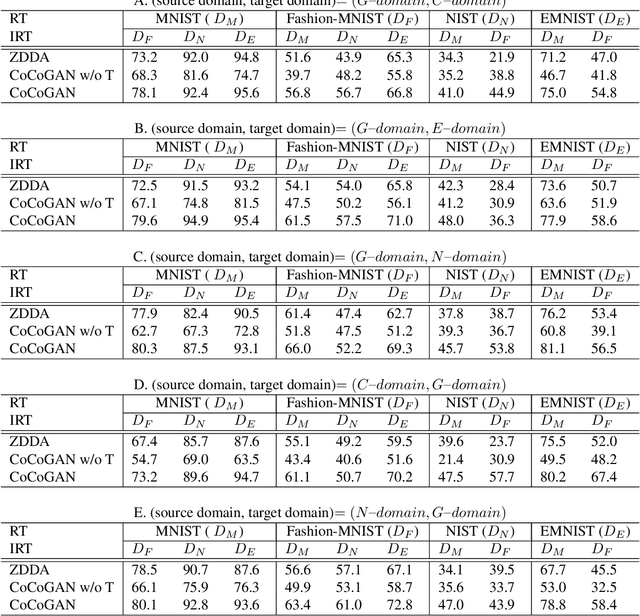
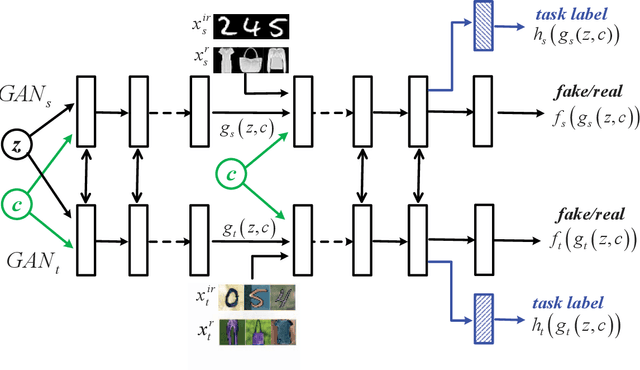

Machine learning models trained in one domain perform poorly in the other domains due to the existence of domain shift. Domain adaptation techniques solve this problem by training transferable models from the label-rich source domain to the label-scarce target domain. Unfortunately, a majority of the existing domain adaptation techniques rely on the availability of target-domain data, and thus limit their applications to a small community across few computer vision problems. In this paper, we tackle the challenging zero-shot domain adaptation (ZSDA) problem, where target-domain data is non-available in the training stage. For this purpose, we propose conditional coupled generative adversarial networks (CoCoGAN) by extending the coupled generative adversarial networks (CoGAN) into a conditioning model. Compared with the existing state of the arts, our proposed CoCoGAN is able to capture the joint distribution of dual-domain samples in two different tasks, i.e. the relevant task (RT) and an irrelevant task (IRT). We train CoCoGAN with both source-domain samples in RT and dual-domain samples in IRT to complete the domain adaptation. While the former provide high-level concepts of the non-available target-domain data, the latter carry the sharing correlation between the two domains in RT and IRT. To train CoCoGAN in the absence of target-domain data for RT, we propose a new supervisory signal, i.e. the alignment between representations across tasks. Extensive experiments carried out demonstrate that our proposed CoCoGAN outperforms existing state of the arts in image classifications.
Adversarial Learning for Zero-shot Domain Adaptation
Sep 11, 2020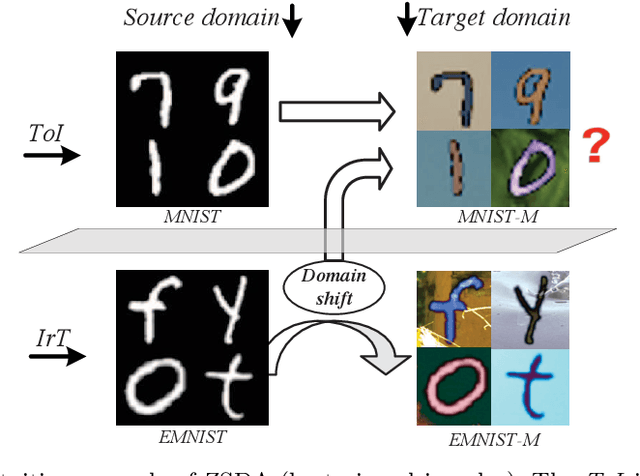
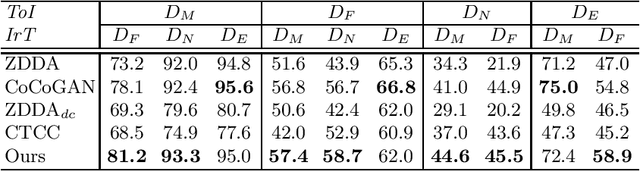
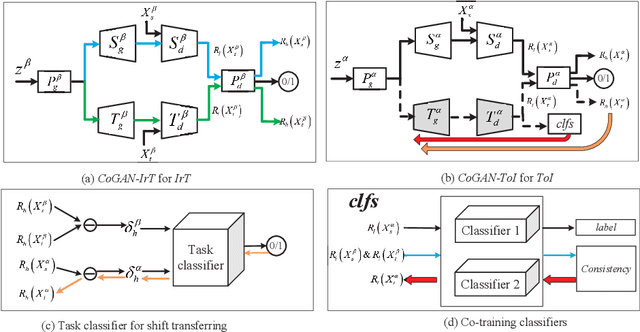
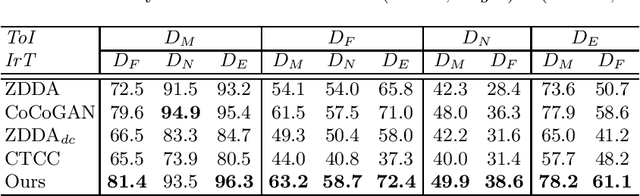
Zero-shot domain adaptation (ZSDA) is a category of domain adaptation problems where neither data sample nor label is available for parameter learning in the target domain. With the hypothesis that the shift between a given pair of domains is shared across tasks, we propose a new method for ZSDA by transferring domain shift from an irrelevant task (IrT) to the task of interest (ToI). Specifically, we first identify an IrT, where dual-domain samples are available, and capture the domain shift with a coupled generative adversarial networks (CoGAN) in this task. Then, we train a CoGAN for the ToI and restrict it to carry the same domain shift as the CoGAN for IrT does. In addition, we introduce a pair of co-training classifiers to regularize the training procedure of CoGAN in the ToI. The proposed method not only derives machine learning models for the non-available target-domain data, but also synthesizes the data themselves. We evaluate the proposed method on benchmark datasets and achieve the state-of-the-art performances.
Learning Common and Specific Features for RGB-D Semantic Segmentation with Deconvolutional Networks
Aug 03, 2016
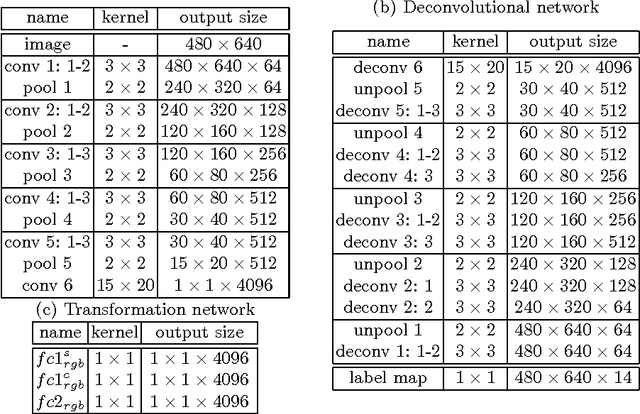
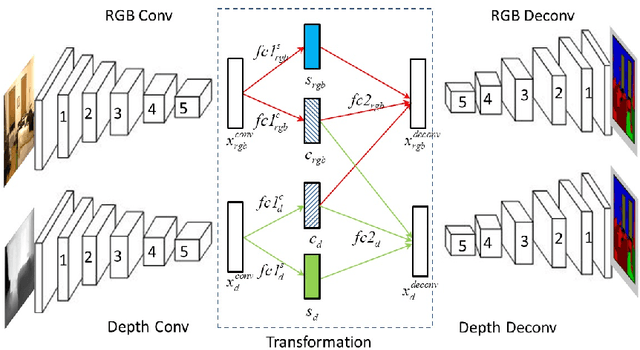
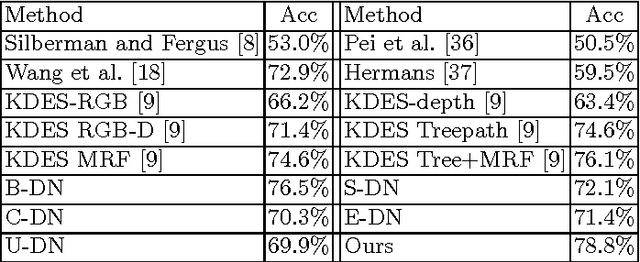
In this paper, we tackle the problem of RGB-D semantic segmentation of indoor images. We take advantage of deconvolutional networks which can predict pixel-wise class labels, and develop a new structure for deconvolution of multiple modalities. We propose a novel feature transformation network to bridge the convolutional networks and deconvolutional networks. In the feature transformation network, we correlate the two modalities by discovering common features between them, as well as characterize each modality by discovering modality specific features. With the common features, we not only closely correlate the two modalities, but also allow them to borrow features from each other to enhance the representation of shared information. With specific features, we capture the visual patterns that are only visible in one modality. The proposed network achieves competitive segmentation accuracy on NYU depth dataset V1 and V2.
Hierarchical Spatial Sum-Product Networks for Action Recognition in Still Images
Jul 08, 2016
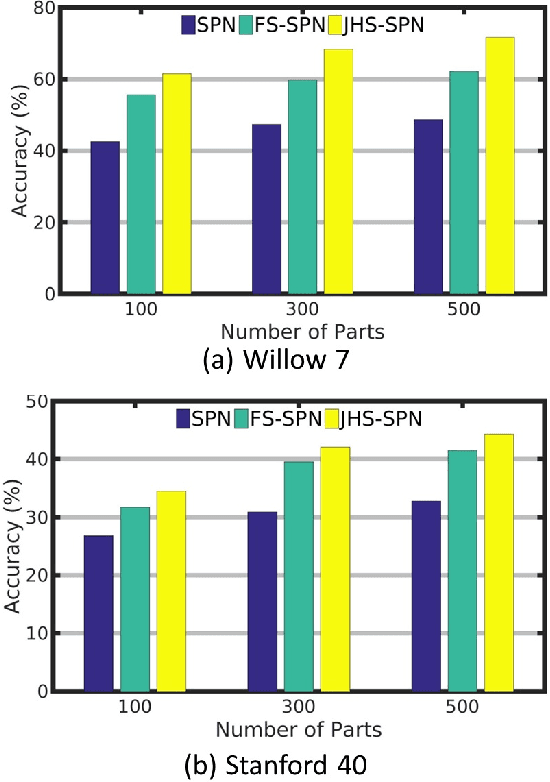

Recognizing actions from still images is popularly studied recently. In this paper, we model an action class as a flexible number of spatial configurations of body parts by proposing a new spatial SPN (Sum-Product Networks). First, we discover a set of parts in image collections via unsupervised learning. Then, our new spatial SPN is applied to model the spatial relationship and also the high-order correlations of parts. To learn robust networks, we further develop a hierarchical spatial SPN method, which models pairwise spatial relationship between parts inside sub-images and models the correlation of sub-images via extra layers of SPN. Our method is shown to be effective on two benchmark datasets.
Towards Predicting the Likeability of Fashion Images
Nov 23, 2015

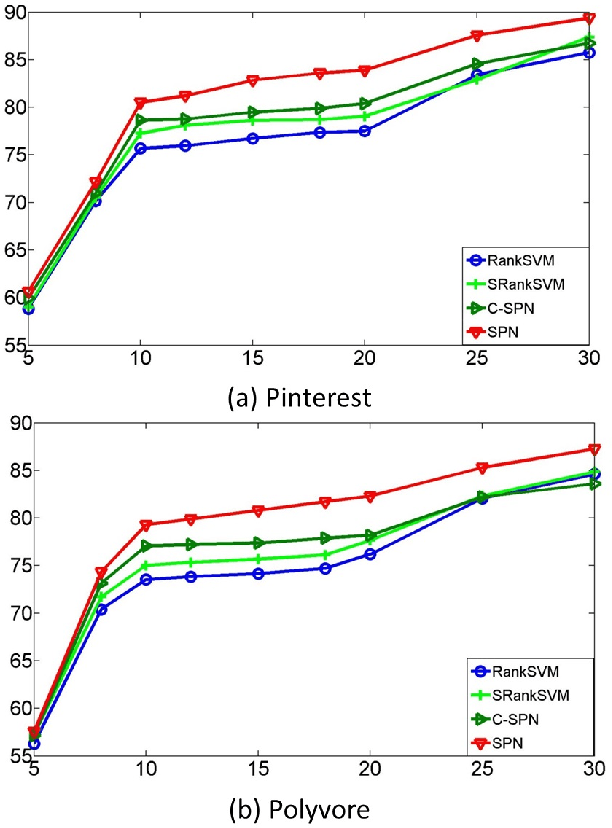
In this paper, we propose a method for ranking fashion images to find the ones which might be liked by more people. We collect two new datasets from image sharing websites (Pinterest and Polyvore). We represent fashion images based on attributes: semantic attributes and data-driven attributes. To learn semantic attributes from limited training data, we use an algorithm on multi-task convolutional neural networks to share visual knowledge among different semantic attribute categories. To discover data-driven attributes unsupervisedly, we propose an algorithm to simultaneously discover visual clusters and learn fashion-specific feature representations. Given attributes as representations, we propose to learn a ranking SPN (sum product networks) to rank pairs of fashion images. The proposed ranking SPN can capture the high-order correlations of the attributes. We show the effectiveness of our method on our two newly collected datasets.