 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Collaborative Metric Learning with Efficient Negative Sampling
Sep 24, 2019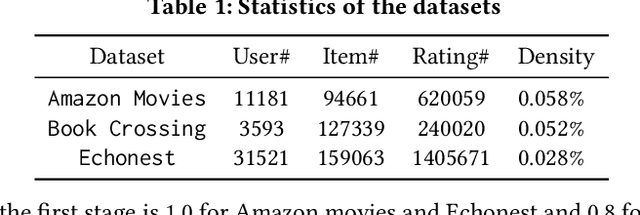
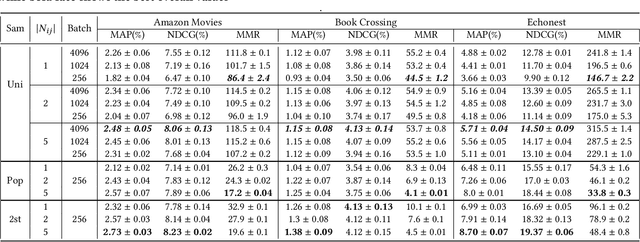
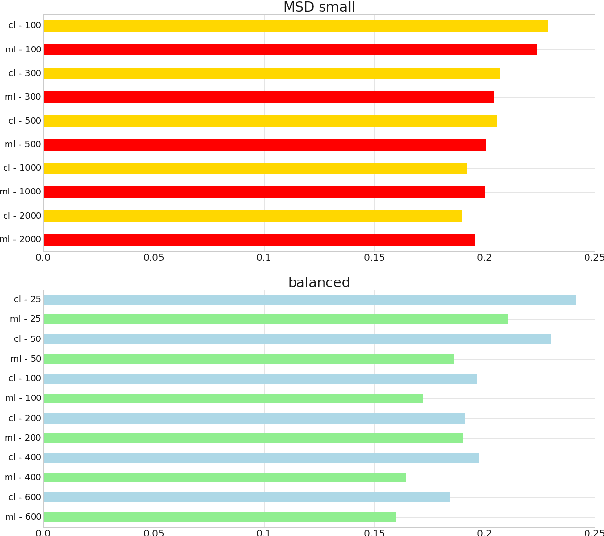
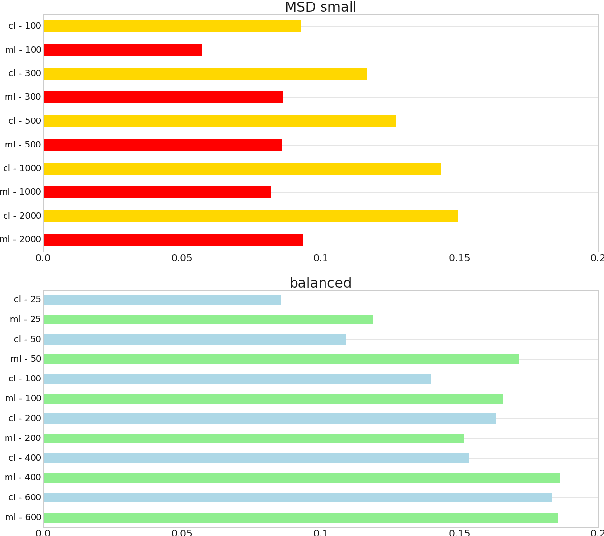
Distance metric learning based on triplet loss has been applied with success in a wide range of applications such as face recognition, image retrieval, speaker change detection and recently recommendation with the CML model. However, as we show in this article, CML requires large batches to work reasonably well because of a too simplistic uniform negative sampling strategy for selecting triplets. Due to memory limitations, this makes it difficult to scale in high-dimensional scenarios. To alleviate this problem, we propose here a 2-stage negative sampling strategy which finds triplets that are highly informative for learning. Our strategy allows CML to work effectively in terms of accuracy and popularity bias, even when the batch size is an order of magnitude smaller than what would be needed with the default uniform sampling. We demonstrate the suitability of the proposed strategy for recommendation and exhibit consistent positive results across various datasets.
Disambiguating Music Artists at Scale with Audio Metric Learning
Oct 03, 2018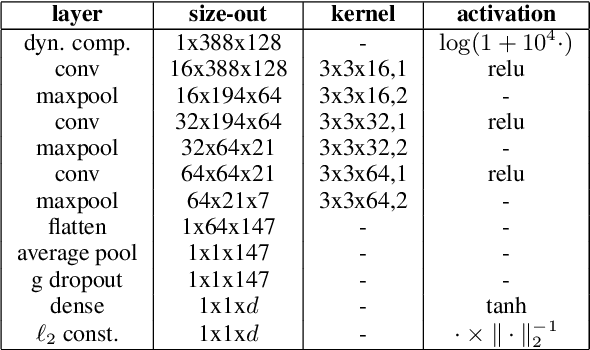
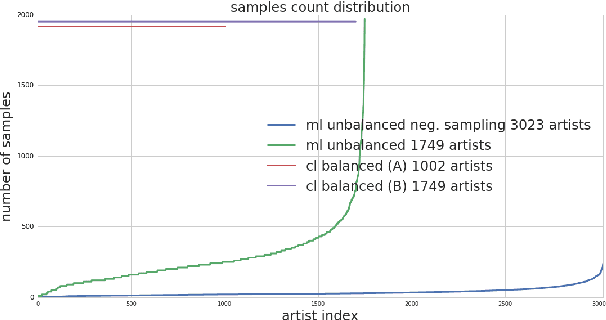
We address the problem of disambiguating large scale catalogs through the definition of an unknown artist clustering task. We explore the use of metric learning techniques to learn artist embeddings directly from audio, and using a dedicated homonym artists dataset, we compare our method with a recent approach that learn similar embeddings using artist classifiers. While both systems have the ability to disambiguate unknown artists relying exclusively on audio, we show that our system is more suitable in the case when enough audio data is available for each artist in the train dataset. We also propose a new negative sampling method for metric learning that takes advantage of side information such as music genre during the learning phase and shows promising results for the artist clustering task.
Music Mood Detection Based On Audio And Lyrics With Deep Neural Net
Sep 19, 2018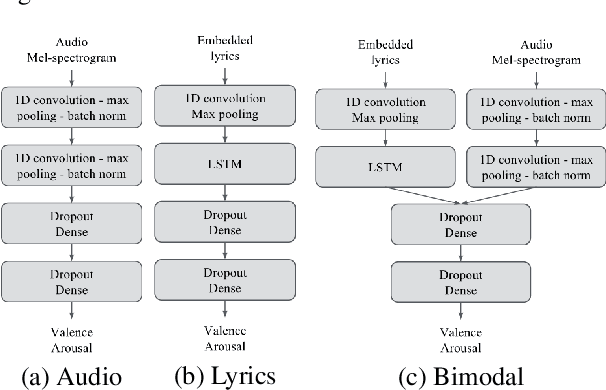

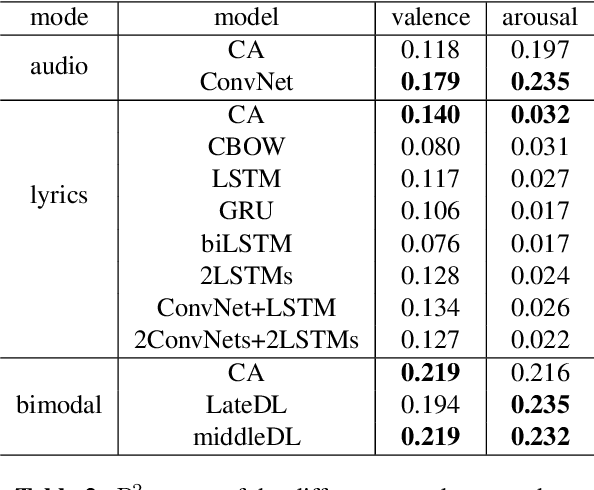

We consider the task of multimodal music mood prediction based on the audio signal and the lyrics of a track. We reproduce the implementation of traditional feature engineering based approaches and propose a new model based on deep learning. We compare the performance of both approaches on a database containing 18,000 tracks with associated valence and arousal values and show that our approach outperforms classical models on the arousal detection task, and that both approaches perform equally on the valence prediction task. We also compare the a posteriori fusion with fusion of modalities optimized simultaneously with each unimodal model, and observe a significant improvement of valence prediction. We release part of our database for comparison purposes.
Word2Vec applied to Recommendation: Hyperparameters Matter
Aug 29, 2018


Skip-gram with negative sampling, a popular variant of Word2vec originally designed and tuned to create word embeddings for Natural Language Processing, has been used to create item embeddings with successful applications in recommendation. While these fields do not share the same type of data, neither evaluate on the same tasks, recommendation applications tend to use the same already tuned hyperparameters values, even if optimal hyperparameters values are often known to be data and task dependent. We thus investigate the marginal importance of each hyperparameter in a recommendation setting through large hyperparameter grid searches on various datasets. Results reveal that optimizing neglected hyperparameters, namely negative sampling distribution, number of epochs, subsampling parameter and window-size, significantly improves performance on a recommendation task, and can increase it by an order of magnitude. Importantly, we find that optimal hyperparameters configurations for Natural Language Processing tasks and Recommendation tasks are noticeably different.