 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive cognitive fit: Artificial intelligence augmented management of information facets and representations
Apr 25, 2022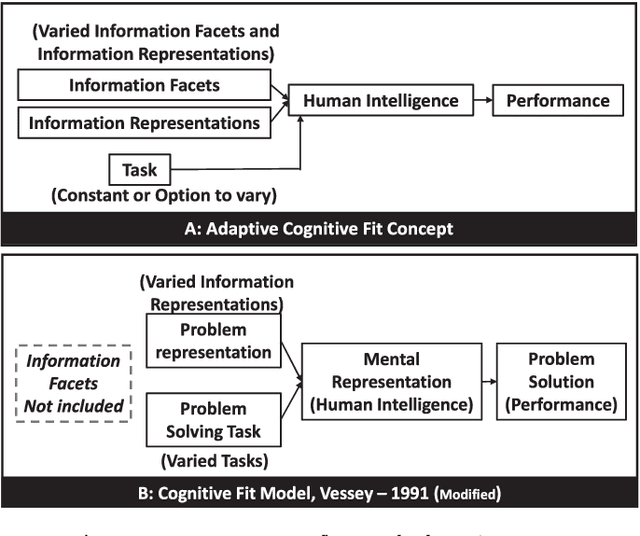
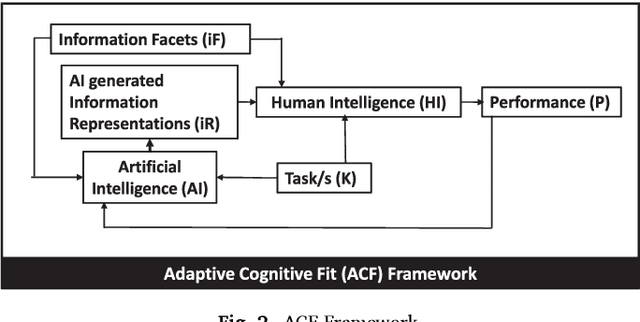

Explosive growth in big data technologies and artificial intelligence [AI] applications have led to increasing pervasiveness of information facets and a rapidly growing array of information representations. Information facets, such as equivocality and veracity, can dominate and significantly influence human perceptions of information and consequently affect human performance. Extant research in cognitive fit, which preceded the big data and AI era, focused on the effects of aligning information representation and task on performance, without sufficient consideration to information facets and attendant cognitive challenges. Therefore, there is a compelling need to understand the interplay of these dominant information facets with information representations and tasks, and their influence on human performance. We suggest that artificially intelligent technologies that can adapt information representations to overcome cognitive limitations are necessary for these complex information environments. To this end, we propose and test a novel *Adaptive Cognitive Fit* [ACF] framework that explains the influence of information facets and AI-augmented information representations on human performance. We draw on information processing theory and cognitive dissonance theory to advance the ACF framework and a set of propositions. We empirically validate the ACF propositions with an economic experiment that demonstrates the influence of information facets, and a machine learning simulation that establishes the viability of using AI to improve human performance.
Textual Data Distributions: Kullback Leibler Textual Distributions Contrasts on GPT-2 Generated Texts, with Supervised, Unsupervised Learning on Vaccine & Market Topics & Sentiment
Jun 15, 2021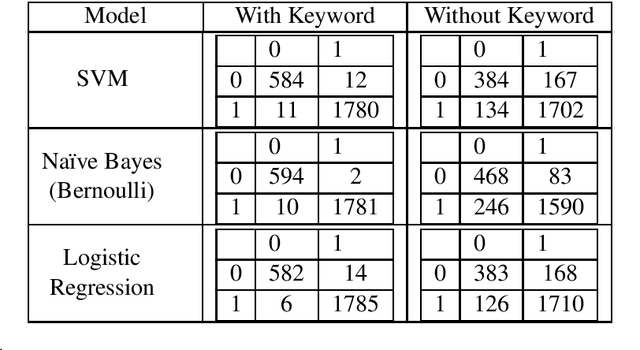
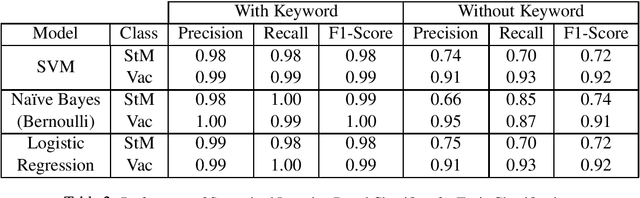
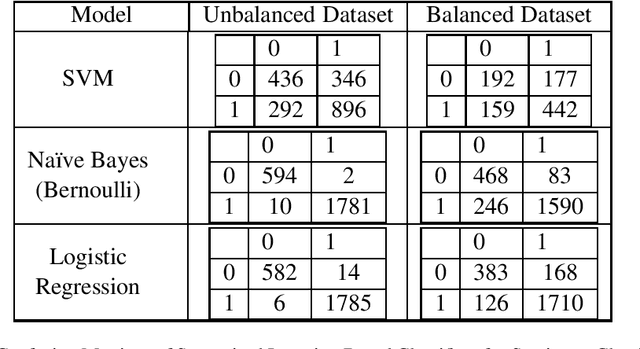
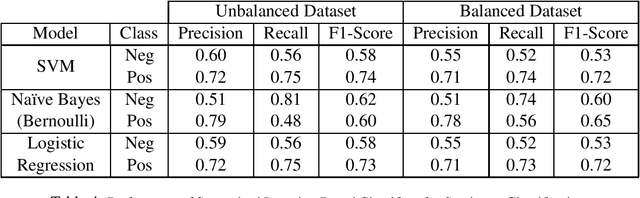
Efficient textual data distributions (TDD) alignment and generation are open research problems in textual analytics and NLP. It is presently difficult to parsimoniously and methodologically confirm that two or more natural language datasets belong to similar distributions, and to identify the extent to which textual data possess alignment. This study focuses on addressing a segment of the broader problem described above by applying multiple supervised and unsupervised machine learning (ML) methods to explore the behavior of TDD by (i) topical alignment, and (ii) by sentiment alignment. Furthermore we use multiple text generation methods including fine-tuned GPT-2, to generate text by topic and by sentiment. Finally we develop a unique process driven variation of Kullback-Leibler divergence (KLD) application to TDD, named KL Textual Distributions Contrasts(KL-TDC) to identify the alignment of machine generated textual corpora with naturally occurring textual corpora. This study thus identifies a unique approach for generating and validating TDD by topic and sentiment, which can be used to help address sparse data problems and other research, practice and classroom situations in need of artificially generated topic or sentiment aligned textual data.
Automating Discovery of Dominance in Synchronous Computer-Mediated Communication
Feb 24, 2020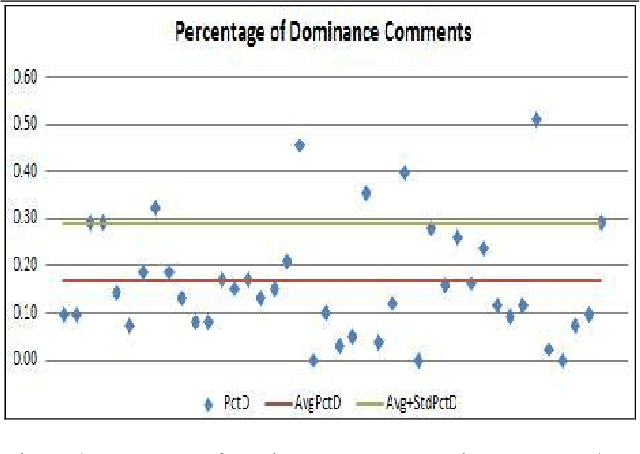
With the advent of electronic interaction, dominance (or the assertion of control over others) has acquired new dimensions. This study investigates the dynamics and characteristics of dominance in virtual interaction by analyzing electronic chat transcripts of groups solving a hidden profile task. We investigate computer-mediated communication behavior patterns that demonstrate dominance and identify a number of relevant variables. These indicators are calculated with automatic and manual coding of text transcripts. A comparison of both sets of variables indicates that automatic text analysis methods yield similar conclusions than manual coding. These findings are encouraging to advance research in text analysis methods in general, and in the study of virtual team dominance in particular.