 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLATTE: Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer
Apr 11, 2024


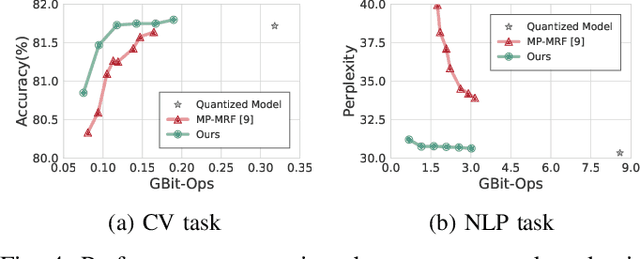
With the rise of Transformer models in NLP and CV domain, Multi-Head Attention has been proven to be a game-changer. However, its expensive computation poses challenges to the model throughput and efficiency, especially for the long sequence tasks. Exploiting the sparsity in attention has been proven to be an effective way to reduce computation. Nevertheless, prior works do not consider the various distributions among different heads and lack a systematic method to determine the threshold. To address these challenges, we propose Low-Precision Approximate Attention with Head-wise Trainable Threshold for Efficient Transformer (LATTE). LATTE employs a headwise threshold-based filter with the low-precision dot product and computation reuse mechanism to reduce the computation of MHA. Moreover, the trainable threshold is introduced to provide a systematic method for adjusting the thresholds and enable end-to-end optimization. Experimental results indicate LATTE can smoothly adapt to both NLP and CV tasks, offering significant computation savings with only a minor compromise in performance. Also, the trainable threshold is shown to be essential for the leverage between the performance and the computation. As a result, LATTE filters up to 85.16% keys with only a 0.87% accuracy drop in the CV task and 89.91% keys with a 0.86 perplexity increase in the NLP task.