 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexGPT 0.1: pre-trained GPT-J models with Pile of Law
Jun 05, 2023

This research aims to build generative language models specialized for the legal domain. The manuscript presents the development of LexGPT models based on GPT-J models and pre-trained with Pile of Law. The foundation model built in this manuscript is the initial step for the development of future applications in the legal domain, such as further training with reinforcement learning from human feedback. Another objective of this manuscript is to assist legal professionals in utilizing language models through the ``No Code'' approach. By fine-tuning models with specialized data and without modifying any source code, legal professionals can create custom language models for downstream tasks with minimum effort and technical knowledge. The downstream task in this manuscript is to turn a LexGPT model into a classifier, although the performance is notably lower than the state-of-the-art result. How to enhance downstream task performance without modifying the model or its source code is a research topic for future exploration.
Evaluating Generative Patent Language Models
Jun 23, 2022
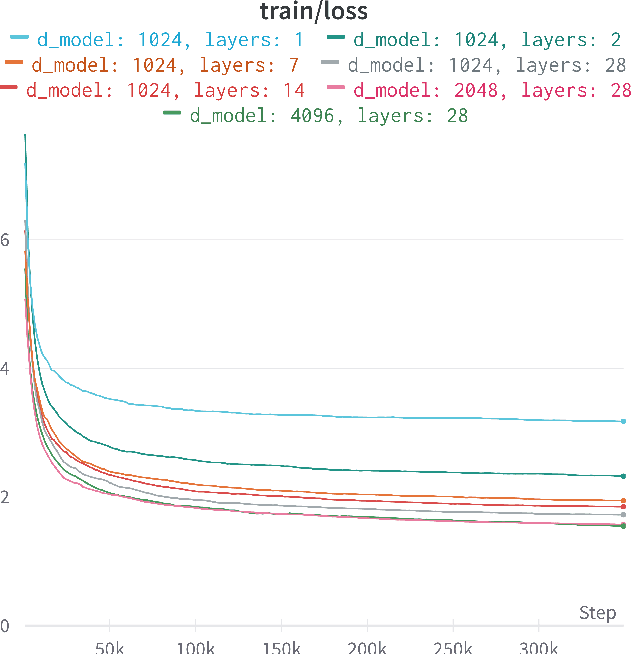


This research aims to build generative language models in the patent domain and to evaluate the models from a human-centric perspective. The evaluation metric is to calculate the ratio of keystrokes that can be saved for a user in an autocomplete context based on the prediction of the generative models. The performance of models in different sizes can also be evaluated in such a metric by measuring a number of newly granted patents. On the basis of the metric, it is found that the largest model is not necessarily the best. Several models are pre-trained from scratch with patent corpus and are released. The experiments in this manuscript focus on patent claims, but the ideas and implementation can be applied to other parts of a patent document. Furthermore, this research is motivated to measure how close the pre-trained language model can generate a newly granted patent claim. Or, conversely, the task is to measure the probabilities for the model to generate each token text given the newly granted patent claim. In addition, this manuscript raises several legal implications on patent law for potential interdisciplinary research in the future. In particular, can the metric based on model prediction be a metric to measure the nonobviousness requirement in the patent law?
Prior Art Search and Reranking for Generated Patent Text
Sep 19, 2020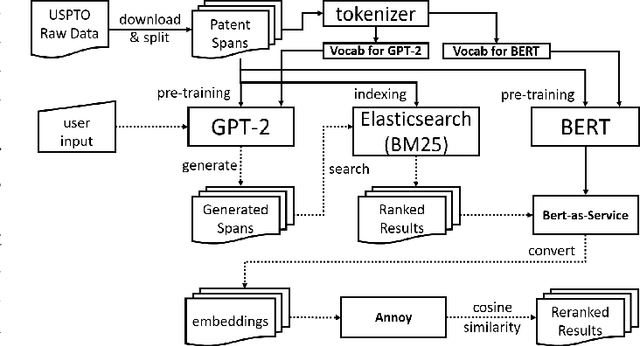
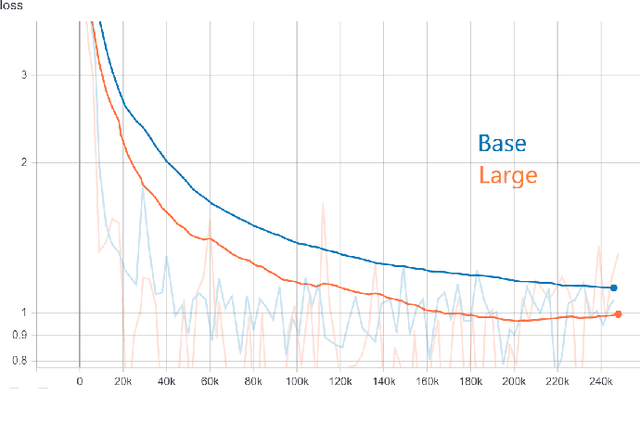
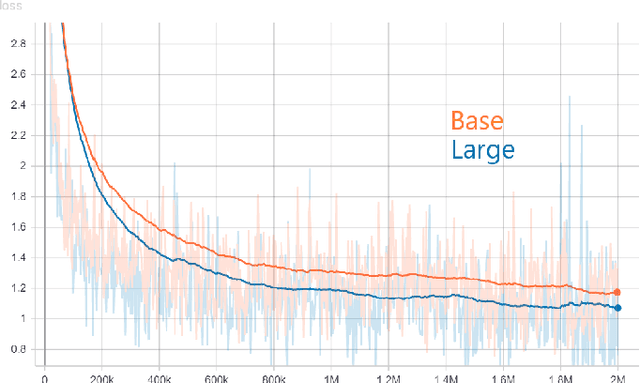
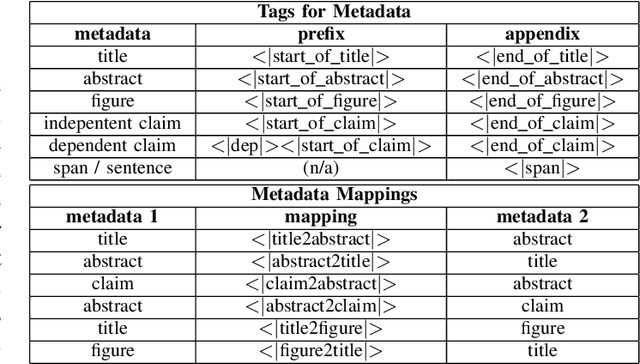
Generative models, such as GPT-2, have demonstrated impressive results recently. A fundamental question we'd like to address is: where did the generated text come from? This work is our initial effort toward answering the question by using prior art search. The purpose of the prior art search is to find the most similar prior text in the training data of GPT-2. We take a reranking approach and apply it to the patent domain. Specifically, we pre-train GPT-2 models from scratch by using the patent data from the USPTO. The input for the prior art search is the patent text generated by the GPT-2 model. We also pre-trained BERT models from scratch for converting patent text to embeddings. The steps of reranking are: (1) search the most similar text in the training data of GPT-2 by taking a bag-of-word ranking approach (BM25), (2) convert the search results in text format to BERT embeddings, and (3) provide the final result by ranking the BERT embeddings based on their similarities with the patent text generated by GPT-2. The experiments in this work show that such reranking is better than ranking with embeddings alone. However, our mixed results also indicate that calculating the semantic similarities among long text spans is still challenging. To our knowledge, this work is the first to implement a reranking system to identify retrospectively the most similar inputs to a GPT model based on its output.
PatentTransformer-2: Controlling Patent Text Generation by Structural Metadata
Jan 11, 2020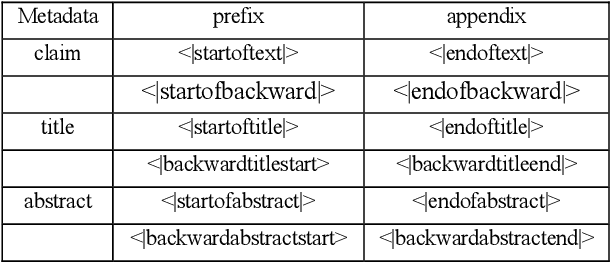
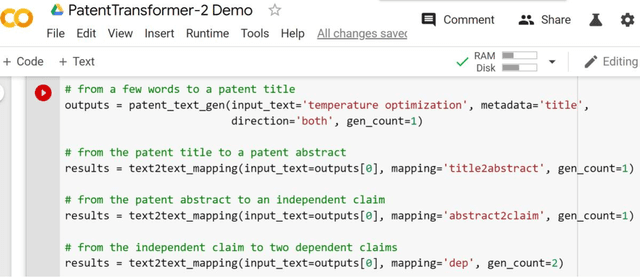

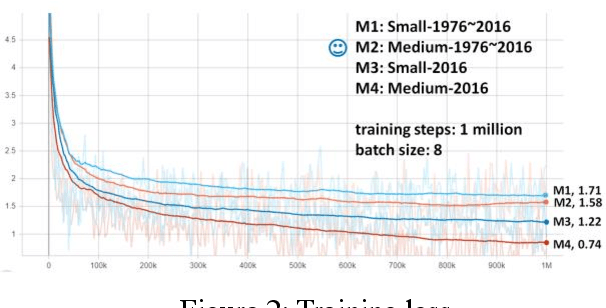
PatentTransformer is our codename for patent text generation based on Transformer-based models. Our goal is "Augmented Inventing." In this second version, we leverage more of the structural metadata in patents. The structural metadata includes patent title, abstract, and dependent claim, in addition to independent claim previously. Metadata controls what kind of patent text for the model to generate. Also, we leverage the relation between metadata to build a text-to-text generation flow, for example, from a few words to a title, the title to an abstract, the abstract to an independent claim, and the independent claim to multiple dependent claims. The text flow can go backward because the relation is trained bidirectionally. We release our GPT-2 models trained from scratch and our code for inference so that readers can verify and generate patent text on their own. As for generation quality, we measure it by both ROUGE and Google Universal Sentence Encoder.
Personalized Patent Claim Generation and Measurement
Dec 12, 2019

This work-in-progress paper proposes a framework to generate and measure personalized patent claims. The objective is to help inventors conceive better inventions by learning from relevant inventors. Patent claim generation is a way of "augmented inventing." for inventors. Such patent claim generation leverages the recent transfer learning in the Deep Learning field, particularly the state-of-the-art Transformer-based models. In terms of system implementa-tion, it is planned to build an "auto-complete" function for patent claim drafting. The auto-complete function is analyzed from four different perspectives: extent of generation, generative direction, proximity of generation, and constraint in generation. Technically, the framework is composed of two Transformer models. One is for text generation and the other is for quality measurement. Specifically, the patent claim generation is based on GPT-2 model and the measurement of personalization is based on BERT model. The training data is inventor-centric and comes from the Inventors Endpoint API provided by the USPTO.
Measuring Patent Claim Generation by Span Relevancy
Aug 26, 2019
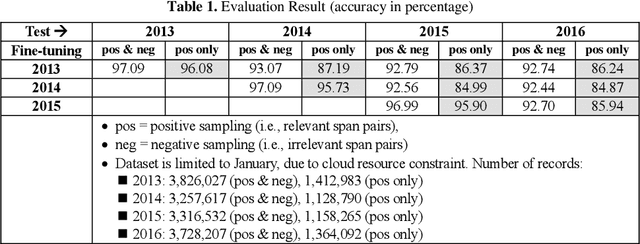
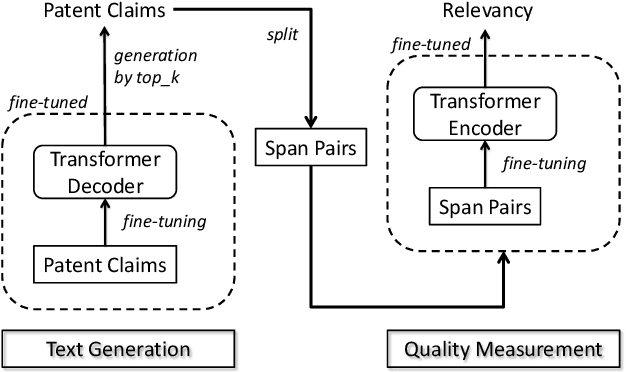
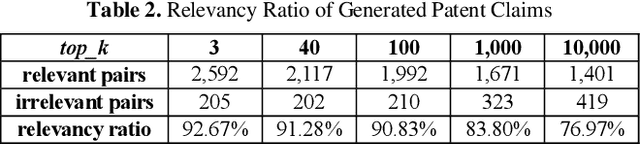
Our goal of patent claim generation is to realize "augmented inventing" for inventors by leveraging latest Deep Learning techniques. We envision the possibility of building an "auto-complete" function for inventors to conceive better inventions in the era of artificial intelligence. In order to generate patent claims with good quality, a fundamental question is how to measure it. We tackle the problem from a perspective of claim span relevancy. Patent claim language was rarely explored in the NLP field. It is unique in its own way and contains rich explicit and implicit human annotations. In this work, we propose a span-based approach and a generic framework to measure patent claim generation quantitatively. In order to study the effectiveness of patent claim generation, we define a metric to measure whether two consecutive spans in a generated patent claims are relevant. We treat such relevancy measurement as a span-pair classification problem, following the concept of natural language inference. Technically, the span-pair classifier is implemented by fine-tuning a pre-trained language model. The patent claim generation is implemented by fine-tuning the other pre-trained model. Specifically, we fine-tune a pre-trained Google BERT model to measure the patent claim spans generated by a fine-tuned OpenAI GPT-2 model. In this way, we re-use two of the state-of-the-art pre-trained models in the NLP field. Our result shows the effectiveness of the span-pair classifier after fine-tuning the pre-trained model. It further validates the quantitative metric of span relevancy in patent claim generation. Particularly, we found that the span relevancy ratio measured by BERT becomes lower when the diversity in GPT-2 text generation becomes higher.
Patent Claim Generation by Fine-Tuning OpenAI GPT-2
Jul 01, 2019
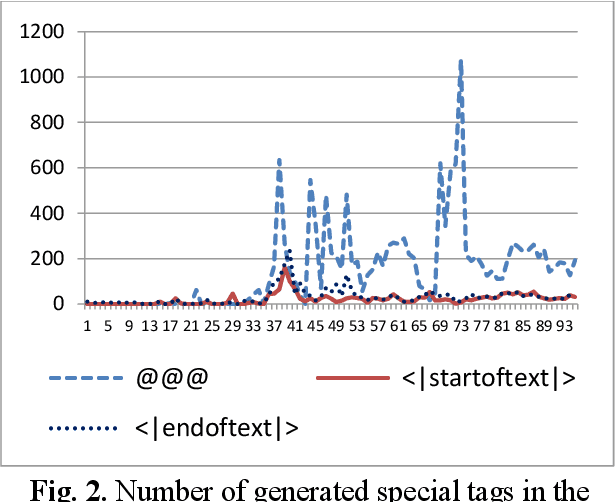
In this work, we focus on fine-tuning an OpenAI GPT-2 pre-trained model for generating patent claims. GPT-2 has demonstrated impressive efficacy of pre-trained language models on various tasks, particularly coherent text generation. Patent claim language itself has rarely been explored in the past and poses a unique challenge. We are motivated to generate coherent patent claims automatically so that augmented inventing might be viable someday. In our implementation, we identified a unique language structure in patent claims and leveraged its implicit human annotations. We investigated the fine-tuning process by probing the first 100 steps and observing the generated text at each step. Based on both conditional and unconditional random sampling, we analyze the overall quality of generated patent claims. Our contributions include: (1) being the first to generate patent claims by machines and being the first to apply GPT-2 to patent claim generation, (2) providing various experiment results for qualitative analysis and future research, (3) proposing a new sampling approach for text generation, and (4) building an e-mail bot for future researchers to explore the fine-tuned GPT-2 model further.
PatentBERT: Patent Classification with Fine-Tuning a pre-trained BERT Model
May 14, 2019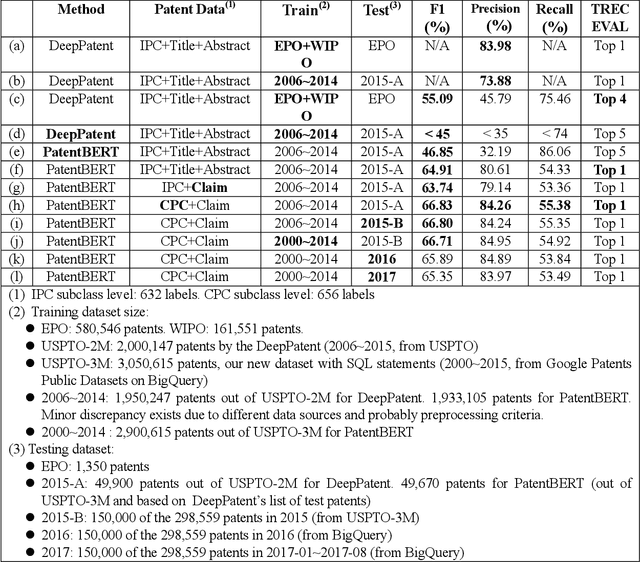
In this work we focus on fine-tuning a pre-trained BERT model and applying it to patent classification. When applied to large datasets of over two millions patents, our approach outperforms the state of the art by an approach using CNN with word embeddings. In addition, we focus on patent claims without other parts in patent documents. Our contributions include: (1) a new state-of-the-art method based on pre-trained BERT model and fine-tuning for patent classification, (2) a large dataset USPTO-3M at the CPC subclass level with SQL statements that can be used by future researchers, (3) showing that patent claims alone are sufficient for classification task, in contrast to conventional wisdom.