 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyler: Typed Latent Reasoning for Language Models -- When to Think, What to Compute, and How Much to Allocate
Jun 15, 2026Chain-of-thought (CoT) prompting improves reasoning in large language models (LLMs) by externalizing intermediate computation as discrete text tokens, but this textual interface also introduces redundancy and inference overhead. Latent reasoning offers a promising alternative by carrying part of the computation in continuous representations. However, existing methods typically predefine when latent computation is invoked and how it is allocated during decoding, leaving a key problem unresolved: when to invoke latent computation, what type of computation to perform, and how much budget to allocate. We propose \textbf{Ty}ped \textbf{L}at\textbf{e}nt \textbf{R}easoning (Tyler), a typed and budget-aware framework for latent reasoning during autoregressive decoding. Tyler learns a policy that, at each decoding step, chooses between emitting a text token and switching to a latent computation module specialized for a particular reasoning function. Once invoked, an operator maps the current reasoning state into latent tokens that support global planning, local state updates, or reusable procedural abstraction. Across extensive experiments on three backbone LLMs, Tyler improves accuracy by up to 14.49 points over CoT and by up to 4.30 points over the strongest competing baseline. It further generalizes across diverse reasoning domains and achieves the best final-stage performance with the lowest forgetting.
Revenue Maximization of Airbnb Marketplace using Search Results
Nov 16, 2019
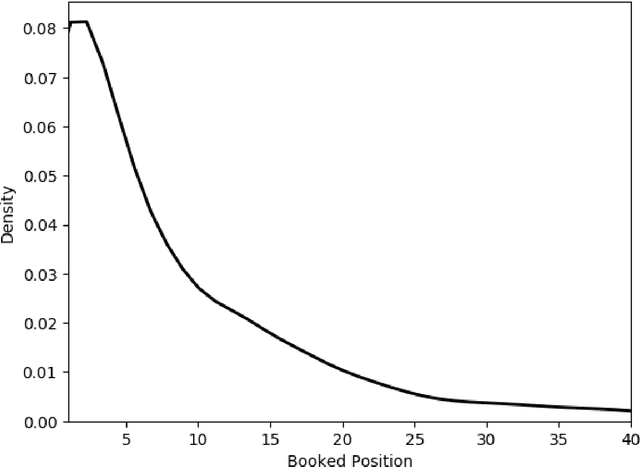
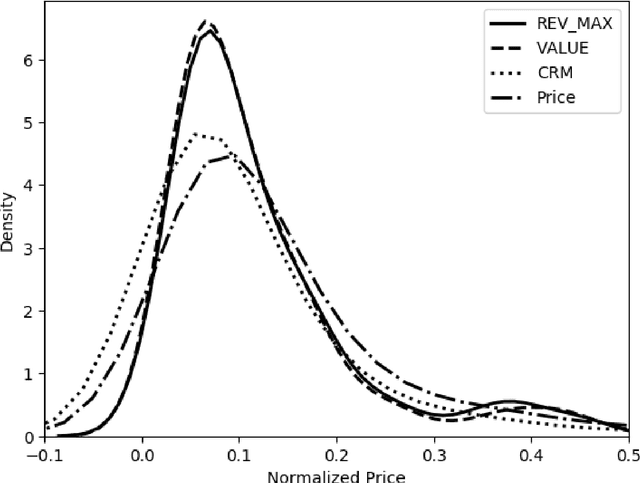
Correctly pricing products or services in an online marketplace presents a challenging problem and one of the critical factors for the success of the business. When users are looking to buy an item they typically search for it. Query relevance models are used at this stage to retrieve and rank the items on the search page from most relevant to least relevant. The presented items are naturally "competing" against each other for user purchases. We provide a practical two-stage model to price this set of retrieved items for which distributions of their values are learned. The initial output of the pricing strategy is a price vector for the top displayed items in one search event. We later aggregate these results over searches to provide the supplier with the optimal price for each item. We applied our solution to large-scale search data obtained from Airbnb Experiences marketplace. Offline evaluation results show that our strategy improves upon baseline pricing strategies on key metrics by at least +20% in terms of booking regret and +55% in terms of revenue potential.
ET-Lasso: Efficient Tuning of Lasso for High-Dimensional Data
Oct 10, 2018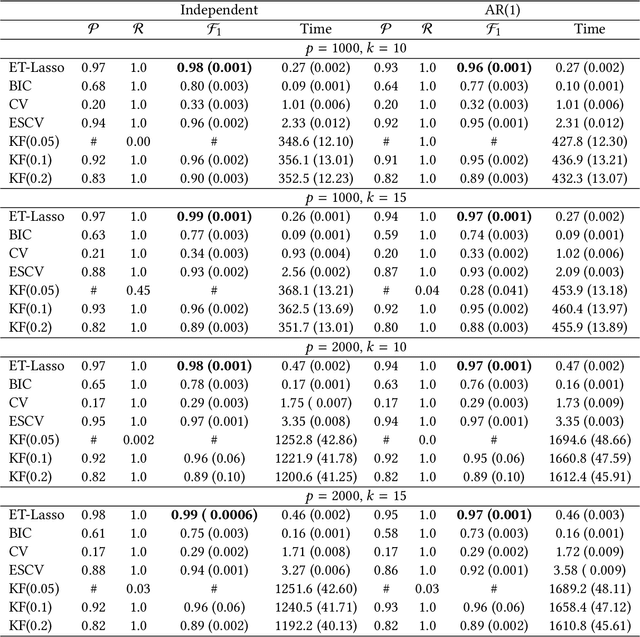
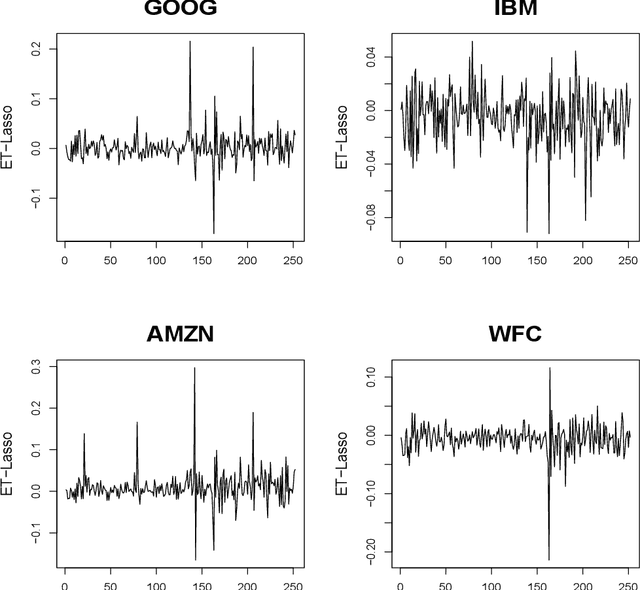
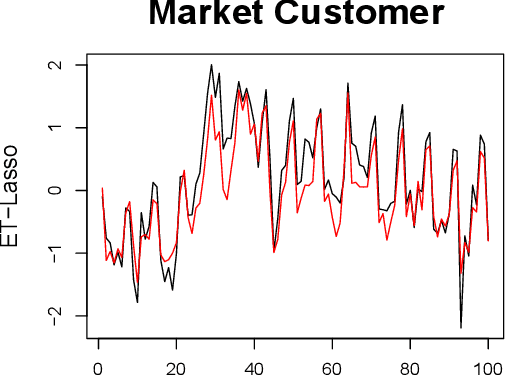
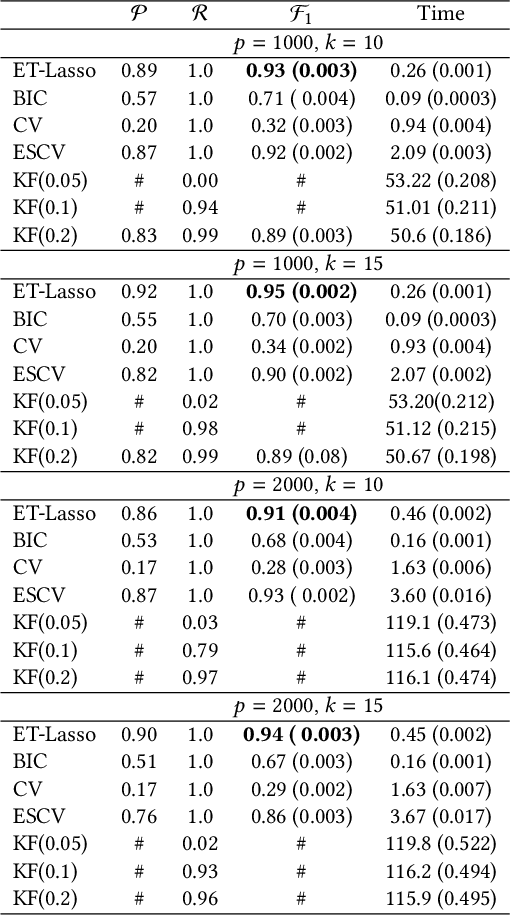
The L1 regularization (Lasso) has proven to be a versatile tool to select relevant features and estimate the model coefficients simultaneously. Despite its popularity, it is very challenging to guarantee the feature selection consistency of Lasso. One way to improve the feature selection consistency is to select an ideal tuning parameter. Traditional tuning criteria mainly focus on minimizing the estimated prediction error or maximizing the posterior model probability, such as cross-validation and BIC, which may either be time-consuming or fail to control the false discovery rate (FDR) when the number of features is extremely large. The other way is to introduce pseudo-features to learn the importance of the original ones. Recently, the Knockoff filter is proposed to control the FDR when performing feature selection. However, its performance is sensitive to the choice of the expected FDR threshold. Motivated by these ideas, we propose a new method using pseudo-features to obtain an ideal tuning parameter. In particular, we present the Efficient Tuning of Lasso (ET-Lasso) to separate active and inactive features by adding permuted features as pseudo-features in linear models. The pseudo-features are constructed to be inactive by nature, which can be used to obtain a cutoff to select the tuning parameter that separates active and inactive features. Experimental studies on both simulations and real-world data applications are provided to show that ET-Lasso can effectively and efficiently select active features under a wide range of different scenarios.