 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional online learning via asynchronous decomposition: Non-divergent results, dynamic regularization, and beyond
Mar 21, 2026Existing high-dimensional online learning methods often face the challenge that their error bounds, or per-batch sample sizes, diverge as the number of data batches increases. To address this issue, we propose an asynchronous decomposition framework that leverages summary statistics to construct a surrogate score function for current-batch learning. This framework is implemented via a dynamic-regularized iterative hard thresholding algorithm, providing a computationally and memory-efficient solution for sparse online optimization. We provide a unified theoretical analysis that accounts for both the streaming computational error and statistical accuracy, establishing that our estimator maintains non-divergent error bounds and $\ell_0$ sparsity across all batches. Furthermore, the proposed estimator adaptively achieves additional gains as batches accumulate, attaining the oracle accuracy as if the entire historical dataset were accessible and the true support were known. These theoretical properties are further illustrated through an example of the generalized linear model.
OrthoDiffusion: A Generalizable Multi-Task Diffusion Foundation Model for Musculoskeletal MRI Interpretation
Feb 24, 2026Musculoskeletal disorders represent a significant global health burden and are a leading cause of disability worldwide. While MRI is essential for accurate diagnosis, its interpretation remains exceptionally challenging. Radiologists must identify multiple potential abnormalities within complex anatomical structures across different imaging planes, a process that requires significant expertise and is prone to variability. We developed OrthoDiffusion, a unified diffusion-based foundation model designed for multi-task musculoskeletal MRI interpretation. The framework utilizes three orientation-specific 3D diffusion models, pre-trained in a self-supervised manner on 15,948 unlabeled knee MRI scans, to learn robust anatomical features from sagittal, coronal, and axial views. These view-specific representations are integrated to support diverse clinical tasks, including anatomical segmentation and multi-label diagnosis. Our evaluation demonstrates that OrthoDiffusion achieves excellent performance in the segmentation of 11 knee structures and the detection of 8 knee abnormalities. The model exhibited remarkable robustness across different clinical centers and MRI field strengths, consistently outperforming traditional supervised models. Notably, in settings where labeled data was scarce, OrthoDiffusion maintained high diagnostic precision using only 10\% of training labels. Furthermore, the anatomical representations learned from knee imaging proved highly transferable to other joints, achieving strong diagnostic performance across 11 diseases of the ankle and shoulder. These findings suggest that diffusion-based foundation models can serve as a unified platform for multi-disease diagnosis and anatomical segmentation, potentially improving the efficiency and accuracy of musculoskeletal MRI interpretation in real-world clinical workflows.
Diffusion-Based Cross-Modal Feature Extraction for Multi-Label Classification
Sep 19, 2025Multi-label classification has broad applications and depends on powerful representations capable of capturing multi-label interactions. We introduce \textit{Diff-Feat}, a simple but powerful framework that extracts intermediate features from pre-trained diffusion-Transformer models for images and text, and fuses them for downstream tasks. We observe that for vision tasks, the most discriminative intermediate feature along the diffusion process occurs at the middle step and is located in the middle block in Transformer. In contrast, for language tasks, the best feature occurs at the noise-free step and is located in the deepest block. In particular, we observe a striking phenomenon across varying datasets: a mysterious "Layer $12$" consistently yields the best performance on various downstream classification tasks for images (under DiT-XL/2-256$\times$256). We devise a heuristic local-search algorithm that pinpoints the locally optimal "image-text"$\times$"block-timestep" pair among a few candidates, avoiding an exhaustive grid search. A simple fusion-linear projection followed by addition-of the selected representations yields state-of-the-art performance: 98.6\% mAP on MS-COCO-enhanced and 45.7\% mAP on Visual Genome 500, surpassing strong CNN, graph, and Transformer baselines by a wide margin. t-SNE and clustering metrics further reveal that \textit{Diff-Feat} forms tighter semantic clusters than unimodal counterparts. The code is available at https://github.com/lt-0123/Diff-Feat.
Modeling High-Dimensional Data with Unknown Cut Points: A Fusion Penalized Logistic Threshold Regression
Feb 17, 2022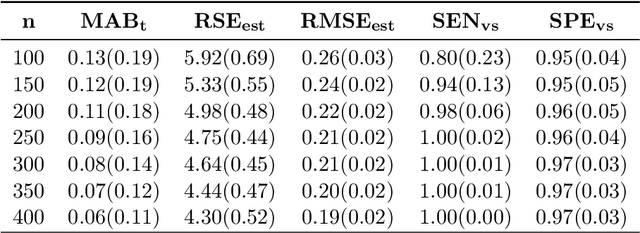
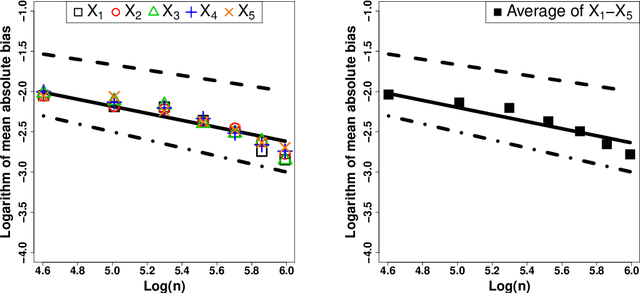
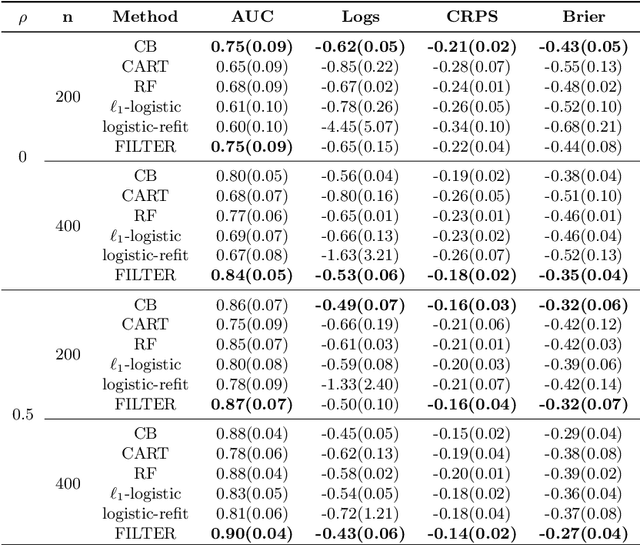
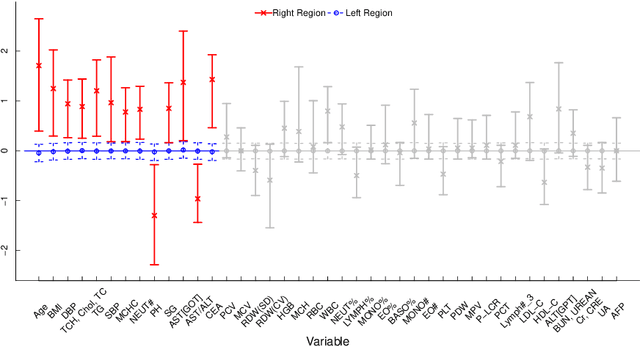
In traditional logistic regression models, the link function is often assumed to be linear and continuous in predictors. Here, we consider a threshold model that all continuous features are discretized into ordinal levels, which further determine the binary responses. Both the threshold points and regression coefficients are unknown and to be estimated. For high dimensional data, we propose a fusion penalized logistic threshold regression (FILTER) model, where a fused lasso penalty is employed to control the total variation and shrink the coefficients to zero as a method of variable selection. Under mild conditions on the estimate of unknown threshold points, we establish the non-asymptotic error bound for coefficient estimation and the model selection consistency. With a careful characterization of the error propagation, we have also shown that the tree-based method, such as CART, fulfill the threshold estimation conditions. We find the FILTER model is well suited in the problem of early detection and prediction for chronic disease like diabetes, using physical examination data. The finite sample behavior of our proposed method are also explored and compared with extensive Monte Carlo studies, which supports our theoretical discoveries.