 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Feature Mapping for 6DoF Object Pose Estimation
Jun 03, 2022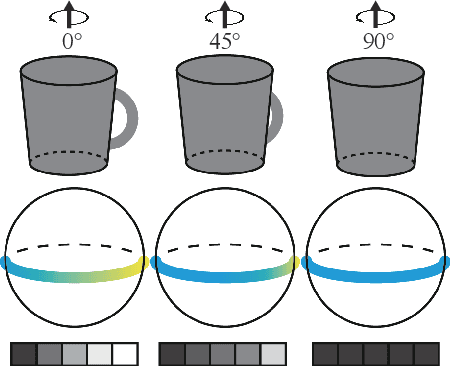
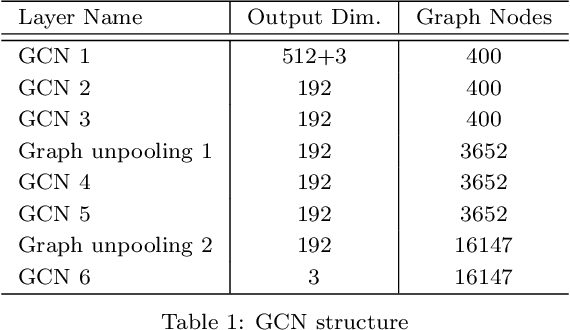
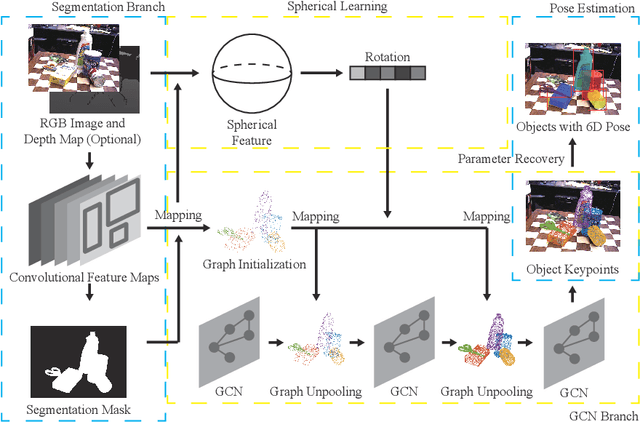
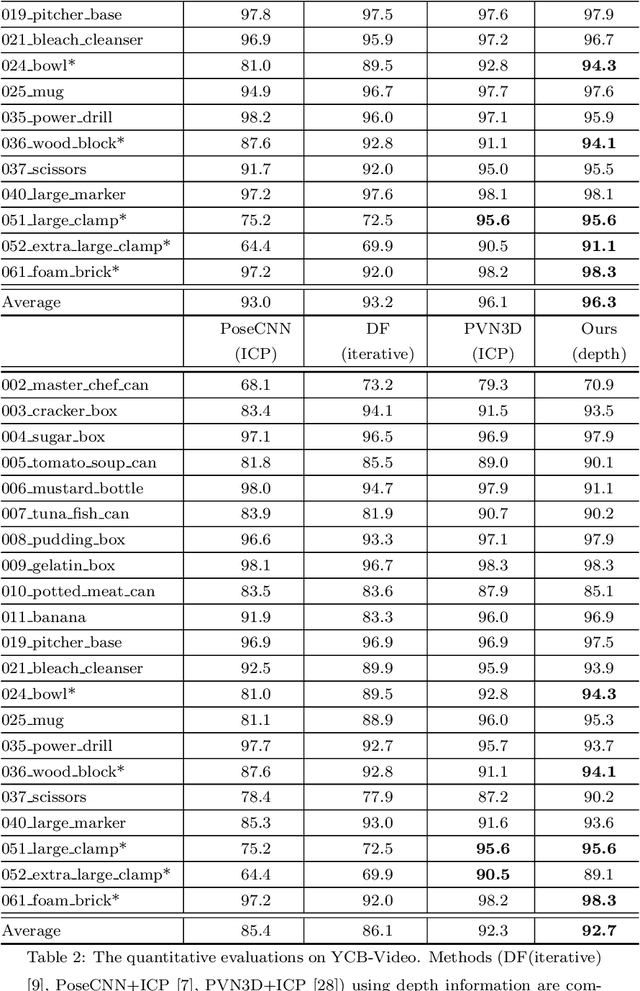
This work aims to estimate 6Dof (6D) object pose in background clutter. Considering the strong occlusion and background noise, we propose to utilize the spatial structure for better tackling this challenging task. Observing that the 3D mesh can be naturally abstracted by a graph, we build the graph using 3D points as vertices and mesh connections as edges. We construct the corresponding mapping from 2D image features to 3D points for filling the graph and fusion of the 2D and 3D features. Afterward, a Graph Convolutional Network (GCN) is applied to help the feature exchange among objects' points in 3D space. To address the problem of rotation symmetry ambiguity for objects, a spherical convolution is utilized and the spherical features are combined with the convolutional features that are mapped to the graph. Predefined 3D keypoints are voted and the 6DoF pose is obtained via the fitting optimization. Two scenarios of inference, one with the depth information and the other without it are discussed. Tested on the datasets of YCB-Video and LINEMOD, the experiments demonstrate the effectiveness of our proposed method.
Object 6D Pose Estimation with Non-local Attention
Feb 20, 2020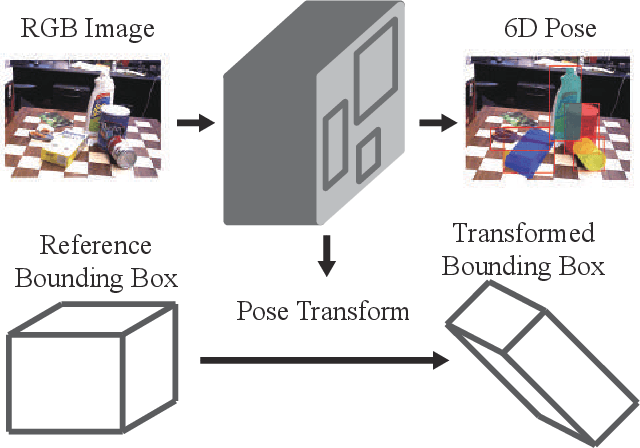
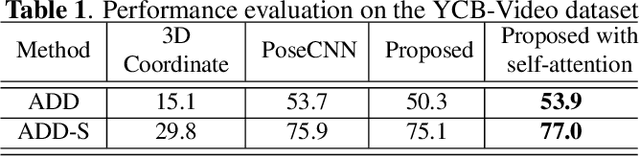

In this paper, we address the challenging task of estimating 6D object pose from a single RGB image. Motivated by the deep learning based object detection methods, we propose a concise and efficient network that integrate 6D object pose parameter estimation into the object detection framework. Furthermore, for more robust estimation to occlusion, a non-local self-attention module is introduced. The experimental results show that the proposed method reaches the state-of-the-art performance on the YCB-video and the Linemod datasets.