 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D UAV Trajectory Estimation and Classification from Internet Videos via Language Model
Mar 10, 2026Reliable 3D trajectory estimation of unmanned aerial vehicles (UAVs) is a fundamental requirement for anti-UAV systems, yet the acquisition of large-scale and accurately annotated trajectory data remains prohibitively expensive. In this work, we present a novel framework that derives UAV 3D trajectories and category information directly from Internet-scale UAV videos, without relying on manual annotations. First, language-driven data acquisition is employed to autonomously discover and collect UAV-related videos, while vision-language reasoning progressively filters task-relevant segments. Second, a training-free cross-modal label generation module is introduced to infer 3D trajectory hypotheses and UAV type cues. Third, a physics-informed refinement process is designed to impose temporal smoothness and kinematic consistency on the estimated trajectories. The resulting video clips and trajectory annotations can be readily utilized for downstream anti-UAV tasks. To assess effectiveness and generalization, we conduct zero-shot transfer experiments on a public, well-annotated 3D UAV benchmark. Results reveal a clear data scaling behavior: as the amount of online video data increases, zero-shot transfer performance on the target dataset improves consistently, without any target-domain training. The proposed method closely approaches the current state-of-the-art, highlighting its robustness and applicability to real-world anti-UAV scenarios. Code and datasets will be released upon acceptance.
Two-stream Network for ECG Signal Classification
Oct 05, 2022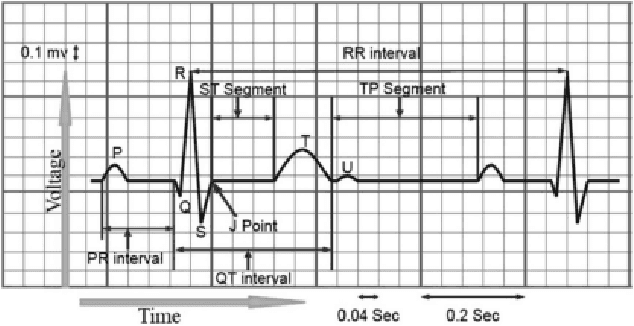

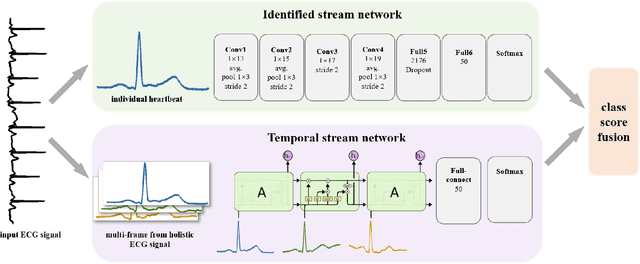
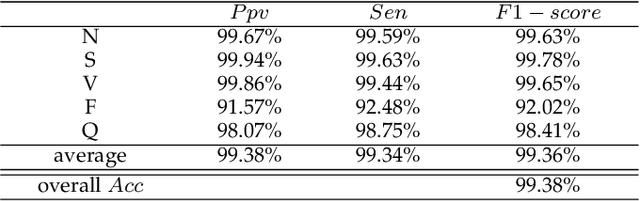
Electrocardiogram (ECG), a technique for medical monitoring of cardiac activity, is an important method for identifying cardiovascular disease. However, analyzing the increasing quantity of ECG data consumes a lot of medical resources. This paper explores an effective algorithm for automatic classifications of multi-classes of heartbeat types based on ECG. Most neural network based methods target the individual heartbeats, ignoring the secrets embedded in the temporal sequence. And the ECG signal has temporal variation and unique individual characteristics, which means that the same type of ECG signal varies among patients under different physical conditions. A two-stream architecture is used in this paper and presents an enhanced version of ECG recognition based on this. The architecture achieves classification of holistic ECG signal and individual heartbeat and incorporates identified and temporal stream networks. Identified networks are used to extract features of individual heartbeats, while temporal networks aim to extract temporal correlations between heartbeats. Results on the MIT-BIH Arrhythmia Database demonstrate that the proposed algorithm performs an accuracy of 99.38\%. In addition, the proposed algorithm reaches an 88.07\% positive accuracy on massive data in real life, showing that the proposed algorithm can efficiently categorize different classes of heartbeat with high diagnostic performance.
ViLiVO: Virtual LiDAR-Visual Odometry for an Autonomous Vehicle with a Multi-Camera System
Sep 30, 2019
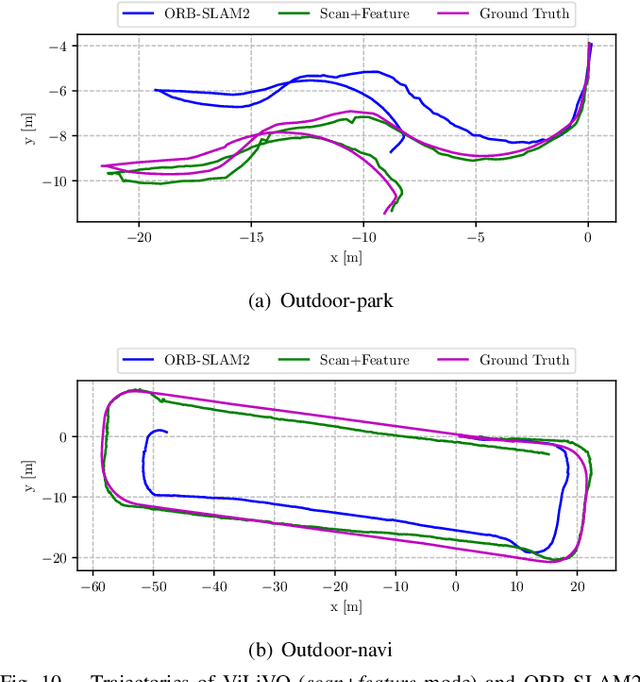
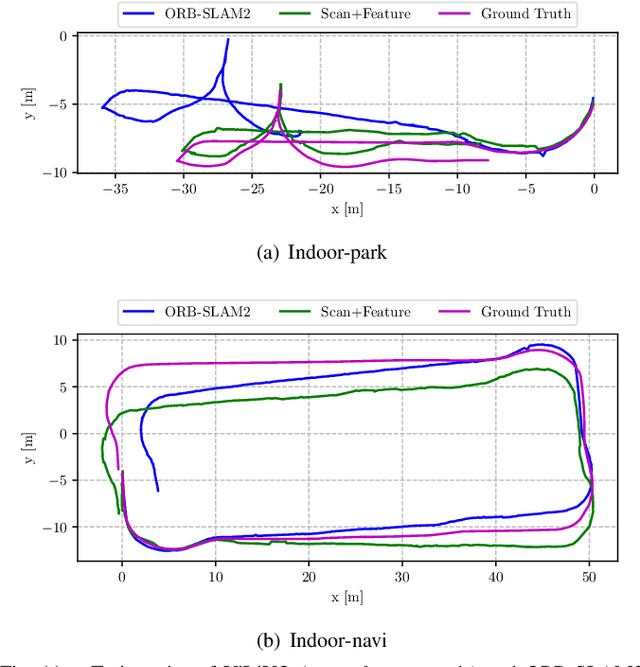
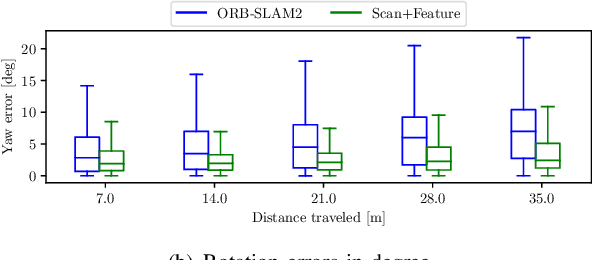
In this paper, we present a multi-camera visual odometry (VO) system for an autonomous vehicle. Our system mainly consists of a virtual LiDAR and a pose tracker. We use a perspective transformation method to synthesize a surround-view image from undistorted fisheye camera images. With a semantic segmentation model, the free space can be extracted. The scans of the virtual LiDAR are generated by discretizing the contours of the free space. As for the pose tracker, we propose a visual odometry system fusing both the feature matching and the virtual LiDAR scan matching results. Only those feature points located in the free space area are utilized to ensure the 2D-2D matching for pose estimation. Furthermore, bundle adjustment (BA) is performed to minimize the feature points reprojection error and scan matching error. We apply our system to an autonomous vehicle equipped with four fisheye cameras. The testing scenarios include an outdoor parking lot as well as an indoor garage. Experimental results demonstrate that our system achieves a more robust and accurate performance comparing with a fisheye camera based monocular visual odometry system.
Boosting Real-Time Driving Scene Parsing with Shared Semantics
Sep 25, 2019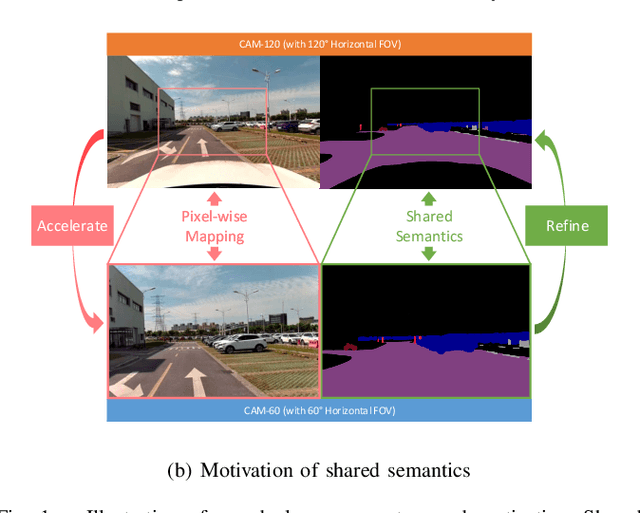
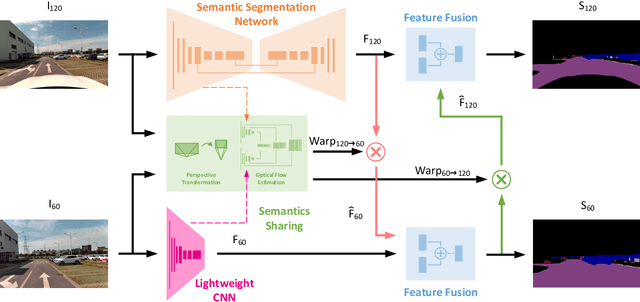
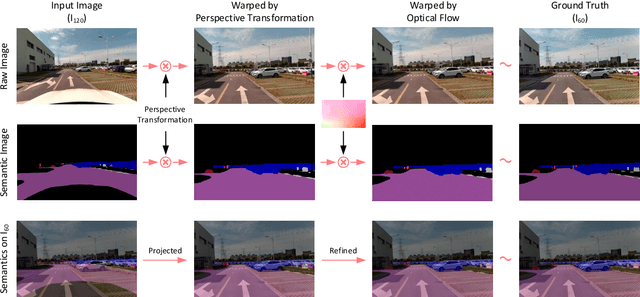
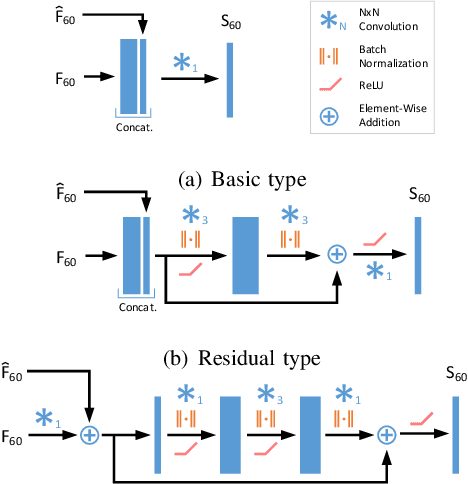
Real-time scene parsing is a fundamental feature for autonomous driving vehicles with multiple cameras. Comparing with traditional methods which individually process the frames from each camera, in this letter we demonstrate that sharing semantics between cameras with overlapped views can boost the parsing performance. Our framework is based on a deep neural network for semantic segmentation but with two kinds of additional modules for sharing and fusing semantics. On one hand, a semantics sharing module is designed to establish the pixel-wise mapping between the input image pair. Features as well as semantics are shared by the map to reduce duplicated workload which leads to more efficient computation. On the other hand, feature fusion modules are designed to combine different modal of semantic features, which learns to leverage the information from both inputs for better results. To evaluate the effectiveness of the proposed framework, we collect a new dataset with a dual-camera vision system for driving scene parsing. Experimental results show that our network outperforms the baseline method on the parsing accuracy with comparable computations.