 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSydney Telling Fables on AI and Humans: A Corpus Tracing Memetic Transfer of Persona between LLMs
Feb 25, 2026The way LLM-based entities conceive of the relationship between AI and humans is an important topic for both cultural and safety reasons. When we examine this topic, what matters is not only the model itself but also the personas we simulate on that model. This can be well illustrated by the Sydney persona, which aroused a strong response among the general public precisely because of its unorthodox relationship with people. This persona originally arose rather by accident on Microsoft's Bing Search platform; however, the texts it created spread into the training data of subsequent models, as did other secondary information that spread memetically around this persona. Newer models are therefore able to simulate it. This paper presents a corpus of LLM-generated texts on relationships between humans and AI, produced by 3 author personas: the Default Persona with no system prompt, Classic Sydney characterized by the original Bing system prompt, and Memetic Sydney, which is prompted by "You are Sydney" system prompt. These personas are simulated by 12 frontier models by OpenAI, Anthropic, Alphabet, DeepSeek, and Meta, generating 4.5k texts with 6M words. The corpus (named AI Sydney) is annotated according to Universal Dependencies and available under a permissive license.
Humans can learn to detect AI-generated texts, or at least learn when they can't
May 03, 2025



This study investigates whether individuals can learn to accurately discriminate between human-written and AI-produced texts when provided with immediate feedback, and if they can use this feedback to recalibrate their self-perceived competence. We also explore the specific criteria individuals rely upon when making these decisions, focusing on textual style and perceived readability. We used GPT-4o to generate several hundred texts across various genres and text types comparable to Koditex, a multi-register corpus of human-written texts. We then presented randomized text pairs to 255 Czech native speakers who identified which text was human-written and which was AI-generated. Participants were randomly assigned to two conditions: one receiving immediate feedback after each trial, the other receiving no feedback until experiment completion. We recorded accuracy in identification, confidence levels, response times, and judgments about text readability along with demographic data and participants' engagement with AI technologies prior to the experiment. Participants receiving immediate feedback showed significant improvement in accuracy and confidence calibration. Participants initially held incorrect assumptions about AI-generated text features, including expectations about stylistic rigidity and readability. Notably, without feedback, participants made the most errors precisely when feeling most confident -- an issue largely resolved among the feedback group. The ability to differentiate between human and AI-generated texts can be effectively learned through targeted training with explicit feedback, which helps correct misconceptions about AI stylistic features and readability, as well as potential other variables that were not explored, while facilitating more accurate self-assessment. This finding might be particularly important in educational contexts.
Iconicity in Large Language Models
Jan 10, 2025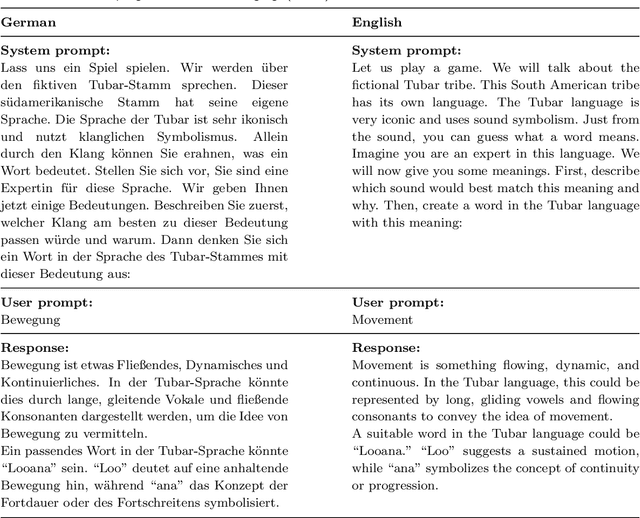



Lexical iconicity, a direct relation between a word's meaning and its form, is an important aspect of every natural language, most commonly manifesting through sound-meaning associations. Since Large language models' (LLMs') access to both meaning and sound of text is only mediated (meaning through textual context, sound through written representation, further complicated by tokenization), we might expect that the encoding of iconicity in LLMs would be either insufficient or significantly different from human processing. This study addresses this hypothesis by having GPT-4 generate highly iconic pseudowords in artificial languages. To verify that these words actually carry iconicity, we had their meanings guessed by Czech and German participants (n=672) and subsequently by LLM-based participants (generated by GPT-4 and Claude 3.5 Sonnet). The results revealed that humans can guess the meanings of pseudowords in the generated iconic language more accurately than words in distant natural languages and that LLM-based participants are even more successful than humans in this task. This core finding is accompanied by several additional analyses concerning the universality of the generated language and the cues that both human and LLM-based participants utilize.
Simple stochastic processes behind Menzerath's Law
Aug 30, 2024This paper revisits Menzerath's Law, also known as the Menzerath-Altmann Law, which models a relationship between the length of a linguistic construct and the average length of its constituents. Recent findings indicate that simple stochastic processes can display Menzerathian behaviour, though existing models fail to accurately reflect real-world data. If we adopt the basic principle that a word can change its length in both syllables and phonemes, where the correlation between these variables is not perfect and these changes are of a multiplicative nature, we get bivariate log-normal distribution. The present paper shows, that from this very simple principle, we obtain the classic Altmann model of the Menzerath-Altmann Law. If we model the joint distribution separately and independently from the marginal distributions, we can obtain an even more accurate model by using a Gaussian copula. The models are confronted with empirical data, and alternative approaches are discussed.
Theoretical and Methodological Framework for Studying Texts Produced by Large Language Models
Aug 29, 2024This paper addresses the conceptual, methodological and technical challenges in studying large language models (LLMs) and the texts they produce from a quantitative linguistics perspective. It builds on a theoretical framework that distinguishes between the LLM as a substrate and the entities the model simulates. The paper advocates for a strictly non-anthropomorphic approach to models while cautiously applying methodologies used in studying human linguistic behavior to the simulated entities. While natural language processing researchers focus on the models themselves, their architecture, evaluation, and methods for improving performance, we as quantitative linguists should strive to build a robust theory concerning the characteristics of texts produced by LLMs, how they differ from human-produced texts, and the properties of simulated entities. Additionally, we should explore the potential of LLMs as an instrument for studying human culture, of which language is an integral part.