 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompeting Risks: Impact on Risk Estimation and Algorithmic Fairness
Aug 07, 2025Accurate time-to-event prediction is integral to decision-making, informing medical guidelines, hiring decisions, and resource allocation. Survival analysis, the quantitative framework used to model time-to-event data, accounts for patients who do not experience the event of interest during the study period, known as censored patients. However, many patients experience events that prevent the observation of the outcome of interest. These competing risks are often treated as censoring, a practice frequently overlooked due to a limited understanding of its consequences. Our work theoretically demonstrates why treating competing risks as censoring introduces substantial bias in survival estimates, leading to systematic overestimation of risk and, critically, amplifying disparities. First, we formalize the problem of misclassifying competing risks as censoring and quantify the resulting error in survival estimates. Specifically, we develop a framework to estimate this error and demonstrate the associated implications for predictive performance and algorithmic fairness. Furthermore, we examine how differing risk profiles across demographic groups lead to group-specific errors, potentially exacerbating existing disparities. Our findings, supported by an empirical analysis of cardiovascular management, demonstrate that ignoring competing risks disproportionately impacts the individuals most at risk of these events, potentially accentuating inequity. By quantifying the error and highlighting the fairness implications of the common practice of considering competing risks as censoring, our work provides a critical insight into the development of survival models: practitioners must account for competing risks to improve accuracy, reduce disparities in risk assessment, and better inform downstream decisions.
Prediction of Survival Outcomes under Clinical Presence Shift: A Joint Neural Network Architecture
Aug 07, 2025Electronic health records arise from the complex interaction between patients and the healthcare system. This observation process of interactions, referred to as clinical presence, often impacts observed outcomes. When using electronic health records to develop clinical prediction models, it is standard practice to overlook clinical presence, impacting performance and limiting the transportability of models when this interaction evolves. We propose a multi-task recurrent neural network that jointly models the inter-observation time and the missingness processes characterising this interaction in parallel to the survival outcome of interest. Our work formalises the concept of clinical presence shift when the prediction model is deployed in new settings (e.g. different hospitals, regions or countries), and we theoretically justify why the proposed joint modelling can improve transportability under changes in clinical presence. We demonstrate, in a real-world mortality prediction task in the MIMIC-III dataset, how the proposed strategy improves performance and transportability compared to state-of-the-art prediction models that do not incorporate the observation process. These results emphasise the importance of leveraging clinical presence to improve performance and create more transportable clinical prediction models.
Identifying treatment response subgroups in observational time-to-event data
Aug 06, 2024



Identifying patient subgroups with different treatment responses is an important task to inform medical recommendations, guidelines, and the design of future clinical trials. Existing approaches for subgroup analysis primarily focus on Randomised Controlled Trials (RCTs), in which treatment assignment is randomised. Furthermore, the patient cohort of an RCT is often constrained by cost, and is not representative of the heterogeneity of patients likely to receive treatment in real-world clinical practice. Therefore, when applied to observational studies, such approaches suffer from significant statistical biases because of the non-randomisation of treatment. Our work introduces a novel, outcome-guided method for identifying treatment response subgroups in observational studies. Our approach assigns each patient to a subgroup associated with two time-to-event distributions: one under treatment and one under control regime. It hence positions itself in between individualised and average treatment effect estimation. The assumptions of our model result in a simple correction of the statistical bias from treatment non-randomisation through inverse propensity weighting. In experiments, our approach significantly outperforms the current state-of-the-art method for outcome-guided subgroup analysis in both randomised and observational treatment regimes.
Neural Fine-Gray: Monotonic neural networks for competing risks
May 11, 2023Time-to-event modelling, known as survival analysis, differs from standard regression as it addresses censoring in patients who do not experience the event of interest. Despite competitive performances in tackling this problem, machine learning methods often ignore other competing risks that preclude the event of interest. This practice biases the survival estimation. Extensions to address this challenge often rely on parametric assumptions or numerical estimations leading to sub-optimal survival approximations. This paper leverages constrained monotonic neural networks to model each competing survival distribution. This modelling choice ensures the exact likelihood maximisation at a reduced computational cost by using automatic differentiation. The effectiveness of the solution is demonstrated on one synthetic and three medical datasets. Finally, we discuss the implications of considering competing risks when developing risk scores for medical practice.
Imputation Strategies Under Clinical Presence: Impact on Algorithmic Fairness
Aug 13, 2022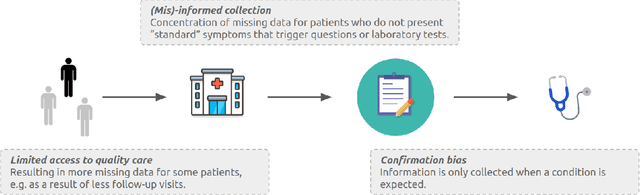
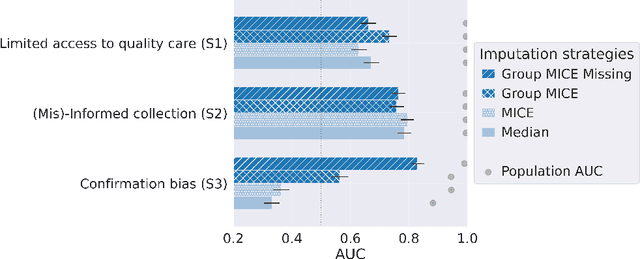
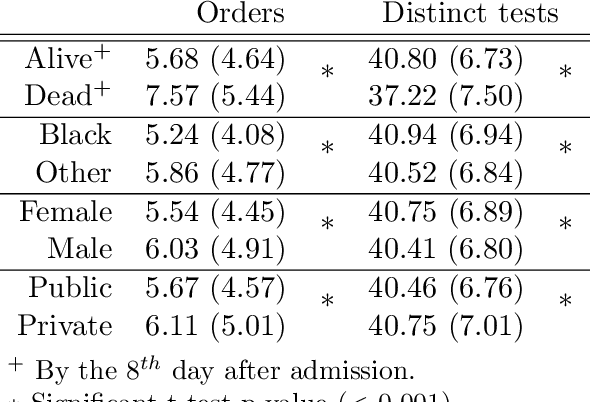
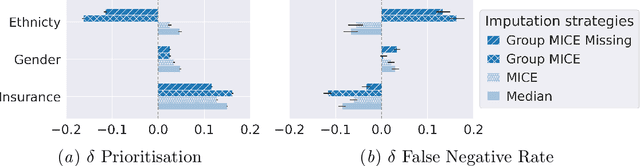
Biases have marked medical history, leading to unequal care affecting marginalised groups. The patterns of missingness in observational data often reflect these group discrepancies, but the algorithmic fairness implications of group-specific missingness are not well understood. Despite its potential impact, imputation is too often a forgotten preprocessing step. At best, practitioners guide imputation choice by optimising overall performance, ignoring how this preprocessing can reinforce inequities. Our work questions this choice by studying how imputation affects downstream algorithmic fairness. First, we provide a structured view of the relationship between clinical presence mechanisms and group-specific missingness patterns. Then, through simulations and real-world experiments, we demonstrate that the imputation choice influences marginalised group performance and that no imputation strategy consistently reduces disparities. Importantly, our results show that current practices may endanger health equity as similarly performing imputation strategies at the population level can affect marginalised groups in different ways. Finally, we propose recommendations for mitigating inequity stemming from a neglected step of the machine learning pipeline.
DeepJoint: Robust Survival Modelling Under Clinical Presence Shift
May 26, 2022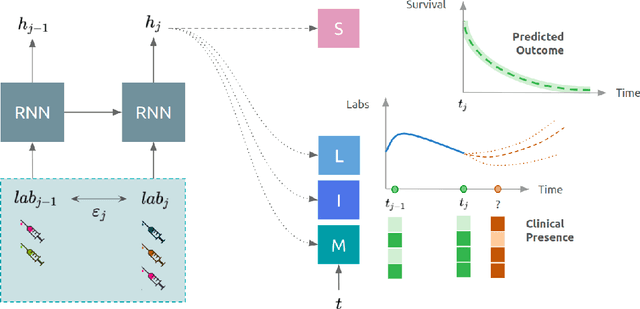
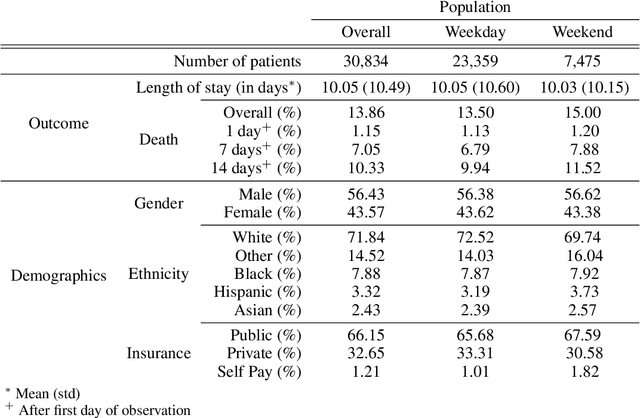
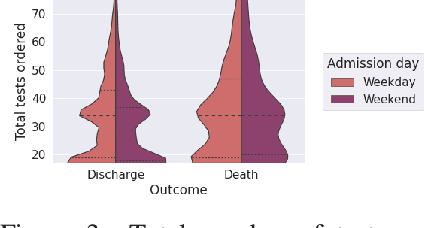
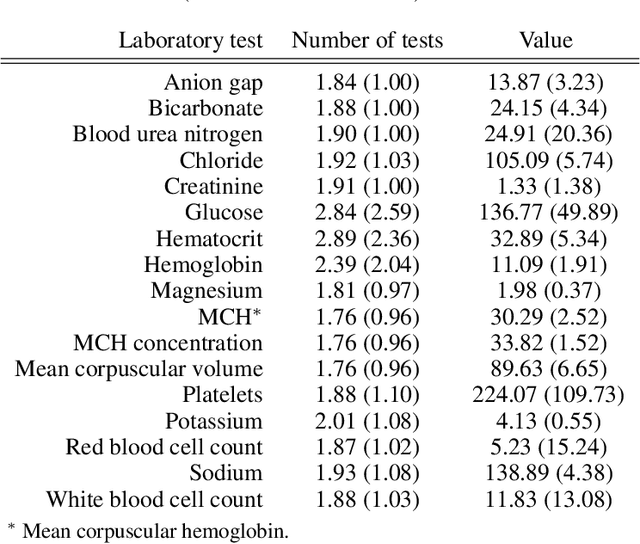
Observational data in medicine arise as a result of the complex interaction between patients and the healthcare system. The sampling process is often highly irregular and itself constitutes an informative process. When using such data to develop prediction models, this phenomenon is often ignored, leading to sub-optimal performance and generalisability of models when practices evolve. We propose a multi-task recurrent neural network which models three clinical presence dimensions -- namely the longitudinal, the inter-observation and the missingness processes -- in parallel to the survival outcome. On a prediction task using MIMIC III laboratory tests, explicit modelling of these three processes showed improved performance in comparison to state-of-the-art predictive models (C-index at 1 day horizon: 0.878). More importantly, the proposed approach was more robust to change in the clinical presence setting, demonstrated by performance comparison between patients admitted on weekdays and weekends. This analysis demonstrates the importance of studying and leveraging clinical presence to improve performance and create more transportable clinical models.