 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian inference for logistic models using Polya-Gamma latent variables
Jul 22, 2013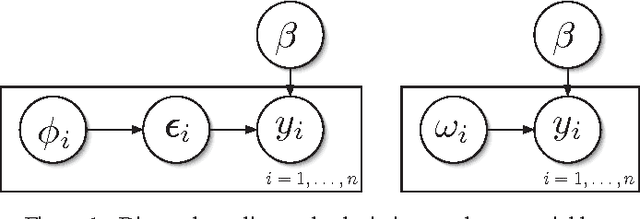
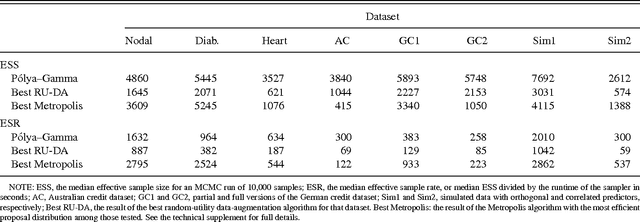
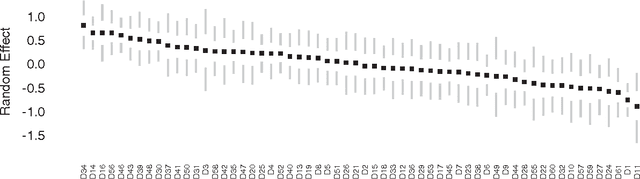
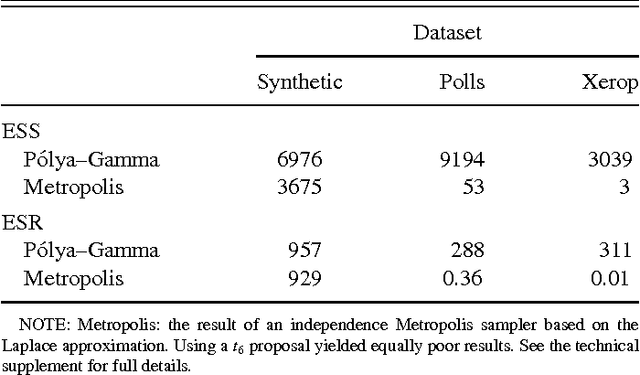
We propose a new data-augmentation strategy for fully Bayesian inference in models with binomial likelihoods. The approach appeals to a new class of Polya-Gamma distributions, which are constructed in detail. A variety of examples are presented to show the versatility of the method, including logistic regression, negative binomial regression, nonlinear mixed-effects models, and spatial models for count data. In each case, our data-augmentation strategy leads to simple, effective methods for posterior inference that: (1) circumvent the need for analytic approximations, numerical integration, or Metropolis-Hastings; and (2) outperform other known data-augmentation strategies, both in ease of use and in computational efficiency. All methods, including an efficient sampler for the Polya-Gamma distribution, are implemented in the R package BayesLogit. In the technical supplement appended to the end of the paper, we provide further details regarding the generation of Polya-Gamma random variables; the empirical benchmarks reported in the main manuscript; and the extension of the basic data-augmentation framework to contingency tables and multinomial outcomes.
The Bayesian Bridge
Oct 27, 2012



We propose the Bayesian bridge estimator for regularized regression and classification. Two key mixture representations for the Bayesian bridge model are developed: (1) a scale mixture of normals with respect to an alpha-stable random variable; and (2) a mixture of Bartlett--Fejer kernels (or triangle densities) with respect to a two-component mixture of gamma random variables. Both lead to MCMC methods for posterior simulation, and these methods turn out to have complementary domains of maximum efficiency. The first representation is a well known result due to West (1987), and is the better choice for collinear design matrices. The second representation is new, and is more efficient for orthogonal problems, largely because it avoids the need to deal with exponentially tilted stable random variables. It also provides insight into the multimodality of the joint posterior distribution, a feature of the bridge model that is notably absent under ridge or lasso-type priors. We prove a theorem that extends this representation to a wider class of densities representable as scale mixtures of betas, and provide an explicit inversion formula for the mixing distribution. The connections with slice sampling and scale mixtures of normals are explored. On the practical side, we find that the Bayesian bridge model outperforms its classical cousin in estimation and prediction across a variety of data sets, both simulated and real. We also show that the MCMC for fitting the bridge model exhibits excellent mixing properties, particularly for the global scale parameter. This makes for a favorable contrast with analogous MCMC algorithms for other sparse Bayesian models. All methods described in this paper are implemented in the R package BayesBridge. An extensive set of simulation results are provided in two supplemental files.