 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Mathematics Problems into Games: Reinforcement Learning and Gröbner bases together solve Integer Feasibility Problems
Aug 25, 2022
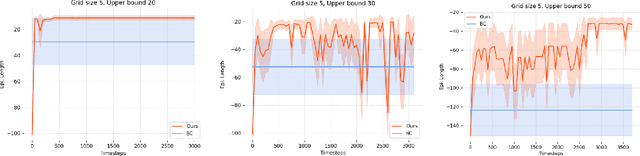
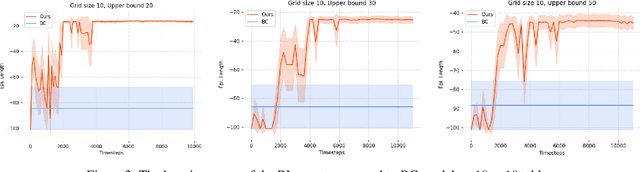
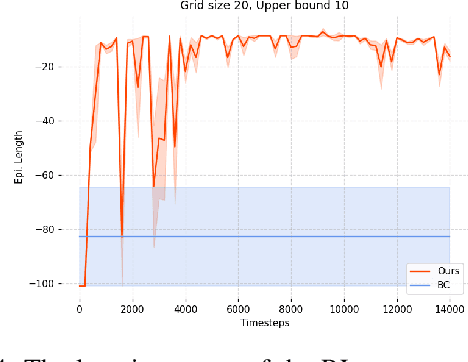
Can agents be trained to answer difficult mathematical questions by playing a game? We consider the integer feasibility problem, a challenge of deciding whether a system of linear equations and inequalities has a solution with integer values. This is a famous NP-complete problem with applications in many areas of Mathematics and Computer Science. Our paper describes a novel algebraic reinforcement learning framework that allows an agent to play a game equivalent to the integer feasibility problem. We explain how to transform the integer feasibility problem into a game over a set of arrays with fixed margin sums. The game starts with an initial state (an array), and by applying a legal move that leaves the margins unchanged, we aim to eventually reach a winning state with zeros in specific positions. To win the game the player must find a path between the initial state and a final terminal winning state if one exists. Finding such a winning state is equivalent to solving the integer feasibility problem. The key algebraic ingredient is a Gr\"obner basis of the toric ideal for the underlying axial transportation polyhedron. The Gr\"obner basis can be seen as a set of connecting moves (actions) of the game. We then propose a novel RL approach that trains an agent to predict moves in continuous space to cope with the large size of action space. The continuous move is then projected onto the set of legal moves so that the path always leads to valid states. As a proof of concept we demonstrate in experiments that our agent can play well the simplest version of our game for 2-way tables. Our work highlights the potential to train agents to solve non-trivial mathematical queries through contemporary machine learning methods used to train agents to play games.
Geometric Policy Iteration for Markov Decision Processes
Jun 12, 2022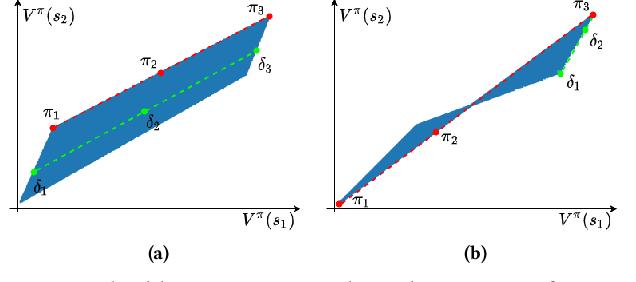
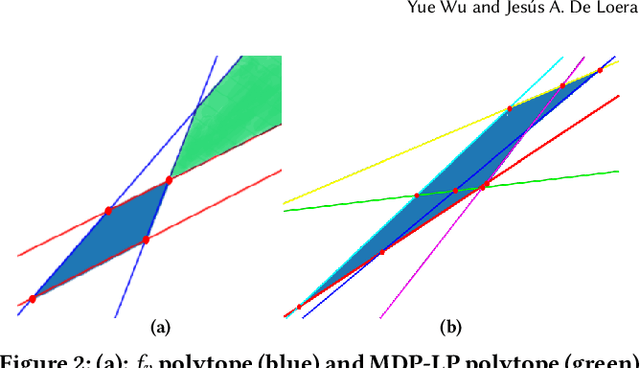
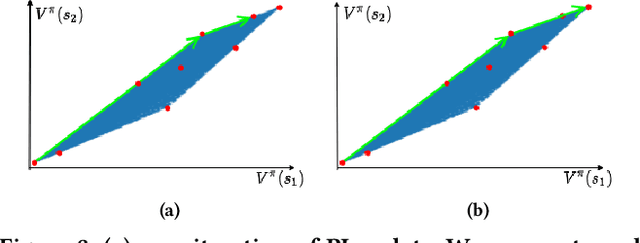
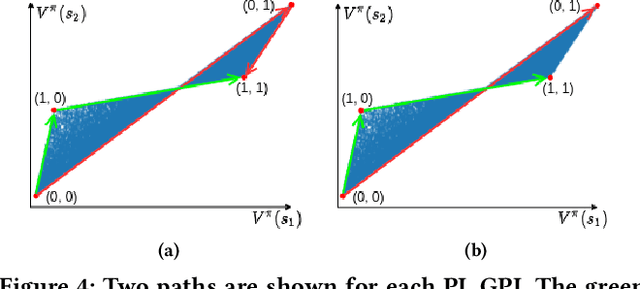
Recently discovered polyhedral structures of the value function for finite state-action discounted Markov decision processes (MDP) shed light on understanding the success of reinforcement learning. We investigate the value function polytope in greater detail and characterize the polytope boundary using a hyperplane arrangement. We further show that the value space is a union of finitely many cells of the same hyperplane arrangement and relate it to the polytope of the classical linear programming formulation for MDPs. Inspired by these geometric properties, we propose a new algorithm, \emph{Geometric Policy Iteration} (GPI), to solve discounted MDPs. GPI updates the policy of a single state by switching to an action that is mapped to the boundary of the value function polytope, followed by an immediate update of the value function. This new update rule aims at a faster value improvement without compromising computational efficiency. Moreover, our algorithm allows asynchronous updates of state values which is more flexible and advantageous compared to traditional policy iteration when the state set is large. We prove that the complexity of GPI achieves the best known bound $\bigO{\frac{|\actions|}{1 - \gamma}\log \frac{1}{1-\gamma}}$ of policy iteration and empirically demonstrate the strength of GPI on MDPs of various sizes.