 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical applicability of deep neural networks for overlapping speaker separation
Dec 19, 2019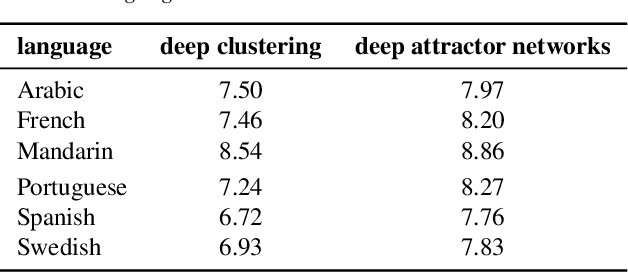
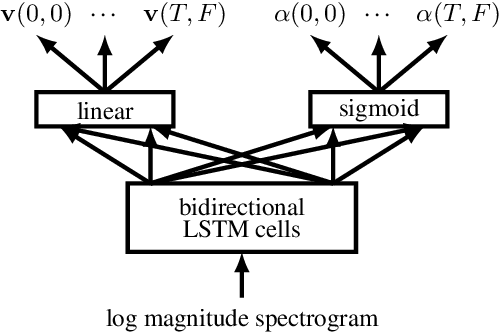
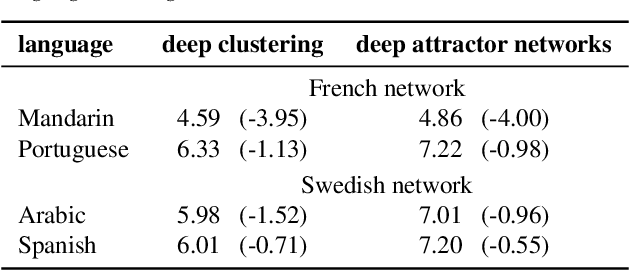
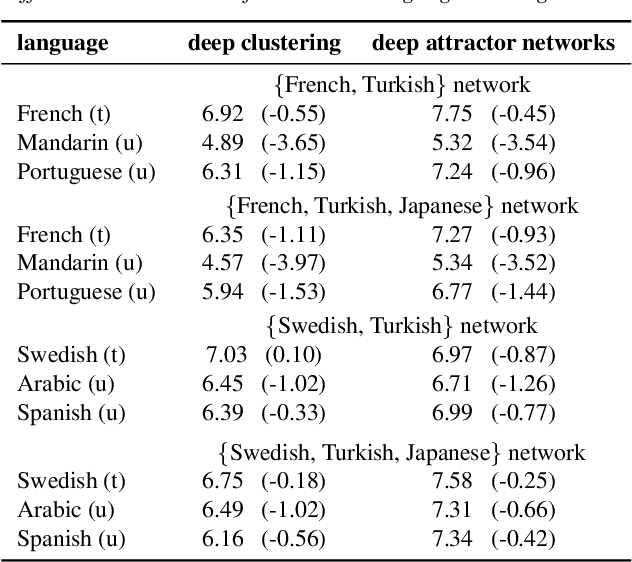
This paper examines the applicability in realistic scenarios of two deep learning based solutions to the overlapping speaker separation problem. Firstly, we present experiments that show that these methods are applicable for a broad range of languages. Further experimentation indicates limited performance loss for untrained languages, when these have common features with the trained language(s). Secondly, it investigates how the methods deal with realistic background noise and proposes some modifications to better cope with these disturbances. The deep learning methods that will be examined are deep clustering and deep attractor networks.
CNN-LSTM models for Multi-Speaker Source Separation using Bayesian Hyper Parameter Optimization
Dec 19, 2019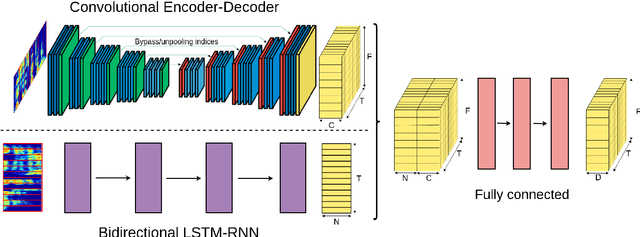
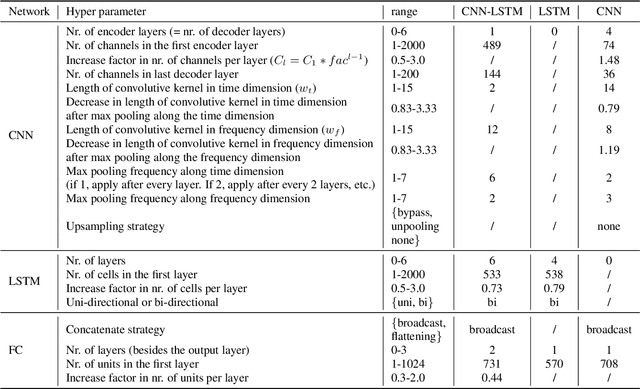
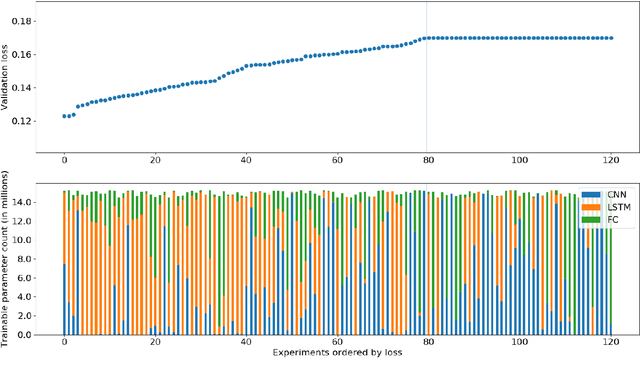
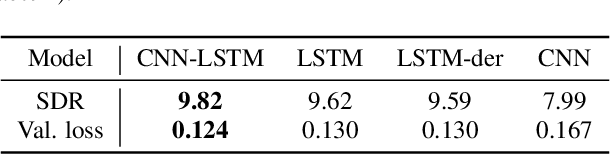
In recent years there have been many deep learning approaches towards the multi-speaker source separation problem. Most use Long Short-Term Memory - Recurrent Neural Networks (LSTM-RNN) or Convolutional Neural Networks (CNN) to model the sequential behavior of speech. In this paper we propose a novel network for source separation using an encoder-decoder CNN and LSTM in parallel. Hyper parameters have to be chosen for both parts of the network and they are potentially mutually dependent. Since hyper parameter grid search has a high computational burden, random search is often preferred. However, when sampling a new point in the hyper parameter space, it can potentially be very close to a previously evaluated point and thus give little additional information. Furthermore, random sampling is as likely to sample in a promising area as in an hyper space area dominated with poor performing models. Therefore, we use a Bayesian hyper parameter optimization technique and find that the parallel CNN-LSTM outperforms the LSTM-only and CNN-only model.
Memory Time Span in LSTMs for Multi-Speaker Source Separation
Aug 24, 2018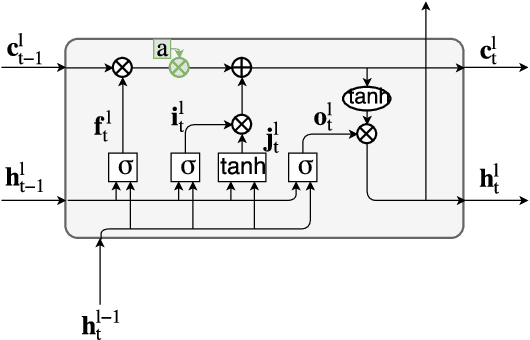
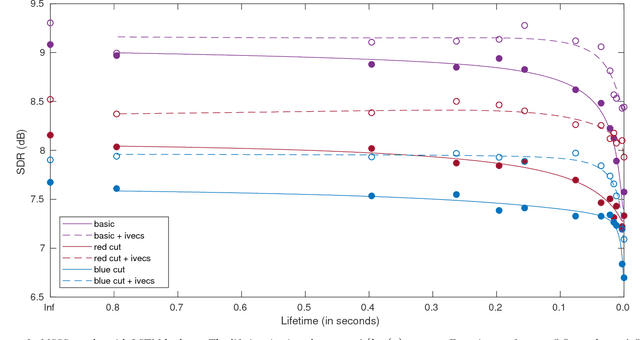
With deep learning approaches becoming state-of-the-art in many speech (as well as non-speech) related machine learning tasks, efforts are being taken to delve into the neural networks which are often considered as a black box. In this paper it is analyzed how recurrent neural network (RNNs) cope with temporal dependencies by determining the relevant memory time span in a long short-term memory (LSTM) cell. This is done by leaking the state variable with a controlled lifetime and evaluating the task performance. This technique can be used for any task to estimate the time span the LSTM exploits in that specific scenario. The focus in this paper is on the task of separating speakers from overlapping speech. We discern two effects: A long term effect, probably due to speaker characterization and a short term effect, probably exploiting phone-size formant tracks.
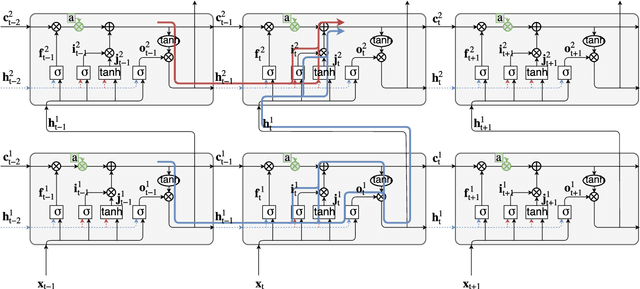
Multi-scenario deep learning for multi-speaker source separation
Aug 24, 2018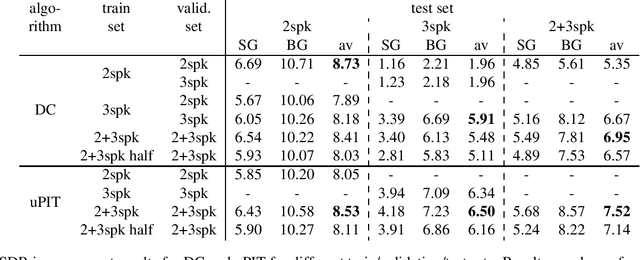
Research in deep learning for multi-speaker source separation has received a boost in the last years. However, most studies are restricted to mixtures of a specific number of speakers, called a specific scenario. While some works included experiments for different scenarios, research towards combining data of different scenarios or creating a single model for multiple scenarios have been very rare. In this work it is shown that data of a specific scenario is relevant for solving another scenario. Furthermore, it is concluded that a single model, trained on different scenarios is capable of matching performance of scenario specific models.
Joint Sound Source Separation and Speaker Recognition
Apr 29, 2016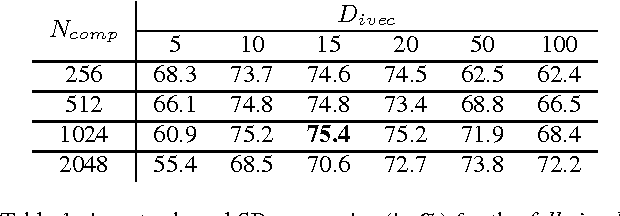
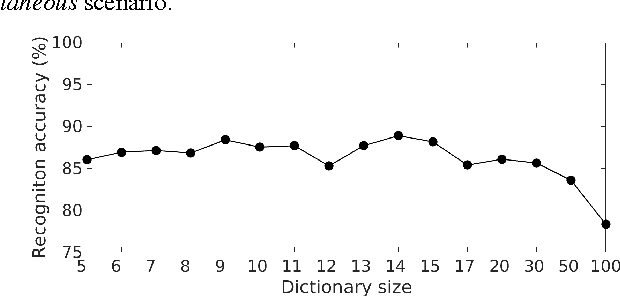
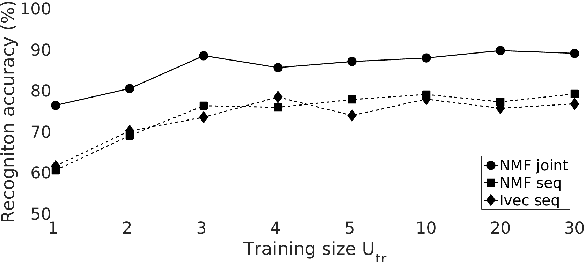

Non-negative Matrix Factorization (NMF) has already been applied to learn speaker characterizations from single or non-simultaneous speech for speaker recognition applications. It is also known for its good performance in (blind) source separation for simultaneous speech. This paper explains how NMF can be used to jointly solve the two problems in a multichannel speaker recognizer for simultaneous speech. It is shown how state-of-the-art multichannel NMF for blind source separation can be easily extended to incorporate speaker recognition. Experiments on the CHiME corpus show that this method outperforms the sequential approach of first applying source separation, followed by speaker recognition that uses state-of-the-art i-vector techniques.