 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Investigation of Cross-Language Plagiarism Detection Methods
May 24, 2017

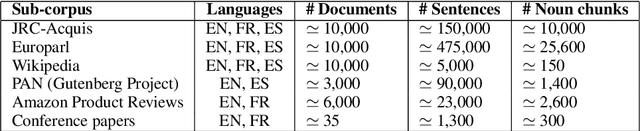
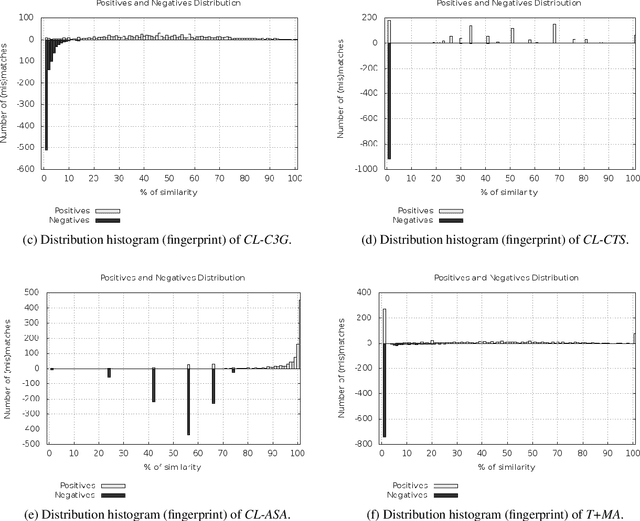
This paper is a deep investigation of cross-language plagiarism detection methods on a new recently introduced open dataset, which contains parallel and comparable collections of documents with multiple characteristics (different genres, languages and sizes of texts). We investigate cross-language plagiarism detection methods for 6 language pairs on 2 granularities of text units in order to draw robust conclusions on the best methods while deeply analyzing correlations across document styles and languages.
CompiLIG at SemEval-2017 Task 1: Cross-Language Plagiarism Detection Methods for Semantic Textual Similarity
Apr 05, 2017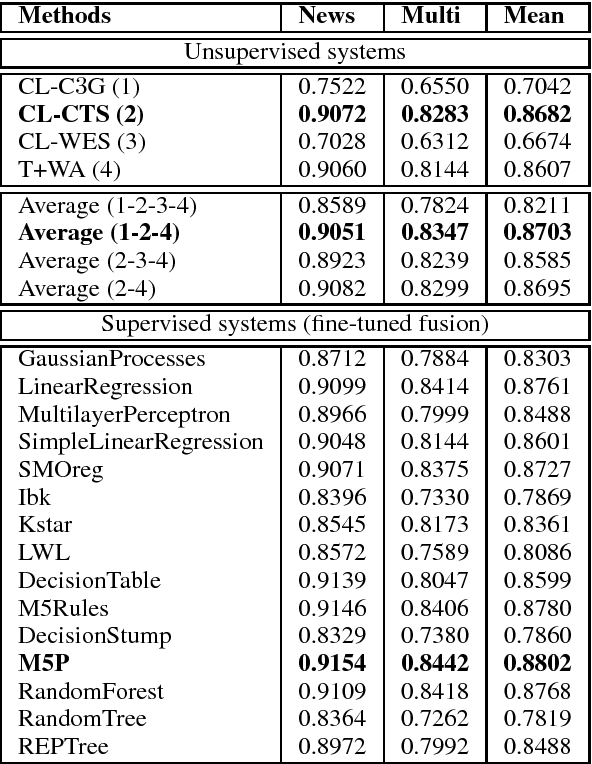
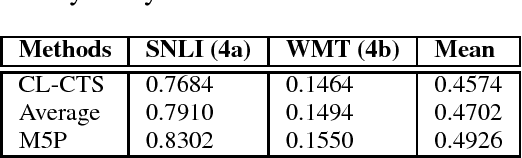
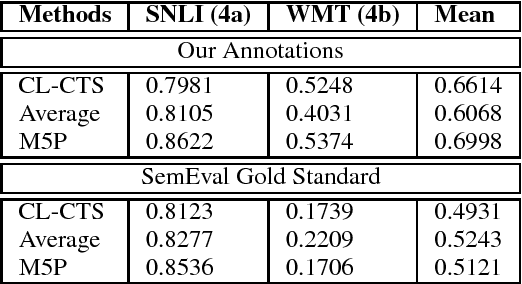
We present our submitted systems for Semantic Textual Similarity (STS) Track 4 at SemEval-2017. Given a pair of Spanish-English sentences, each system must estimate their semantic similarity by a score between 0 and 5. In our submission, we use syntax-based, dictionary-based, context-based, and MT-based methods. We also combine these methods in unsupervised and supervised way. Our best run ranked 1st on track 4a with a correlation of 83.02% with human annotations.