 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeMAJ (Legal LLM-as-a-Judge): Bridging Legal Reasoning and LLM Evaluation
Oct 08, 2025



Evaluating large language model (LLM) outputs in the legal domain presents unique challenges due to the complex and nuanced nature of legal analysis. Current evaluation approaches either depend on reference data, which is costly to produce, or use standardized assessment methods, both of which have significant limitations for legal applications. Although LLM-as-a-Judge has emerged as a promising evaluation technique, its reliability and effectiveness in legal contexts depend heavily on evaluation processes unique to the legal industry and how trustworthy the evaluation appears to the human legal expert. This is where existing evaluation methods currently fail and exhibit considerable variability. This paper aims to close the gap: a) we break down lengthy responses into 'Legal Data Points' (LDPs), self-contained units of information, and introduce a novel, reference-free evaluation methodology that reflects how lawyers evaluate legal answers; b) we demonstrate that our method outperforms a variety of baselines on both our proprietary dataset and an open-source dataset (LegalBench); c) we show how our method correlates more closely with human expert evaluations and helps improve inter-annotator agreement; and finally d) we open source our Legal Data Points for a subset of LegalBench used in our experiments, allowing the research community to replicate our results and advance research in this vital area of LLM evaluation on legal question-answering.
A Vision Based Deep Reinforcement Learning Algorithm for UAV Obstacle Avoidance
Mar 11, 2021
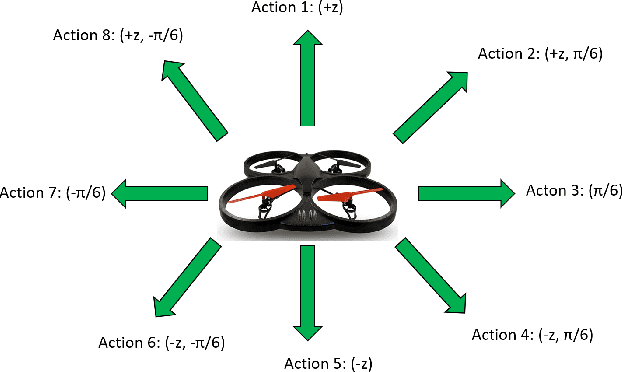


Integration of reinforcement learning with unmanned aerial vehicles (UAVs) to achieve autonomous flight has been an active research area in recent years. An important part focuses on obstacle detection and avoidance for UAVs navigating through an environment. Exploration in an unseen environment can be tackled with Deep Q-Network (DQN). However, value exploration with uniform sampling of actions may lead to redundant states, where often the environments inherently bear sparse rewards. To resolve this, we present two techniques for improving exploration for UAV obstacle avoidance. The first is a convergence-based approach that uses convergence error to iterate through unexplored actions and temporal threshold to balance exploration and exploitation. The second is a guidance-based approach using a Domain Network which uses a Gaussian mixture distribution to compare previously seen states to a predicted next state in order to select the next action. Performance and evaluation of these approaches were implemented in multiple 3-D simulation environments, with variation in complexity. The proposed approach demonstrates a two-fold improvement in average rewards compared to state of the art.