 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimisation of Collaborative Question Answering over Knowledge Graphs
Aug 14, 2019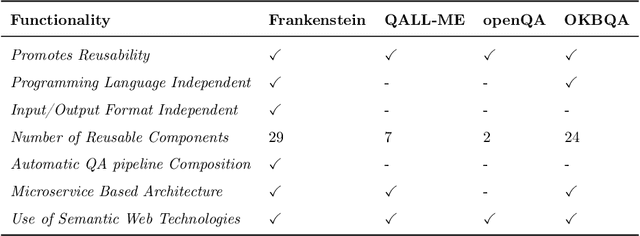
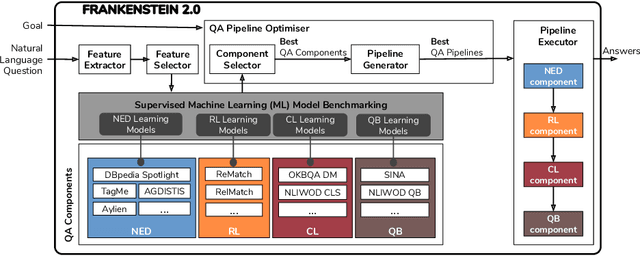
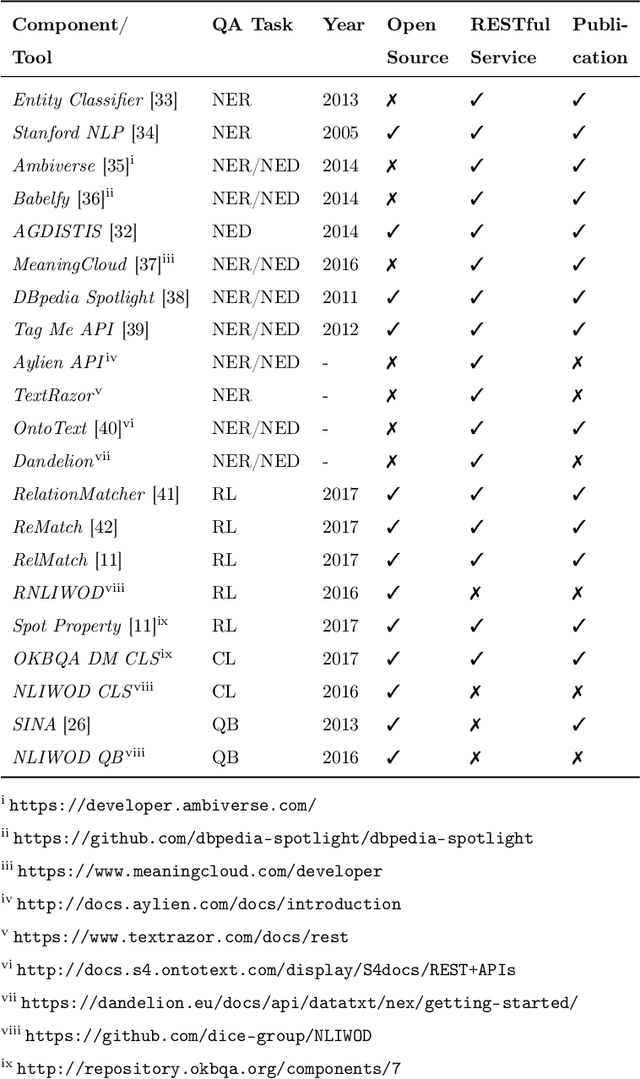
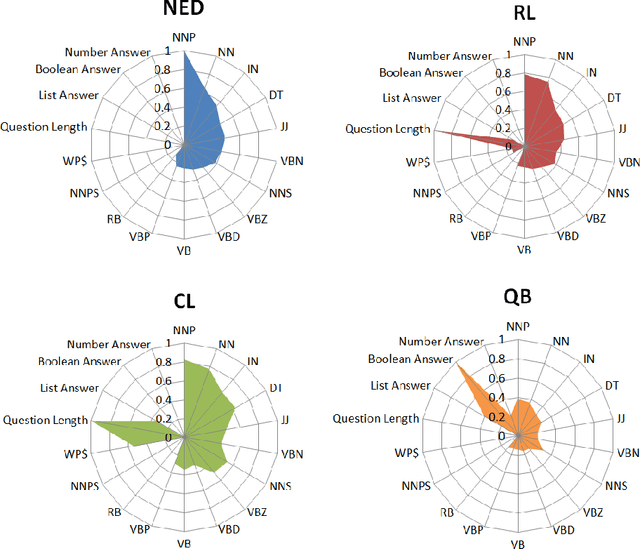
Collaborative Question Answering (CQA) frameworks for knowledge graphs aim at integrating existing question answering (QA) components for implementing sequences of QA tasks (i.e. QA pipelines). The research community has paid substantial attention to CQAs since they support reusability and scalability of the available components in addition to the flexibility of pipelines. CQA frameworks attempt to build such pipelines automatically by solving two optimisation problems: 1) local collective performance of QA components per QA task and 2) global performance of QA pipelines. In spite offering several advantages over monolithic QA systems, the effectiveness and efficiency of CQA frameworks in answering questions is limited. In this paper, we tackle the problem of local optimisation of CQA frameworks and propose a three fold approach, which applies feature selection techniques with supervised machine learning approaches in order to identify the best performing components efficiently. We have empirically evaluated our approach over existing benchmarks and compared to existing automatic CQA frameworks. The observed results provide evidence that our approach answers a higher number of questions than the state of the art while reducing: i) the number of used features by 50% and ii) the number of components used by 76%.
Linking Physicians to Medical Research Results via Knowledge Graph Embeddings and Twitter
Jul 24, 2019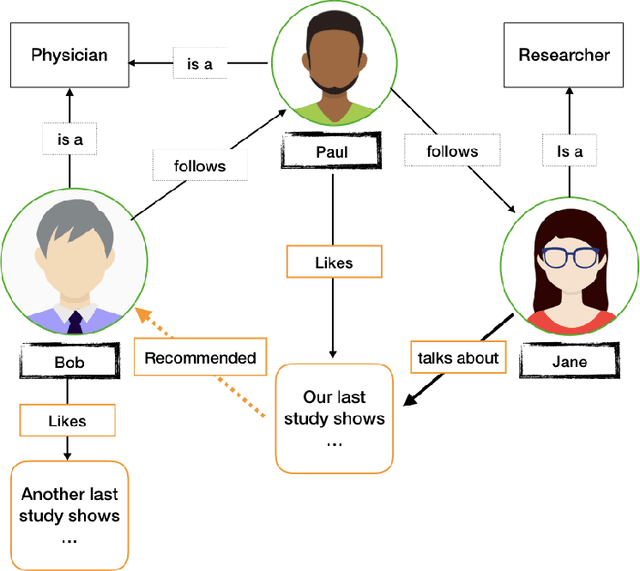


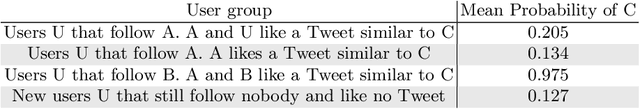
Informing professionals about the latest research results in their field is a particularly important task in the field of health care, since any development in this field directly improves the health status of the patients. Meanwhile, social media is an infrastructure that allows public instant sharing of information, thus it has recently become popular in medical applications. In this study, we apply Multi Distance Knowledge Graph Embeddings (MDE) to link physicians and surgeons to the latest medical breakthroughs that are shared as the research results on Twitter. Our study shows that using this method physicians can be informed about the new findings in their field given that they have an account dedicated to their profession.
Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs
Jul 22, 2019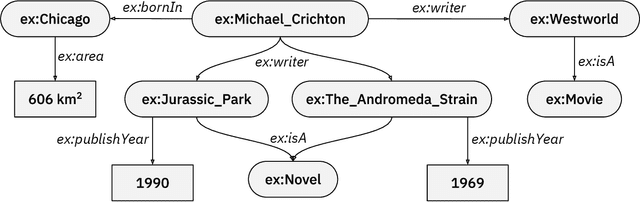
Question answering has emerged as an intuitive way of querying structured data sources, and has attracted significant advancements over the years. In this article, we provide an overview over these recent advancements, focusing on neural network based question answering systems over knowledge graphs. We introduce readers to the challenges in the tasks, current paradigms of approaches, discuss notable advancements, and outline the emerging trends in the field. Through this article, we aim to provide newcomers to the field with a suitable entry point, and ease their process of making informed decisions while creating their own QA system.
Adaptive Margin Ranking Loss for Knowledge Graph Embeddings via a Correntropy Objective Function
Jul 09, 2019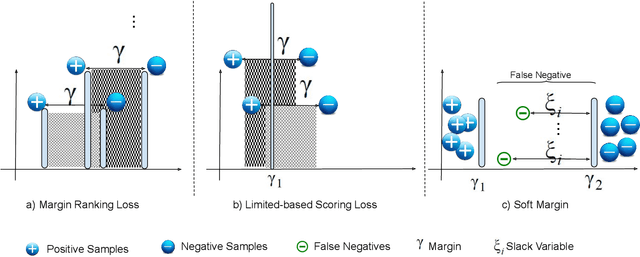
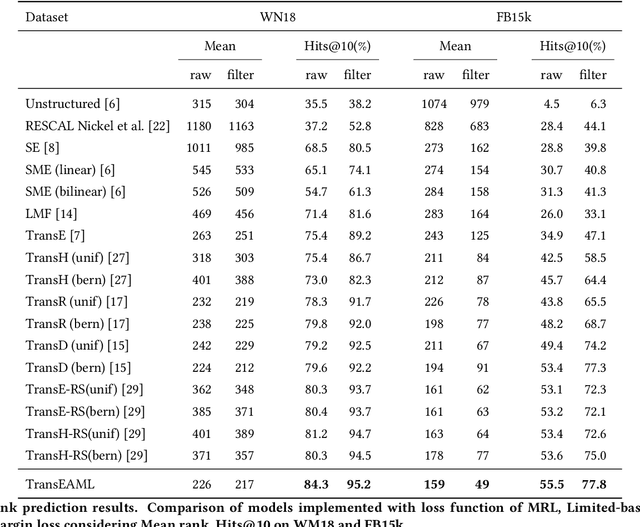
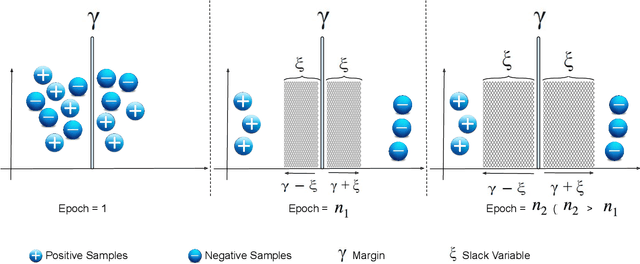
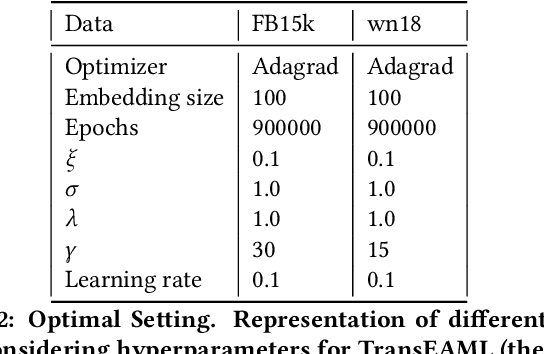
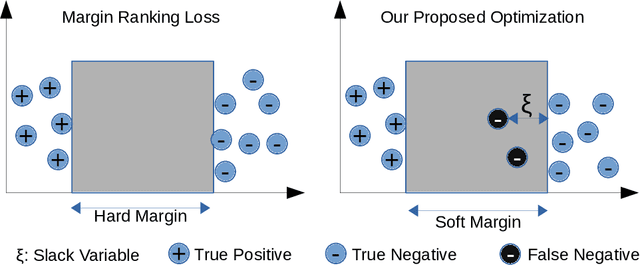
Translation-based embedding models have gained significant attention in link prediction tasks for knowledge graphs. TransE is the primary model among translation-based embeddings and is well-known for its low complexity and high efficiency. Therefore, most of the earlier works have modified the score function of the TransE approach in order to improve the performance of link prediction tasks. Nevertheless, proven theoretically and experimentally, the performance of TransE strongly depends on the loss function. Margin Ranking Loss (MRL) has been one of the earlier loss functions which is widely used for training TransE. However, the scores of positive triples are not necessarily enforced to be sufficiently small to fulfill the translation from head to tail by using relation vector (original assumption of TransE). To tackle this problem, several loss functions have been proposed recently by adding upper bounds and lower bounds to the scores of positive and negative samples. Although highly effective, previously developed models suffer from an expansion in search space for a selection of the hyperparameters (in particular the upper and lower bounds of scores) on which the performance of the translation-based models is highly dependent. In this paper, we propose a new loss function dubbed Adaptive Margin Loss (AML) for training translation-based embedding models. The formulation of the proposed loss function enables an adaptive and automated adjustment of the margin during the learning process. Therefore, instead of obtaining two values (upper bound and lower bound), only the center of a margin needs to be determined. During learning, the margin is expanded automatically until it converges. In our experiments on a set of standard benchmark datasets including Freebase and WordNet, the effectiveness of AML is confirmed for training TransE on link prediction tasks.
MDE: Multi Distance Embeddings for Link Prediction in Knowledge Graphs
Jun 10, 2019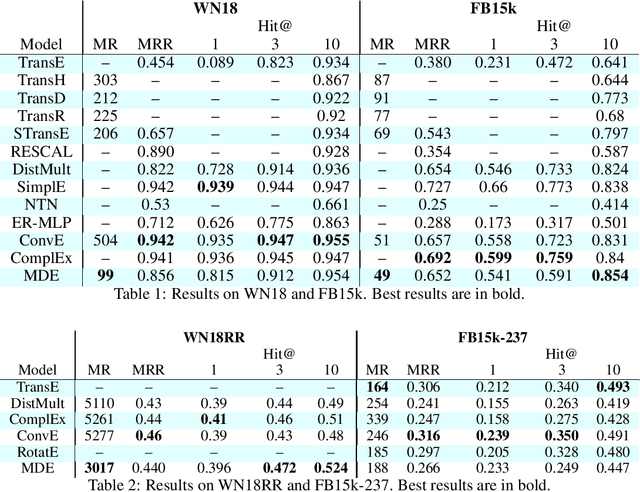
Over the past decade, knowledge graphs became popular for capturing structured domain knowledge. Relational learning models enable the prediction of missing links inside knowledge graphs. More specifically, latent distance approaches model the relationships among entities via a distance between latent representations. Translating embedding models (e.g., TransE) are among the most popular latent distance approaches which use one distance function to learn multiple relation patterns. However, they are not capable of capturing symmetric relations. They also force relations with reflexive patterns to become symmetric and transitive. In order to improve distance based embedding, we propose multi-distance embeddings (MDE). Our solution is based on the idea that by learning independent embedding vectors for each entity and relation one can aggregate contrasting distance functions. Benefiting from MDE, we also develop supplementary distances resolving the above-mentioned limitations of TransE. We further propose an extended loss function for distance based embeddings and show that MDE and TransE are fully expressive using this loss function. Furthermore, we obtain a bound on the size of their embeddings for full expressivity. Our empirical results show that MDE significantly improves the translating embeddings and outperforms several state-of-the-art embedding models on benchmark datasets.
Soft Marginal TransE for Scholarly Knowledge Graph Completion
Apr 27, 2019
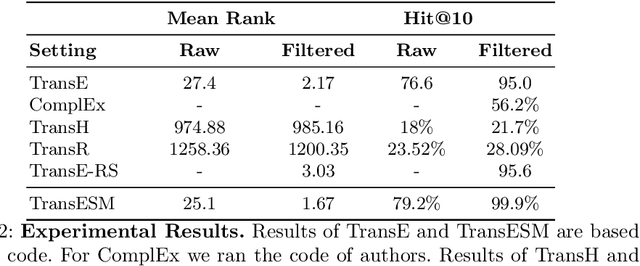
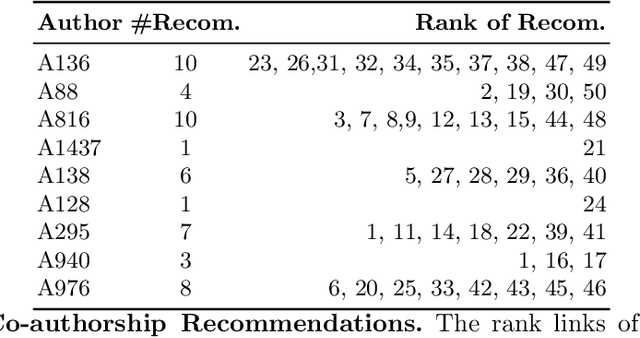
Knowledge graphs (KGs), i.e. representation of information as a semantic graph, provide a significant test bed for many tasks including question answering, recommendation, and link prediction. Various amount of scholarly metadata have been made vailable as knowledge graphs from the diversity of data providers and agents. However, these high-quantities of data remain far from quality criteria in terms of completeness while growing at a rapid pace. Most of the attempts in completing such KGs are following traditional data digitization, harvesting and collaborative curation approaches. Whereas, advanced AI-related approaches such as embedding models - specifically designed for such tasks - are usually evaluated for standard benchmarks such as Freebase and Wordnet. The tailored nature of such datasets prevents those approaches to shed the lights on more accurate discoveries. Application of such models on domain-specific KGs takes advantage of enriched meta-data and provides accurate results where the underlying domain can enormously benefit. In this work, the TransE embedding model is reconciled for a specific link prediction task on scholarly metadata. The results show a significant shift in the accuracy and performance evaluation of the model on a dataset with scholarly metadata. The newly proposed version of TransE obtains 99.9% for link prediction task while original TransE gets 95%. In terms of accuracy and Hit@10, TransE outperforms other embedding models such as ComplEx, TransH and TransR experimented over scholarly knowledge graphs
Translating Natural Language to SQL using Pointer-Generator Networks and How Decoding Order Matters
Nov 13, 2018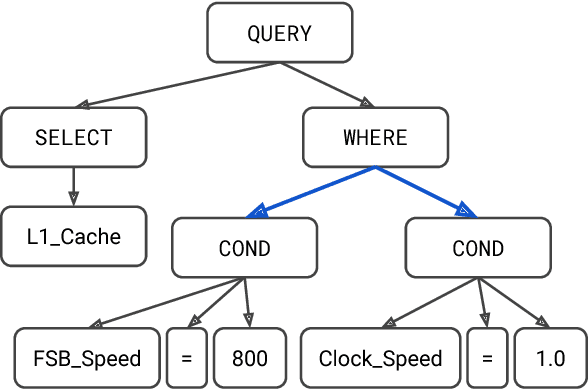
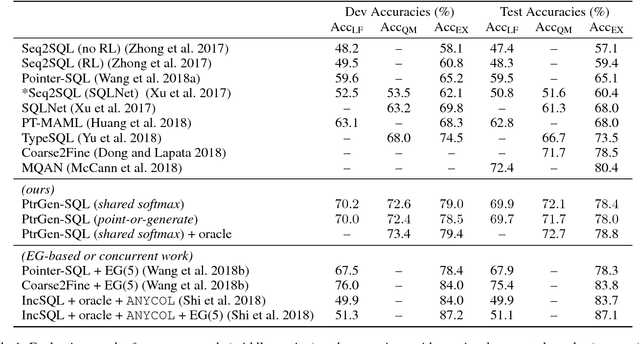
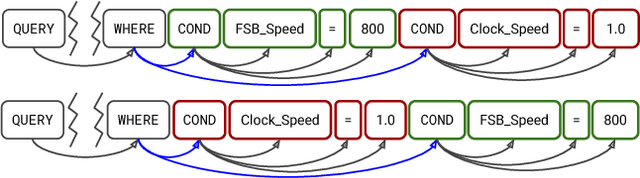
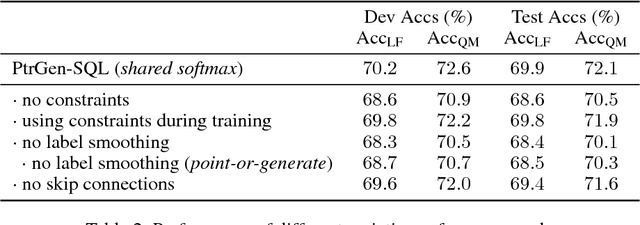
Translating natural language to SQL queries for table-based question answering is a challenging problem and has received significant attention from the research community. In this work, we extend a pointer-generator and investigate the order-matters problem in semantic parsing for SQL. Even though our model is a straightforward extension of a general-purpose pointer-generator, it outperforms early works for WikiSQL and remains competitive to concurrently introduced, more complex models. Moreover, we provide a deeper investigation of the potential order-matters problem that could arise due to having multiple correct decoding paths, and investigate the use of REINFORCE as well as a dynamic oracle in this context.
Improving Response Selection in Multi-Turn Dialogue Systems by Incorporating Domain Knowledge
Nov 05, 2018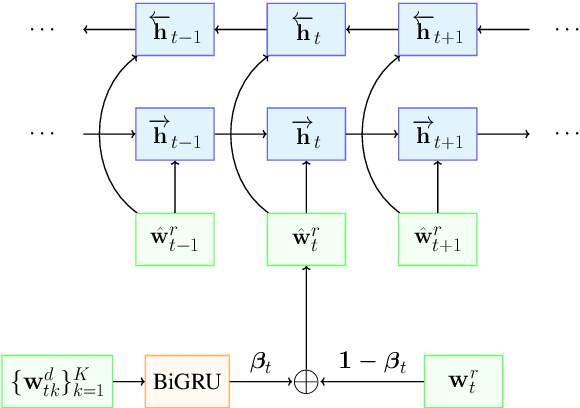
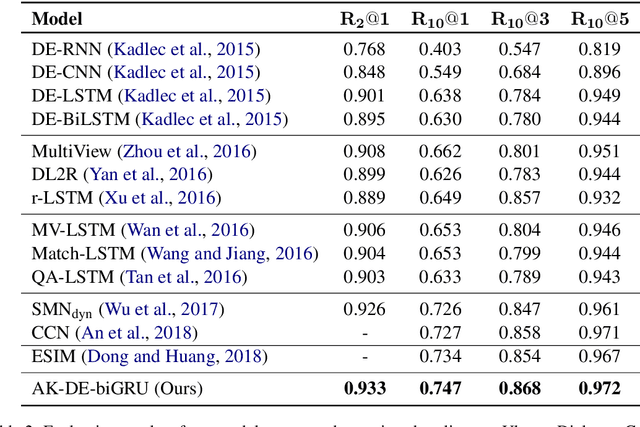
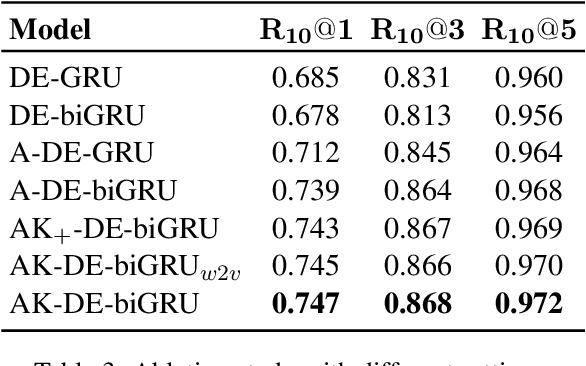

Building systems that can communicate with humans is a core problem in Artificial Intelligence. This work proposes a novel neural network architecture for response selection in an end-to-end multi-turn conversational dialogue setting. The architecture applies context level attention and incorporates additional external knowledge provided by descriptions of domain-specific words. It uses a bi-directional Gated Recurrent Unit (GRU) for encoding context and responses and learns to attend over the context words given the latent response representation and vice versa.In addition, it incorporates external domain specific information using another GRU for encoding the domain keyword descriptions. This allows better representation of domain-specific keywords in responses and hence improves the overall performance. Experimental results show that our model outperforms all other state-of-the-art methods for response selection in multi-turn conversations.
Learning to Rank Query Graphs for Complex Question Answering over Knowledge Graphs
Nov 02, 2018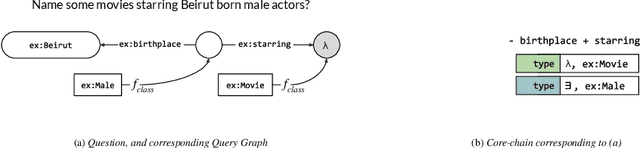
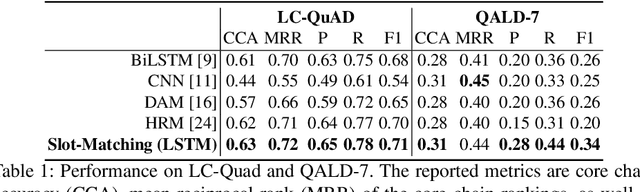
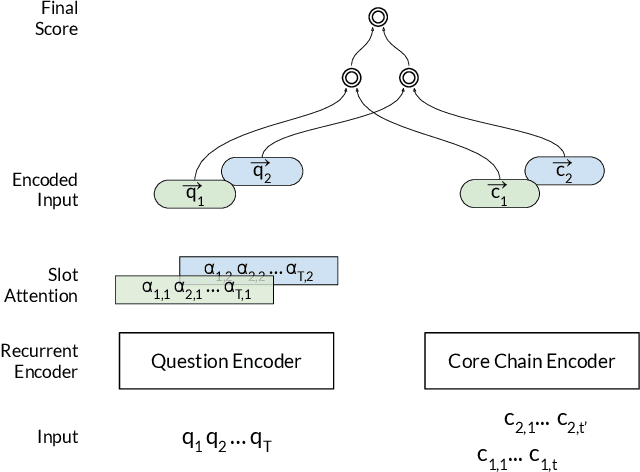
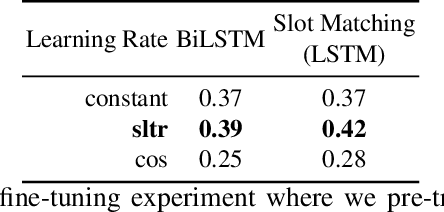
In this paper, we conduct an empirical investigation of neural query graph ranking approaches for the task of complex question answering over knowledge graphs. We experiment with six different ranking models and propose a novel self-attention based slot matching model which exploits the inherent structure of query graphs, our logical form of choice. Our proposed model generally outperforms the other models on two QA datasets over the DBpedia knowledge graph, evaluated in different settings. In addition, we show that transfer learning from the larger of those QA datasets to the smaller dataset yields substantial improvements, effectively offsetting the general lack of training data.
No One is Perfect: Analysing the Performance of Question Answering Components over the DBpedia Knowledge Graph
Sep 26, 2018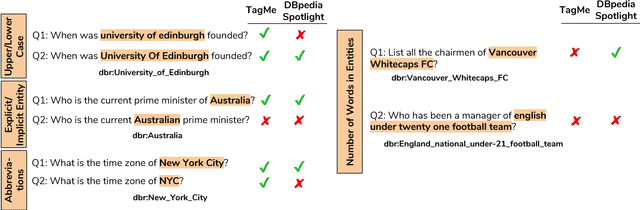

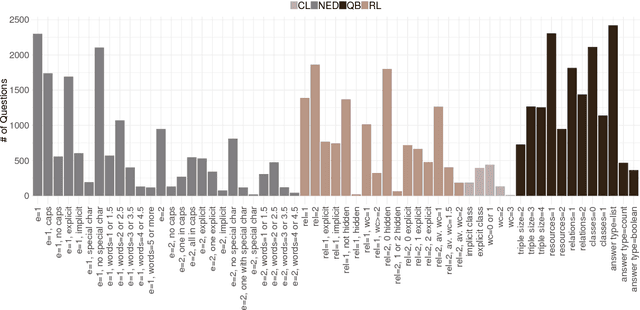
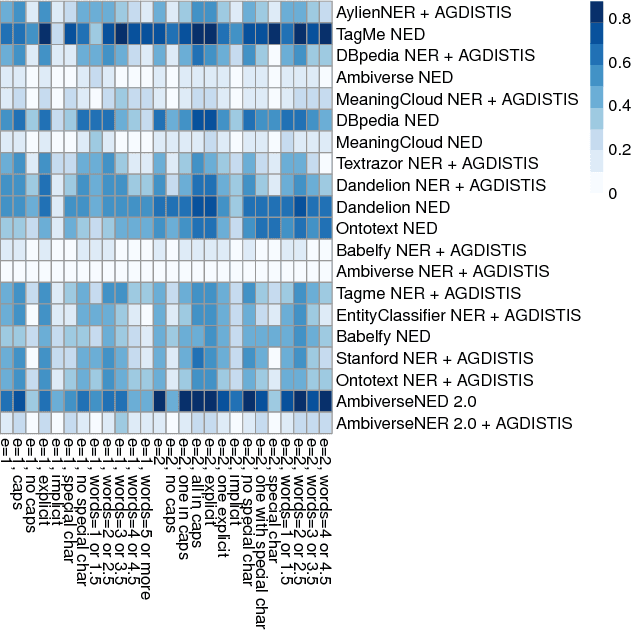
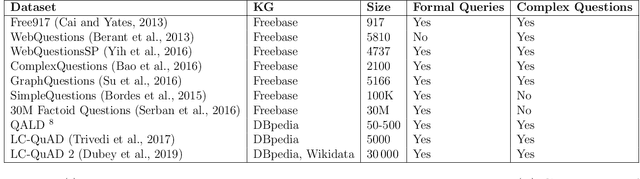
Question answering (QA) over knowledge graphs has gained significant momentum over the past five years due to the increasing availability of large knowledge graphs and the rising importance of question answering for user interaction. DBpedia has been the most prominently used knowledge graph in this setting and most approaches currently use a pipeline of processing steps connecting a sequence of components. In this article, we analyse and micro evaluate the behaviour of 29 available QA components for DBpedia knowledge graph that were released by the research community since 2010. As a result, we provide a perspective on collective failure cases, suggest characteristics of QA components that prevent them from performing better and provide future challenges and research directions for the field.