 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated structural testing of LLM-based agents: methods, framework, and case studies
Jan 25, 2026LLM-based agents are rapidly being adopted across diverse domains. Since they interact with users without supervision, they must be tested extensively. Current testing approaches focus on acceptance-level evaluation from the user's perspective. While intuitive, these tests require manual evaluation, are difficult to automate, do not facilitate root cause analysis, and incur expensive test environments. In this paper, we present methods to enable structural testing of LLM-based agents. Our approach utilizes traces (based on OpenTelemetry) to capture agent trajectories, employs mocking to enforce reproducible LLM behavior, and adds assertions to automate test verification. This enables testing agent components and interactions at a deeper technical level within automated workflows. We demonstrate how structural testing enables the adaptation of software engineering best practices to agents, including the test automation pyramid, regression testing, test-driven development, and multi-language testing. In representative case studies, we demonstrate automated execution and faster root-cause analysis. Collectively, these methods reduce testing costs and improve agent quality through higher coverage, reusability, and earlier defect detection. We provide an open source reference implementation on GitHub.
Generative AI Toolkit -- a framework for increasing the quality of LLM-based applications over their whole life cycle
Dec 18, 2024As LLM-based applications reach millions of customers, ensuring their scalability and continuous quality improvement is critical for success. However, the current workflows for developing, maintaining, and operating (DevOps) these applications are predominantly manual, slow, and based on trial-and-error. With this paper we introduce the Generative AI Toolkit, which automates essential workflows over the whole life cycle of LLM-based applications. The toolkit helps to configure, test, continuously monitor and optimize Generative AI applications such as agents, thus significantly improving quality while shortening release cycles. We showcase the effectiveness of our toolkit on representative use cases, share best practices, and outline future enhancements. Since we are convinced that our Generative AI Toolkit is helpful for other teams, we are open sourcing it on and hope that others will use, forward, adapt and improve
Bayesian Structural Learning for an Improved Diagnosis of Cyber-Physical Systems
Apr 02, 2021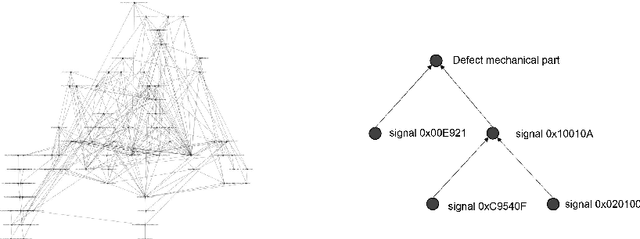
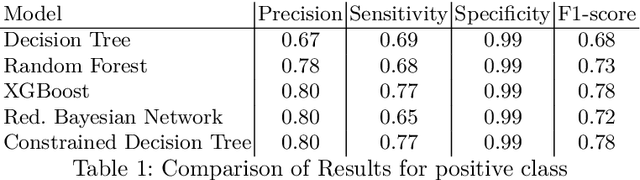
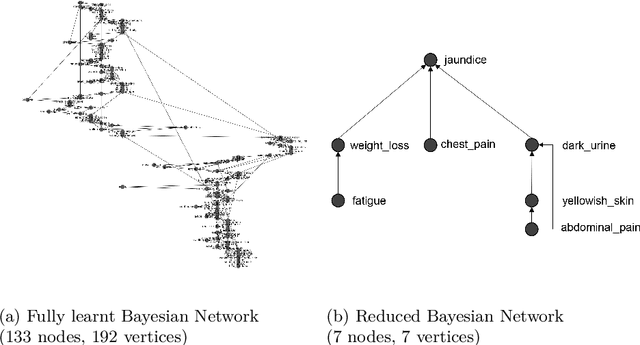
The diagnosis of cyber-physical systems (CPS) is based on a representation of functional and faulty behaviour which is combined with system observations taken at runtime to detect faulty behaviour and reason for its root cause. In this paper we propose a scalable algorithm for an automated learning of a structured diagnosis model which -- although having a reduced size -- offers equal performance to comparable algorithms while giving better interpretability. This allows tackling challenges of diagnosing CPS: automatically learning a diagnosis model even with hugely imbalanced data, reducing the state-explosion problem when searching for a root cause, and an easy interpretability of the results. Our approach differs from existing methods in two aspects: firstly, we aim to learn a holistic global representation which is then transformed to a smaller, label-specific representation. Secondly, we focus on providing a highly interpretable model for an easy verification of the model and to facilitate repairs. We evaluated our approach on data sets relevant for our problem domain. The evaluation shows that the algorithm overcomes the mentioned problems while returning a comparable performance.