 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiodenoising: animal vocalization denoising without access to clean data
Oct 04, 2024Animal vocalization denoising is a task similar to human speech enhancement, a well-studied field of research. In contrast to the latter, it is applied to a higher diversity of sound production mechanisms and recording environments, and this higher diversity is a challenge for existing models. Adding to the challenge and in contrast to speech, we lack large and diverse datasets comprising clean vocalizations. As a solution we use as training data pseudo-clean targets, i.e. pre-denoised vocalizations, and segments of background noise without a vocalization. We propose a train set derived from bioacoustics datasets and repositories representing diverse species, acoustic environments, geographic regions. Additionally, we introduce a non-overlapping benchmark set comprising clean vocalizations from different taxa and noise samples. We show that that denoising models (demucs, CleanUNet) trained on pseudo-clean targets obtained with speech enhancement models achieve competitive results on the benchmarking set. We publish data, code, libraries, and demos https://mariusmiron.com/research/biodenoising.
ISPA: Inter-Species Phonetic Alphabet for Transcribing Animal Sounds
Feb 05, 2024Traditionally, bioacoustics has relied on spectrograms and continuous, per-frame audio representations for the analysis of animal sounds, also serving as input to machine learning models. Meanwhile, the International Phonetic Alphabet (IPA) system has provided an interpretable, language-independent method for transcribing human speech sounds. In this paper, we introduce ISPA (Inter-Species Phonetic Alphabet), a precise, concise, and interpretable system designed for transcribing animal sounds into text. We compare acoustics-based and feature-based methods for transcribing and classifying animal sounds, demonstrating their comparable performance with baseline methods utilizing continuous, dense audio representations. By representing animal sounds with text, we effectively treat them as a "foreign language," and we show that established human language ML paradigms and models, such as language models, can be successfully applied to improve performance.
Modeling Animal Vocalizations through Synthesizers
Oct 19, 2022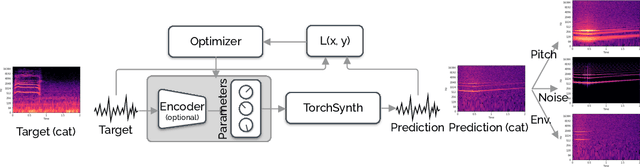
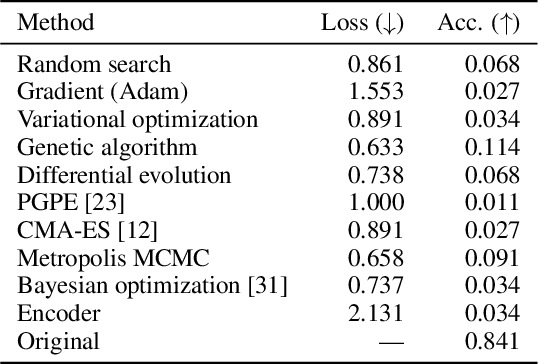
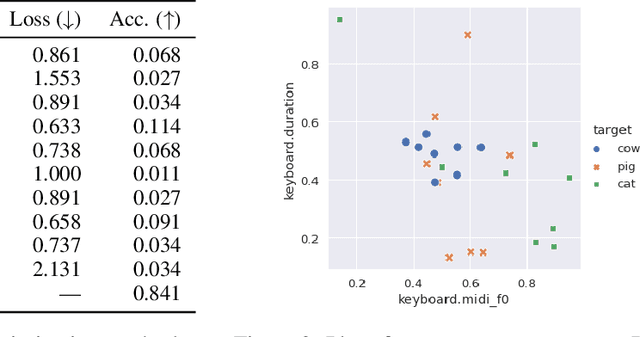
Modeling real-world sound is a fundamental problem in the creative use of machine learning and many other fields, including human speech processing and bioacoustics. Transformer-based generative models and some prior work (e.g., DDSP) are known to produce realistic sound, although they have limited control and are hard to interpret. As an alternative, we aim to use modular synthesizers, i.e., compositional, parametric electronic musical instruments, for modeling non-music sounds. However, inferring synthesizer parameters given a target sound, i.e., the parameter inference task, is not trivial for general sounds, and past research has typically focused on musical sound. In this work, we optimize a differentiable synthesizer from TorchSynth in order to model, emulate, and creatively generate animal vocalizations. We compare an array of optimization methods, from gradient-based search to genetic algorithms, for inferring its parameters, and then demonstrate how one can control and interpret the parameters for modeling non-music sounds.
KaraSinger: Score-Free Singing Voice Synthesis with VQ-VAE using Mel-spectrograms
Oct 08, 2021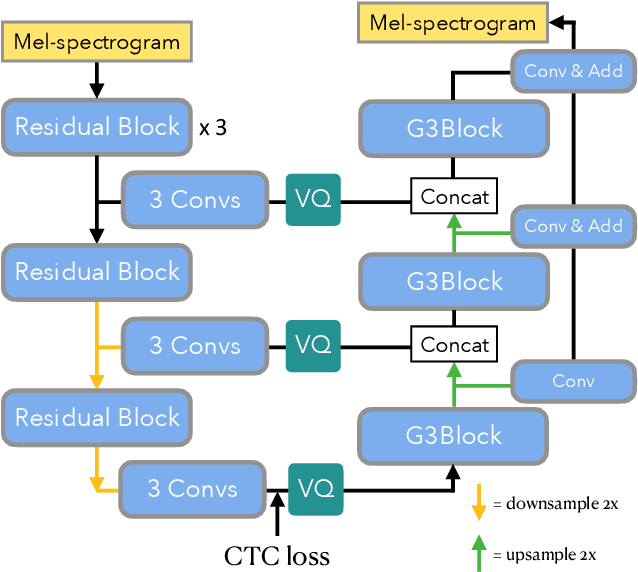
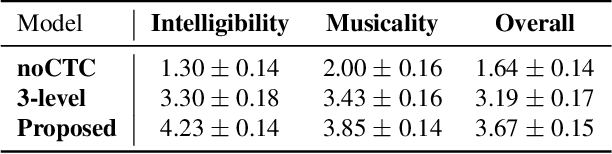
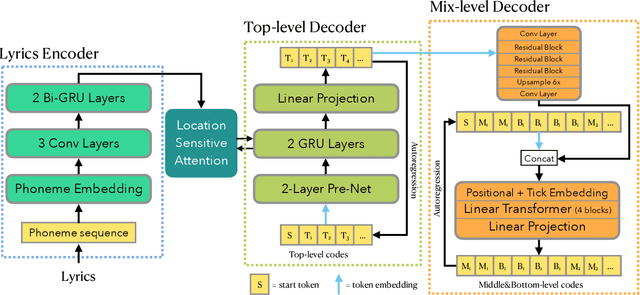

In this paper, we propose a novel neural network model called KaraSinger for a less-studied singing voice synthesis (SVS) task named score-free SVS, in which the prosody and melody are spontaneously decided by machine. KaraSinger comprises a vector-quantized variational autoencoder (VQ-VAE) that compresses the Mel-spectrograms of singing audio to sequences of discrete codes, and a language model (LM) that learns to predict the discrete codes given the corresponding lyrics. For the VQ-VAE part, we employ a Connectionist Temporal Classification (CTC) loss to encourage the discrete codes to carry phoneme-related information. For the LM part, we use location-sensitive attention for learning a robust alignment between the input phoneme sequence and the output discrete code. We keep the architecture of both the VQ-VAE and LM light-weight for fast training and inference speed. We validate the effectiveness of the proposed design choices using a proprietary collection of 550 English pop songs sung by multiple amateur singers. The result of a listening test shows that KaraSinger achieves high scores in intelligibility, musicality, and the overall quality.
Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs
Jan 07, 2021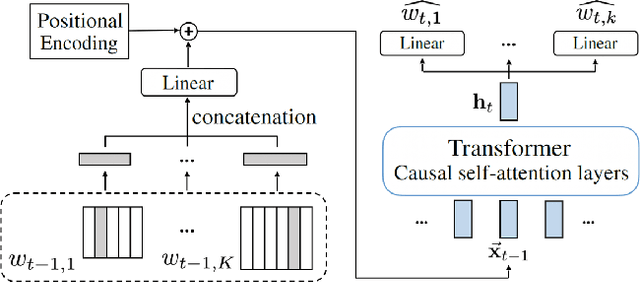
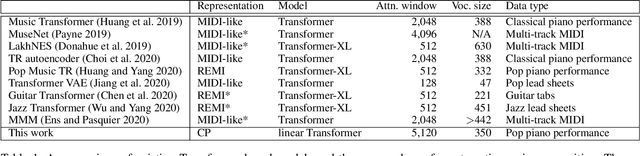
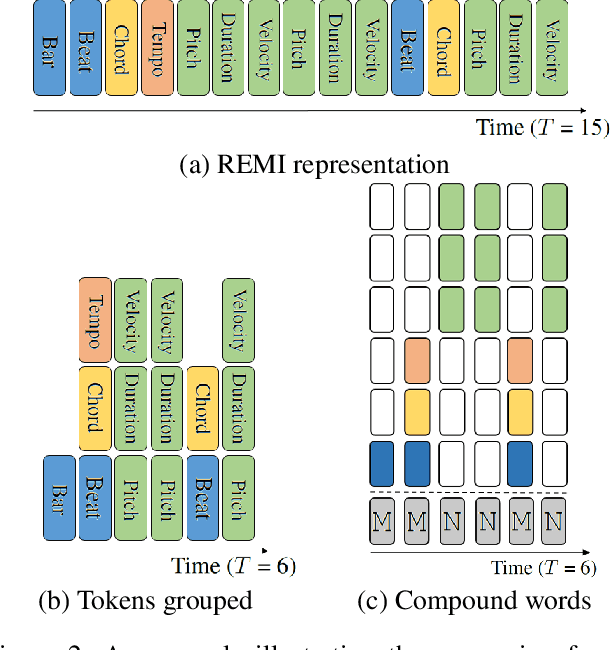

To apply neural sequence models such as the Transformers to music generation tasks, one has to represent a piece of music by a sequence of tokens drawn from a finite set of pre-defined vocabulary. Such a vocabulary usually involves tokens of various types. For example, to describe a musical note, one needs separate tokens to indicate the note's pitch, duration, velocity (dynamics), and placement (onset time) along the time grid. While different types of tokens may possess different properties, existing models usually treat them equally, in the same way as modeling words in natural languages. In this paper, we present a conceptually different approach that explicitly takes into account the type of the tokens, such as note types and metric types. And, we propose a new Transformer decoder architecture that uses different feed-forward heads to model tokens of different types. With an expansion-compression trick, we convert a piece of music to a sequence of compound words by grouping neighboring tokens, greatly reducing the length of the token sequences. We show that the resulting model can be viewed as a learner over dynamic directed hypergraphs. And, we employ it to learn to compose expressive Pop piano music of full-song length (involving up to 10K individual tokens per song), both conditionally and unconditionally. Our experiment shows that, compared to state-of-the-art models, the proposed model converges 5--10 times faster at training (i.e., within a day on a single GPU with 11 GB memory), and with comparable quality in the generated music.
Unconditional Audio Generation with Generative Adversarial Networks and Cycle Regularization
May 18, 2020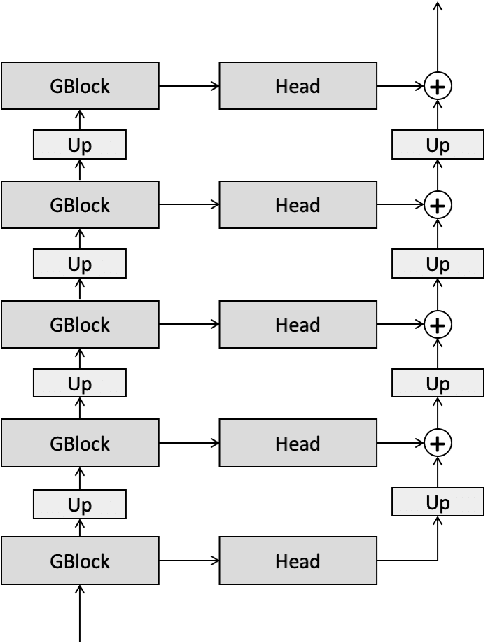
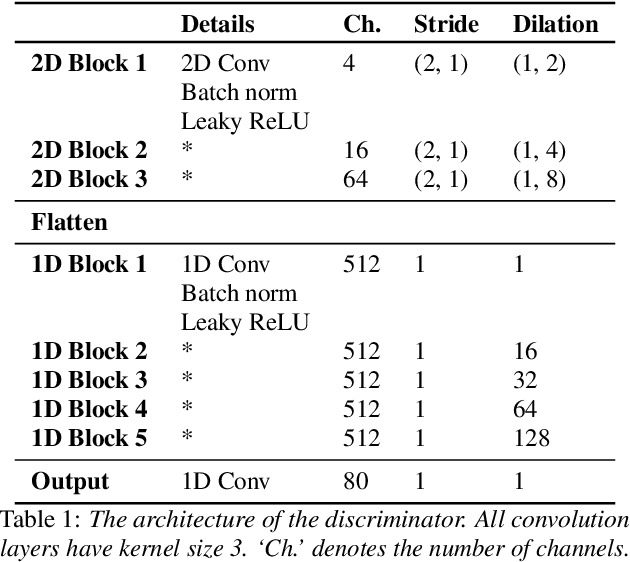
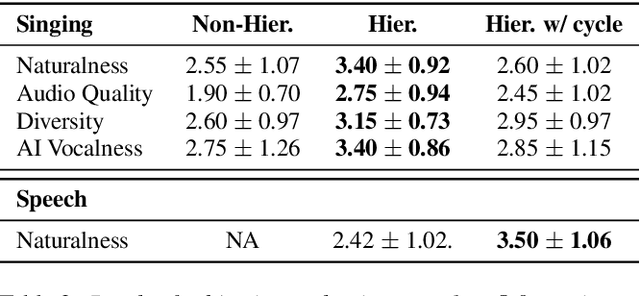
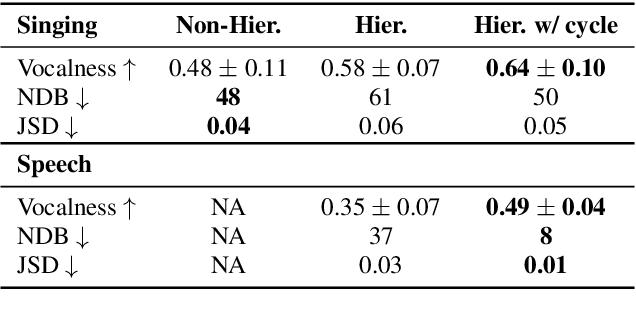
In a recent paper, we have presented a generative adversarial network (GAN)-based model for unconditional generation of the mel-spectrograms of singing voices. As the generator of the model is designed to take a variable-length sequence of noise vectors as input, it can generate mel-spectrograms of variable length. However, our previous listening test shows that the quality of the generated audio leaves room for improvement. The present paper extends and expands that previous work in the following aspects. First, we employ a hierarchical architecture in the generator to induce some structure in the temporal dimension. Second, we introduce a cycle regularization mechanism to the generator to avoid mode collapse. Third, we evaluate the performance of the new model not only for generating singing voices, but also for generating speech voices. Evaluation result shows that new model outperforms the prior one both objectively and subjectively. We also employ the model to unconditionally generate sequences of piano and violin music and find the result promising. Audio examples, as well as the code for implementing our model, will be publicly available online upon paper publication.
Score and Lyrics-Free Singing Voice Generation
Dec 26, 2019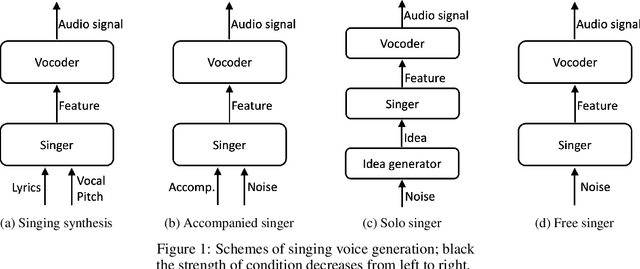
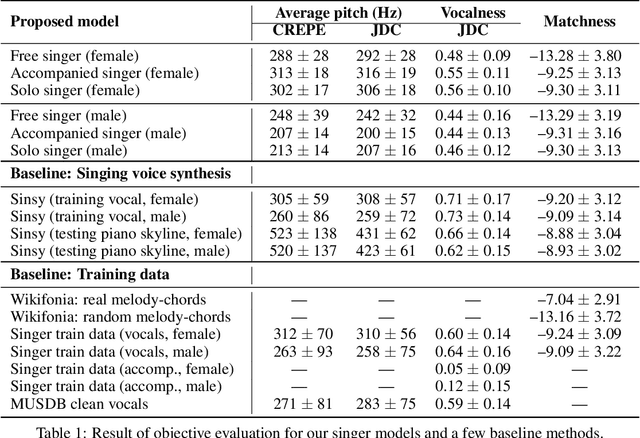
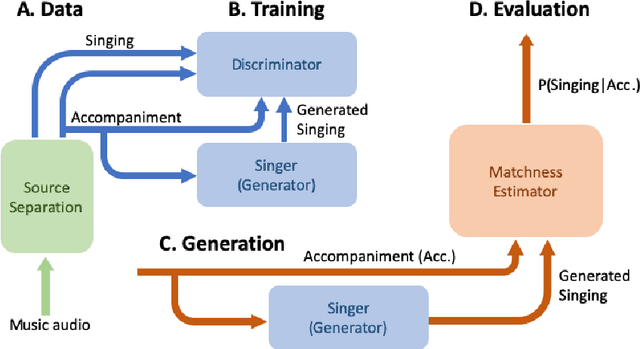

Generative models for singing voice have been mostly concerned with the task of "singing voice synthesis," i.e., to produce singing voice waveforms given musical scores and text lyrics. In this work, we explore a novel yet challenging alternative: singing voice generation without pre-assigned scores and lyrics, in both training and inference time. In particular, we propose three either unconditioned or weakly conditioned singing voice generation schemes. We outline the associated challenges and propose a pipeline to tackle these new tasks. This involves the development of source separation and transcription models for data preparation, adversarial networks for audio generation, and customized metrics for evaluation.
Dilated Convolution with Dilated GRU for Music Source Separation
Jun 04, 2019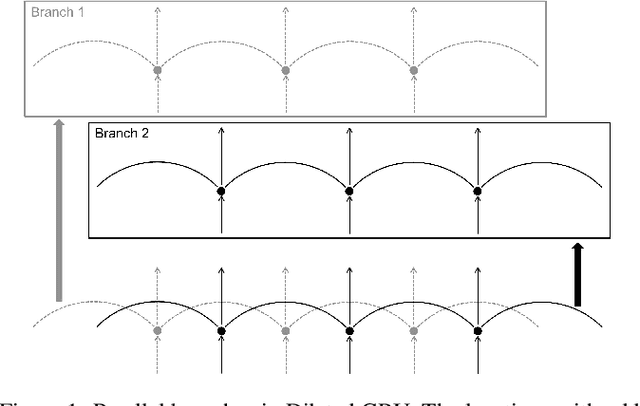
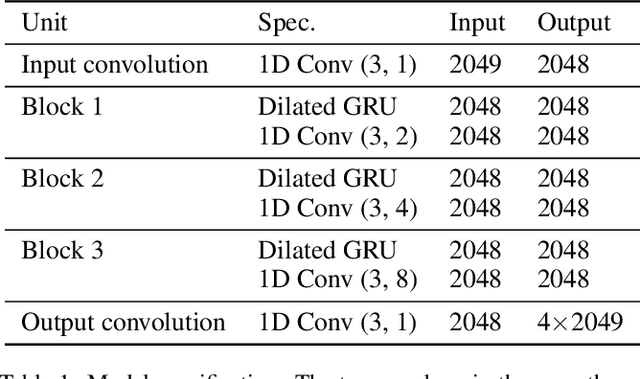
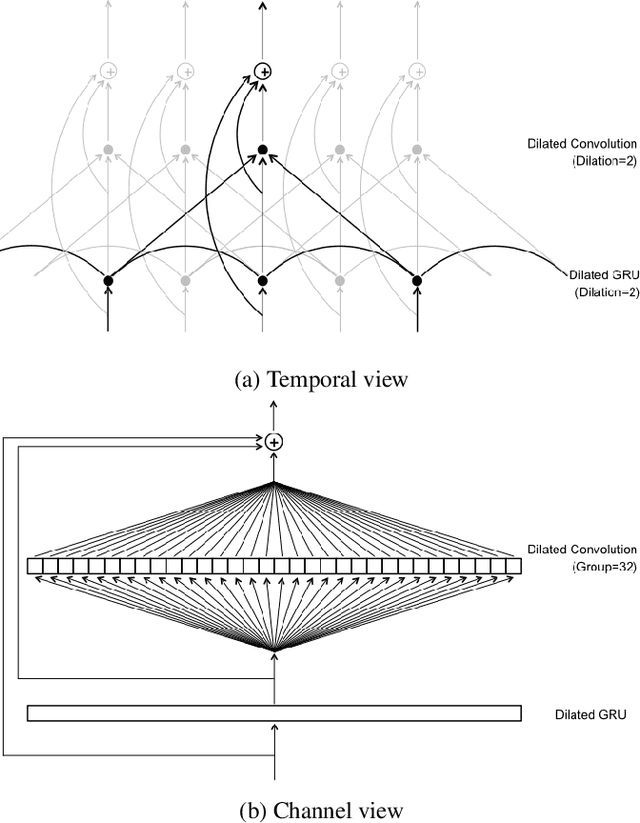
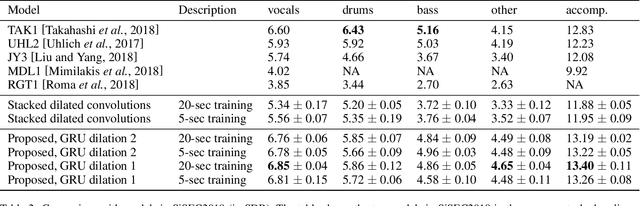
Stacked dilated convolutions used in Wavenet have been shown effective for generating high-quality audios. By replacing pooling/striding with dilation in convolution layers, they can preserve high-resolution information and still reach distant locations. Producing high-resolution predictions is also crucial in music source separation, whose goal is to separate different sound sources while maintaining the quality of the separated sounds. Therefore, this paper investigates using stacked dilated convolutions as the backbone for music source separation. However, while stacked dilated convolutions can reach wider context than standard convolutions, their effective receptive fields are still fixed and may not be wide enough for complex music audio signals. To reach information at remote locations, we propose to combine dilated convolution with a modified version of gated recurrent units (GRU) called the `Dilated GRU' to form a block. A Dilated GRU unit receives information from k steps before instead of the previous step for a fixed k. This modification allows a GRU unit to reach a location with fewer recurrent steps and run faster because it can execute partially in parallel. We show that the proposed model with a stack of such blocks performs equally well or better than the state-of-the-art models for separating vocals and accompaniments.
Singing Style Transfer Using Cycle-Consistent Boundary Equilibrium Generative Adversarial Networks
Jul 06, 2018
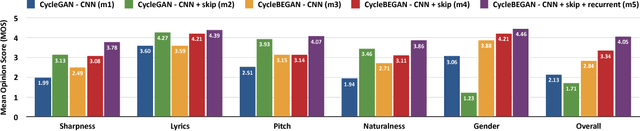
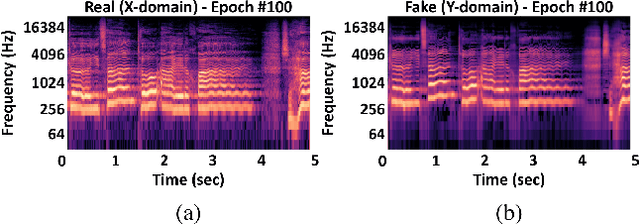
Can we make a famous rap singer like Eminem sing whatever our favorite song? Singing style transfer attempts to make this possible, by replacing the vocal of a song from the source singer to the target singer. This paper presents a method that learns from unpaired data for singing style transfer using generative adversarial networks.
* 3 pages, 3 figures, demo website: http://mirlab.org/users/haley.wu/cybegan
Weakly-supervised Visual Instrument-playing Action Detection in Videos
May 05, 2018
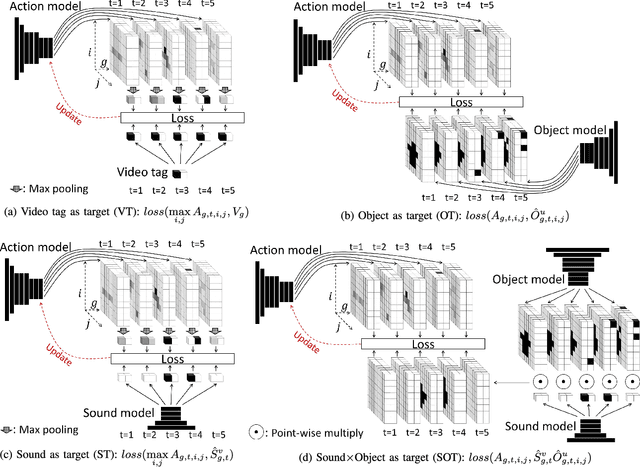

Instrument playing is among the most common scenes in music-related videos, which represent nowadays one of the largest sources of online videos. In order to understand the instrument-playing scenes in the videos, it is important to know what instruments are played, when they are played, and where the playing actions occur in the scene. While audio-based recognition of instruments has been widely studied, the visual aspect of the music instrument playing remains largely unaddressed in the literature. One of the main obstacles is the difficulty in collecting annotated data of the action locations for training-based methods. To address this issue, we propose a weakly-supervised framework to find when and where the instruments are played in the videos. We propose to use two auxiliary models, a sound model and an object model, to provide supervisions for training the instrument-playing action model. The sound model provides temporal supervisions, while the object model provides spatial supervisions. They together can simultaneously provide temporal and spatial supervisions. The resulted model only needs to analyze the visual part of a music video to deduce which, when and where instruments are played. We found that the proposed method significantly improves the localization accuracy. We evaluate the result of the proposed method temporally and spatially on a small dataset (totally 5,400 frames) that we manually annotated.