 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRENCH-YMCA: A FRENCH Corpus meeting the language needs of Youth, froM Children to Adolescents
Apr 07, 2026In this paper, we introduce the French-YMCA corpus, a new linguistic resource specifically tailored for children and adolescents. The motivation for building this corpus is clear: children have unique language requirements, as their language skills are in constant evolution and differ from those of adults. With an extensive collection of 39,200 text files, the French-YMCA corpus encompasses a total of 22,471,898 words. It distinguishes itself through its diverse sources, consistent grammar and spelling, and the commitment to providing open online accessibility for all. Such corpus can serve as the foundation for training language models that understand and anticipate youth's language, thereby enhancing the quality of digital interactions and ensuring that responses and suggestions are age-appropriate and adapted to the comprehension level of users of this age.
To Be or Not To Be a Verbal Multiword Expression: A Quest for Discriminating Features
Jul 22, 2020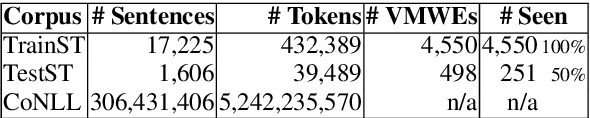
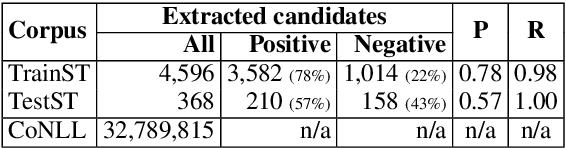
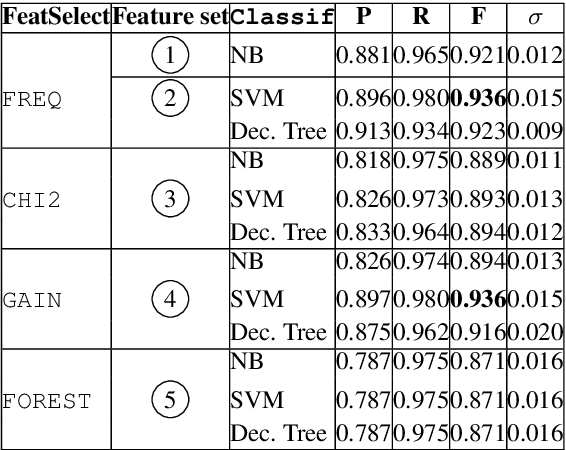

Automatic identification of mutiword expressions (MWEs) is a pre-requisite for semantically-oriented downstream applications. This task is challenging because MWEs, especially verbal ones (VMWEs), exhibit surface variability. However, this variability is usually more restricted than in regular (non-VMWE) constructions, which leads to various variability profiles. We use this fact to determine the optimal set of features which could be used in a supervised classification setting to solve a subproblem of VMWE identification: the identification of occurrences of previously seen VMWEs. Surprisingly, a simple custom frequency-based feature selection method proves more efficient than other standard methods such as Chi-squared test, information gain or decision trees. An SVM classifier using the optimal set of only 6 features outperforms the best systems from a recent shared task on the French seen data.
Methods to integrate a language model with semantic information for a word prediction component
Jan 30, 2008



Most current word prediction systems make use of n-gram language models (LM) to estimate the probability of the following word in a phrase. In the past years there have been many attempts to enrich such language models with further syntactic or semantic information. We want to explore the predictive powers of Latent Semantic Analysis (LSA), a method that has been shown to provide reliable information on long-distance semantic dependencies between words in a context. We present and evaluate here several methods that integrate LSA-based information with a standard language model: a semantic cache, partial reranking, and different forms of interpolation. We found that all methods show significant improvements, compared to the 4-gram baseline, and most of them to a simple cache model as well.