 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing RNN from Using Sequence Length as a Feature
Dec 16, 2022Recurrent neural networks are deep learning topologies that can be trained to classify long documents. However, in our recent work, we found a critical problem with these cells: they can use the length differences between texts of different classes as a prominent classification feature. This has the effect of producing models that are brittle and fragile to concept drift, can provide misleading performances and are trivially explainable regardless of text content. This paper illustrates the problem using synthetic and real-world data and provides a simple solution using weight decay regularization.
Reducing Sequence Length Learning Impacts on Transformer Models
Dec 16, 2022Classification algorithms using Transformer architectures can be affected by the sequence length learning problem whenever observations from different classes have a different length distribution. This problem brings models to use sequence length as a predictive feature instead of relying on important textual information. Even if most public datasets are not affected by this problem, privately corpora for fields such as medicine and insurance may carry this data bias. This poses challenges throughout the value chain given their usage in a machine learning application. In this paper, we empirically expose this problem and present approaches to minimize its impacts.
Beer2Vec : Extracting Flavors from Reviews for Thirst-Quenching Recommandations
Aug 04, 2022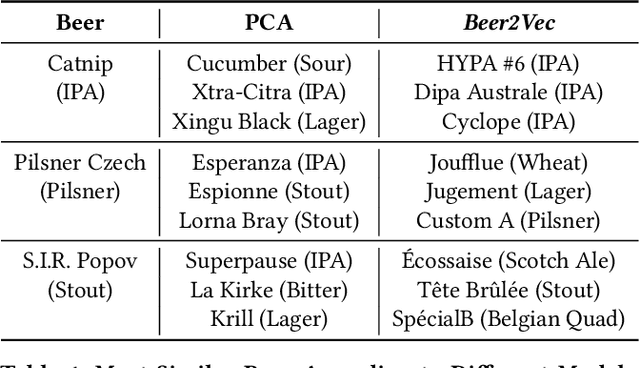
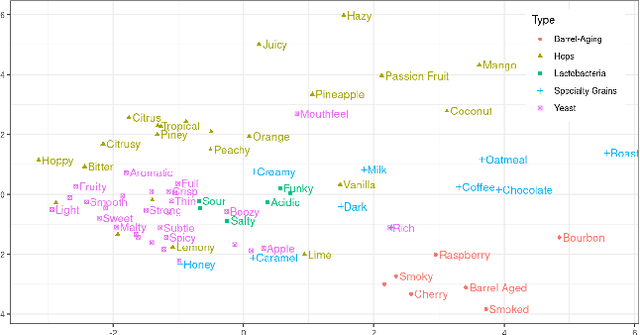
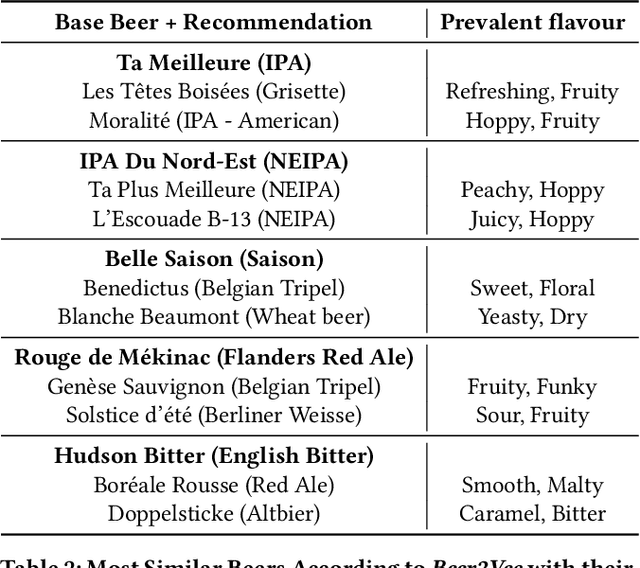
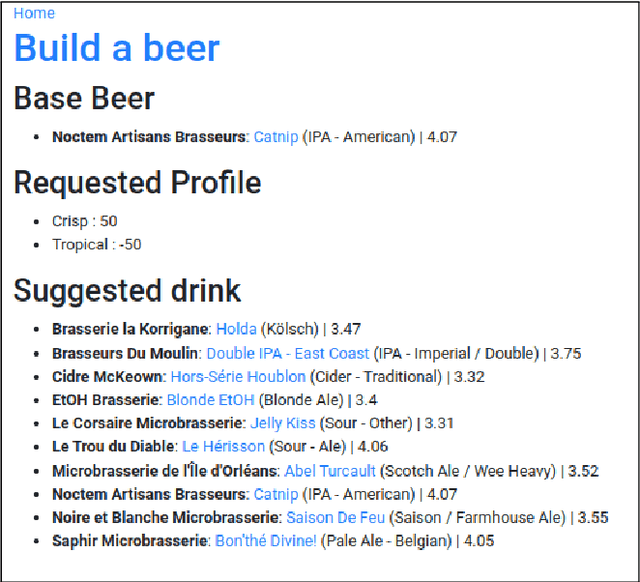
This paper introduces the Beer2Vec model that allows the most popular alcoholic beverage in the world to be encoded into vectors enabling flavorful recommendations. We present our algorithm using a unique dataset focused on the analysis of craft beers. We thoroughly explain how we encode the flavors and how useful, from an empirical point of view, the beer vectors are to generate meaningful recommendations. We also present three different ways to use Beer2Vec in a real-world environment to enlighten the pool of craft beer consumers. Finally, we make our model and functionalities available to everybody through a web application.