 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTelematics Combined Actuarial Neural Networks for Cross-Sectional and Longitudinal Claim Count Data
Aug 03, 2023We present novel cross-sectional and longitudinal claim count models for vehicle insurance built upon the Combined Actuarial Neural Network (CANN) framework proposed by Mario W\"uthrich and Michael Merz. The CANN approach combines a classical actuarial model, such as a generalized linear model, with a neural network. This blending of models results in a two-component model comprising a classical regression model and a neural network part. The CANN model leverages the strengths of both components, providing a solid foundation and interpretability from the classical model while harnessing the flexibility and capacity to capture intricate relationships and interactions offered by the neural network. In our proposed models, we use well-known log-linear claim count regression models for the classical regression part and a multilayer perceptron (MLP) for the neural network part. The MLP part is used to process telematics car driving data given as a vector characterizing the driving behavior of each insured driver. In addition to the Poisson and negative binomial distributions for cross-sectional data, we propose a procedure for training our CANN model with a multivariate negative binomial (MVNB) specification. By doing so, we introduce a longitudinal model that accounts for the dependence between contracts from the same insured. Our results reveal that the CANN models exhibit superior performance compared to log-linear models that rely on manually engineered telematics features.
Enhancing Claim Classification with Feature Extraction from Anomaly-Detection-Derived Routine and Peculiarity Profiles
Sep 26, 2022

Usage-based insurance is becoming the new standard in vehicle insurance; it is therefore relevant to find efficient ways of using insureds' driving data. Applying anomaly detection to vehicles' trip summaries, we develop a method allowing to derive a "routine" and a "peculiarity" anomaly profile for each vehicle. To this end, anomaly detection algorithms are used to compute a routine and a peculiarity anomaly score for each trip a vehicle makes. The former measures the anomaly degree of the trip compared to the other trips made by the concerned vehicle, while the latter measures its anomaly degree compared to trips made by any vehicle. The resulting anomaly scores vectors are used as routine and peculiarity profiles. Features are then extracted from these profiles, for which we investigate the predictive power in the claim classification framework. Using real data, we find that features extracted from the vehicles' peculiarity profile improve classification.
Synthetic Dataset Generation of Driver Telematics
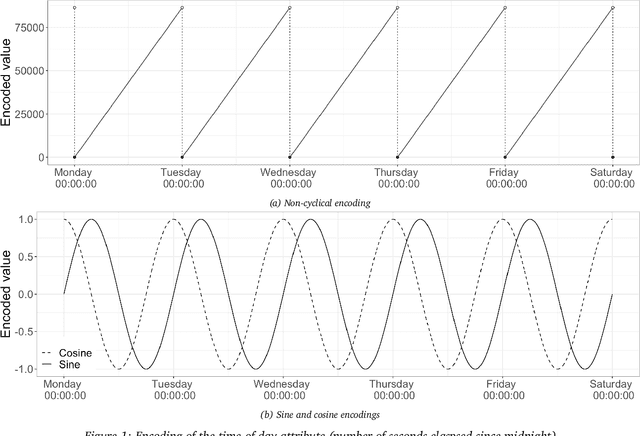
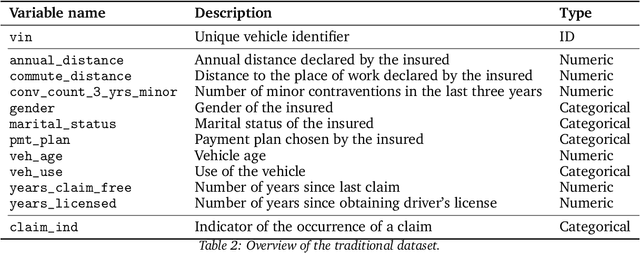
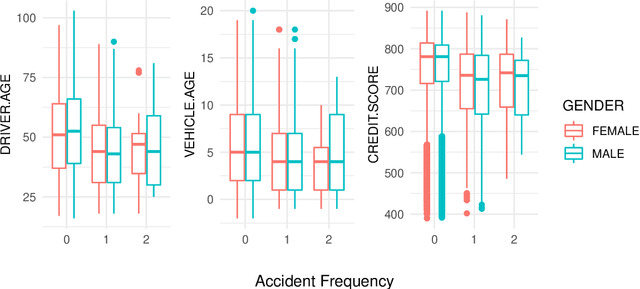
Jan 30, 2021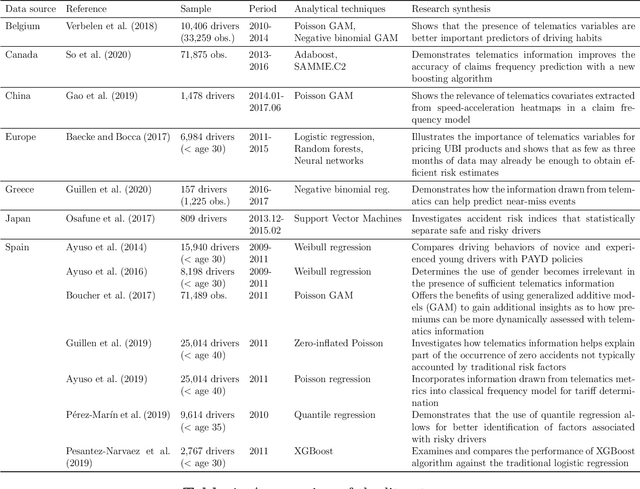



This article describes techniques employed in the production of a synthetic dataset of driver telematics emulated from a similar real insurance dataset. The synthetic dataset generated has 100,000 policies that included observations about driver's claims experience together with associated classical risk variables and telematics-related variables. This work is aimed to produce a resource that can be used to advance models to assess risks for usage-based insurance. It follows a three-stage process using machine learning algorithms. The first stage is simulating values for the number of claims as multiple binary classifications applying feedforward neural networks. The second stage is simulating values for aggregated amount of claims as regression using feedforward neural networks, with number of claims included in the set of feature variables. In the final stage, a synthetic portfolio of the space of feature variables is generated applying an extended $\texttt{SMOTE}$ algorithm. The resulting dataset is evaluated by comparing the synthetic and real datasets when Poisson and gamma regression models are fitted to the respective data. Other visualization and data summarization produce remarkable similar statistics between the two datasets. We hope that researchers interested in obtaining telematics datasets to calibrate models or learning algorithms will find our work valuable.
Cost-sensitive Multi-class AdaBoost for Understanding Driving Behavior with Telematics
Jul 06, 2020


Powered with telematics technology, insurers can now capture a wide range of data, such as distance traveled, how drivers brake, accelerate or make turns, and travel frequency each day of the week, to better decode driver's behavior. Such additional information helps insurers improve risk assessments for usage-based insurance (UBI), an increasingly popular industry innovation. In this article, we explore how to integrate telematics information to better predict claims frequency. For motor insurance during a policy year, we typically observe a large proportion of drivers with zero claims, a less proportion with exactly one claim, and far lesser with two or more claims. We introduce the use of a cost-sensitive multi-class adaptive boosting (AdaBoost) algorithm, which we call SAMME.C2, to handle such imbalances. To calibrate SAMME.C2 algorithm, we use empirical data collected from a telematics program in Canada and we find improved assessment of driving behavior with telematics relative to traditional risk variables. We demonstrate our algorithm can outperform other models that can handle class imbalances: SAMME, SAMME with SMOTE, RUSBoost, and SMOTEBoost. The sampled data on telematics were observations during 2013-2016 for which 50,301 are used for training and another 21,574 for testing. Broadly speaking, the additional information derived from vehicle telematics helps refine risk classification of drivers of UBI.