 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGait analysis with curvature maps: A simulation study
Jun 22, 2021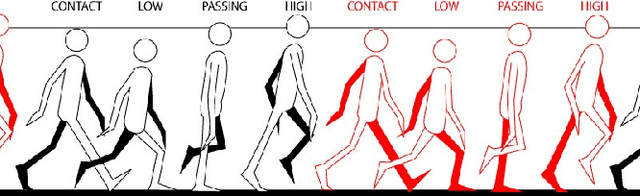

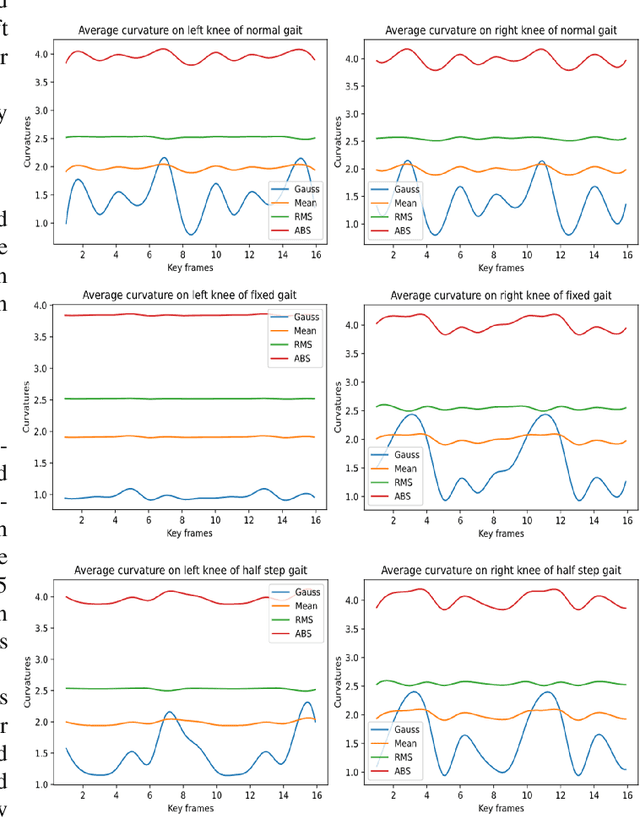
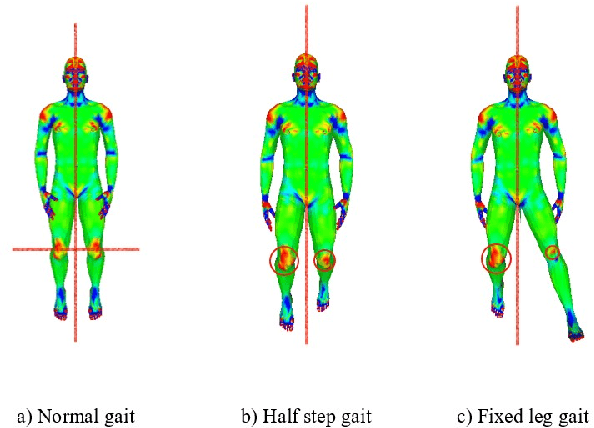
Gait analysis is an important aspect of clinical investigation for detecting neurological and musculoskeletal disorders and assessing the global health of a patient. In this paper we propose to focus our attention on extracting relevant curvature information from the body surface provided by a depth camera. We assumed that the 3D mesh was made available in a previous step and demonstrated how curvature maps could be useful to assess asymmetric anomalies with two simple simulated abnormal gaits compared with a normal one. This research set the grounds for the future development of a curvature-based gait analysis system for healthcare professionals.
Anomaly Detection in Video Sequence with Appearance-Motion Correspondence
Aug 17, 2019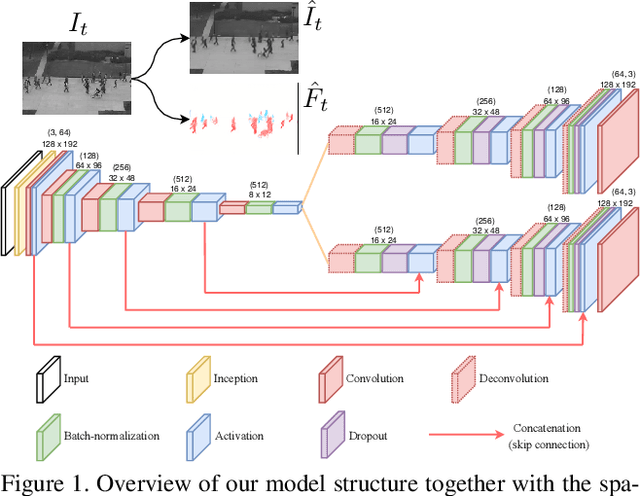
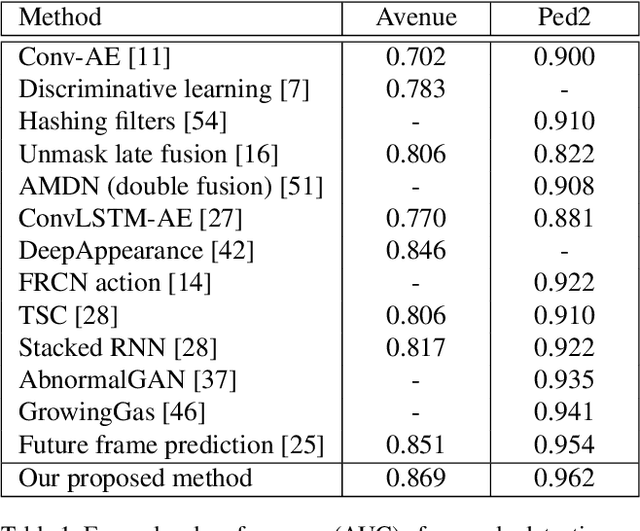
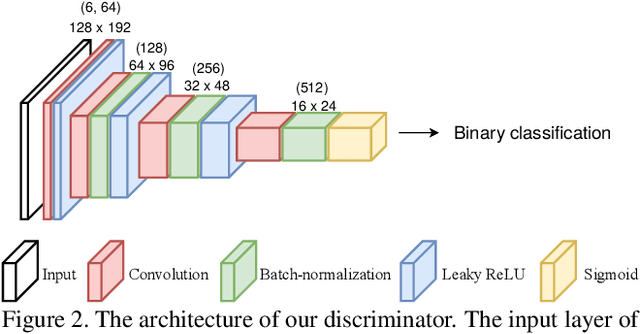
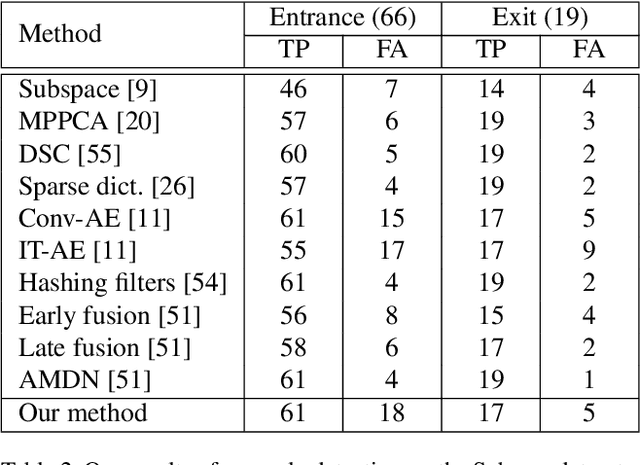
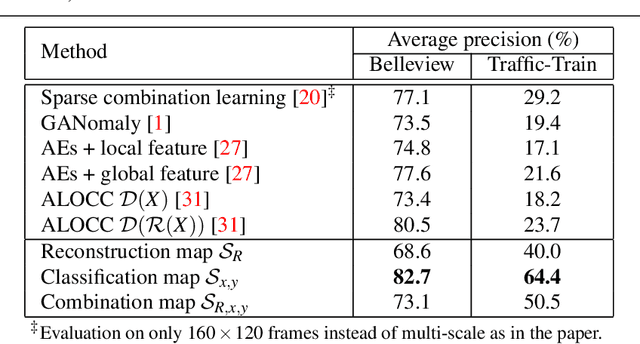
Anomaly detection in surveillance videos is currently a challenge because of the diversity of possible events. We propose a deep convolutional neural network (CNN) that addresses this problem by learning a correspondence between common object appearances (e.g. pedestrian, background, tree, etc.) and their associated motions. Our model is designed as a combination of a reconstruction network and an image translation model that share the same encoder. The former sub-network determines the most significant structures that appear in video frames and the latter one attempts to associate motion templates to such structures. The training stage is performed using only videos of normal events and the model is then capable to estimate frame-level scores for an unknown input. The experiments on 6 benchmark datasets demonstrate the competitive performance of the proposed approach with respect to state-of-the-art methods.
Hybrid Deep Network for Anomaly Detection
Aug 17, 2019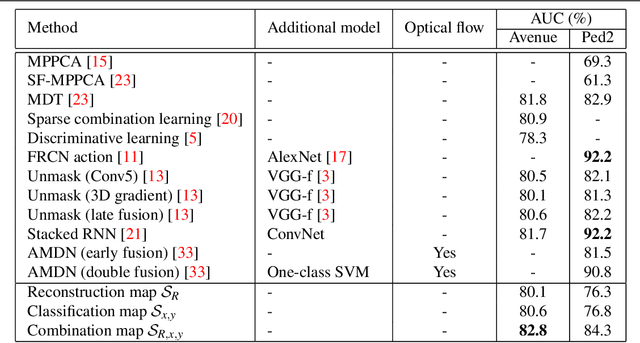
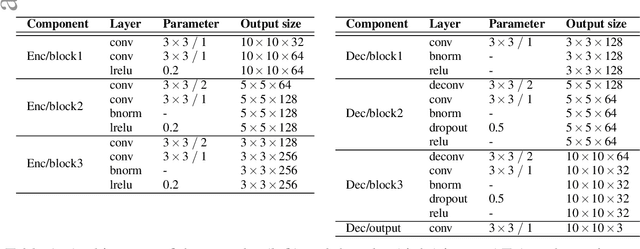

In this paper, we propose a deep convolutional neural network (CNN) for anomaly detection in surveillance videos. The model is adapted from a typical auto-encoder working on video patches under the perspective of sparse combination learning. Our CNN focuses on (unsupervisedly) learning common characteristics of normal events with the emphasis of their spatial locations (by supervised losses). To our knowledge, this is the first work that directly adapts the patch position as the target of a classification sub-network. The model is capable to provide a score of anomaly assessment for each video frame. Our experiments were performed on 4 benchmark datasets with various anomalous events and the obtained results were competitive with state-of-the-art studies.
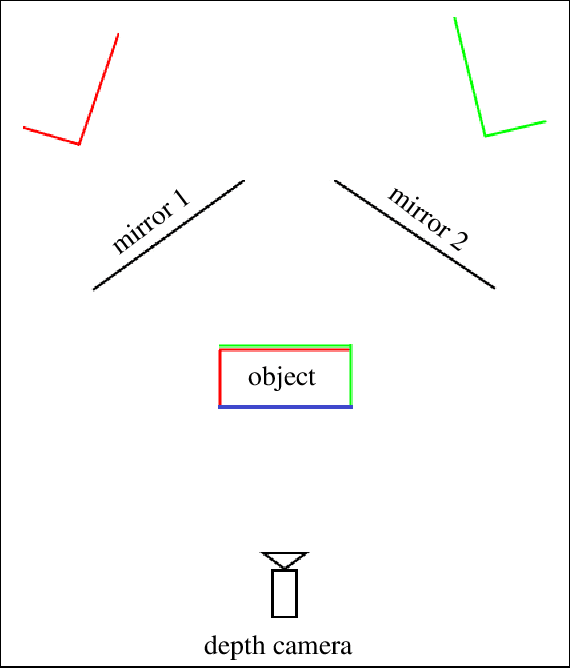
Matching-based Depth Camera and Mirrors for 3D Reconstruction
Aug 17, 2019Reconstructing 3D object models is playing an important role in many applications in the field of computer vision. Instead of employing a collection of cameras and/or sensors as in many studies, this paper proposes a simple way to build a cheaper system for 3D reconstruction using only one depth camera and 2 or more mirrors. Each mirror is equivalently considered as a depth camera at another viewpoint. Since all scene data are provided by only one depth sensor, our approach can be applied to moving objects and does not require any synchronization protocol as with a set of cameras. Some experiments were performed on easy-to-evaluate objects to confirm the reconstruction accuracy of our proposed system.
Estimating skeleton-based gait abnormality index by sparse deep auto-encoder
Aug 17, 2019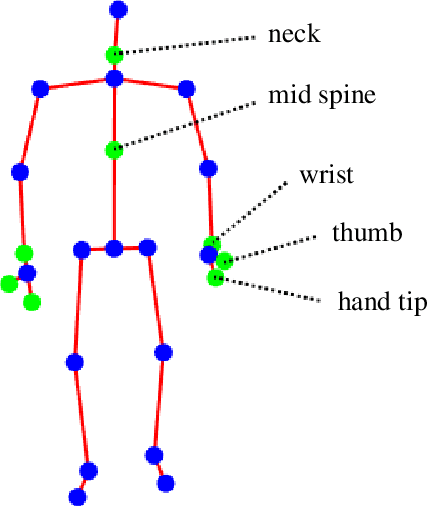
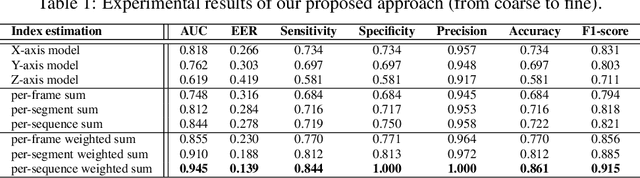
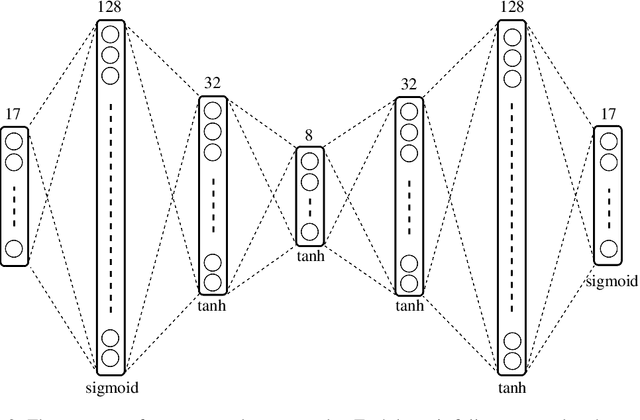
This paper proposes an approach estimating a gait abnormality index based on skeletal information provided by a depth camera. Differently from related works where the extraction of hand-crafted features is required to describe gait characteristics, our method automatically performs that stage with the support of a deep auto-encoder. In order to get visually interpretable features, we embedded a constraint of sparsity into the model. Similarly to most gait-related studies, the temporal factor is also considered as a post-processing in our system. This method provided promising results when experimenting on a dataset containing nearly one hundred thousand skeleton samples.
Skeleton-based Gait Index Estimation with LSTMs
Aug 17, 2019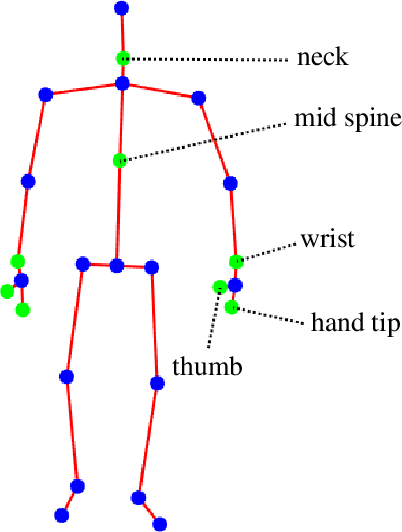
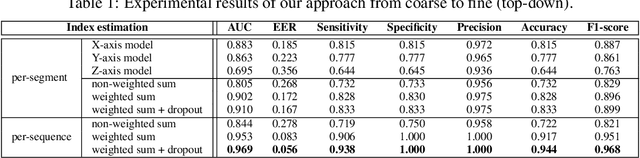
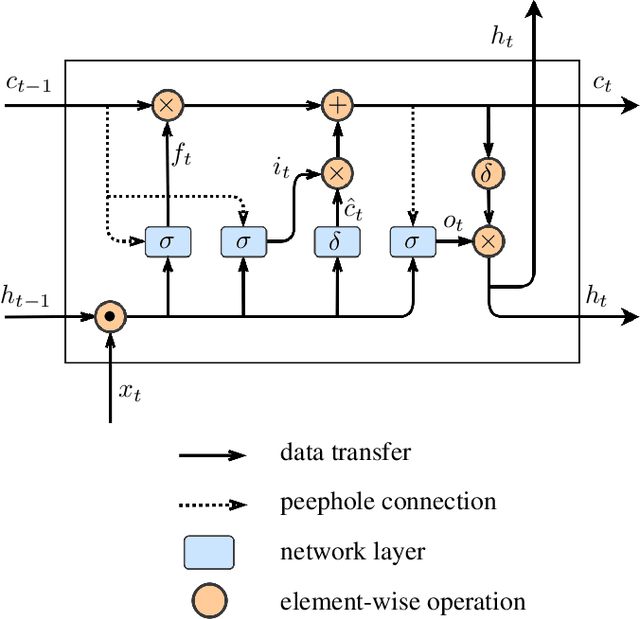
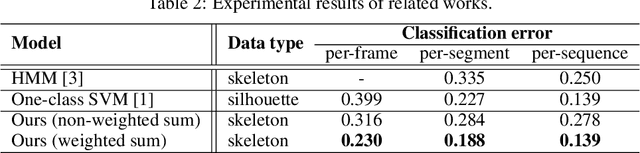
In this paper, we propose a method that estimates a gait index for a sequence of skeletons. Our system is a stack of an encoder and a decoder that are formed by Long Short-Term Memories (LSTMs). In the encoding stage, the characteristics of an input are automatically determined and are compressed into a latent space. The decoding stage then attempts to reconstruct the input according to such intermediate representation. The reconstruction error is thus considered as a weak gait index. By combining such weak indices over a long-time movement, our system can provide a good estimation for the gait index. Our experiments on a large dataset (nearly one hundred thousand skeletons) showed that the index given by the proposed method outperformed some recent works on gait analysis.
Assessment of gait normality using a depth camera and mirrors
Aug 17, 2019


This paper presents an initial work on assessment of gait normality in which the human body motion is represented by a sequence of enhanced depth maps. The input data is provided by a system consisting of a Time-of-Flight (ToF) depth camera and two mirrors. This approach proposes two feature types to describe characteristics of localized points of interest and the level of posture symmetry. These two features are processed on a sequence of enhanced depth maps with the support of a sliding window to provide two corresponding scores. The gait assessment is finally performed based on a weighted combination of these two scores. The evaluation is performed by experimenting on 6 simulated abnormal gaits.
Human Gait Symmetry Assessment using a Depth Camera and Mirrors
Aug 16, 2019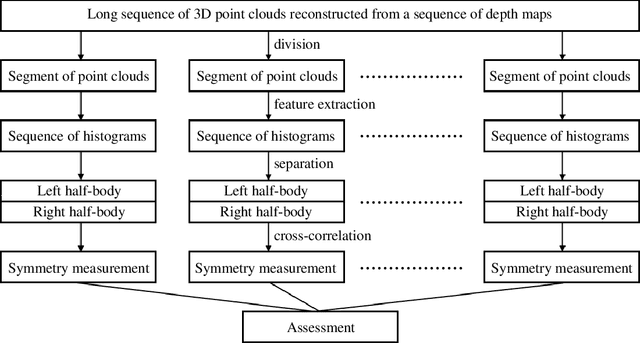

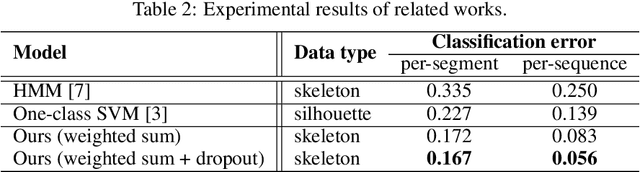
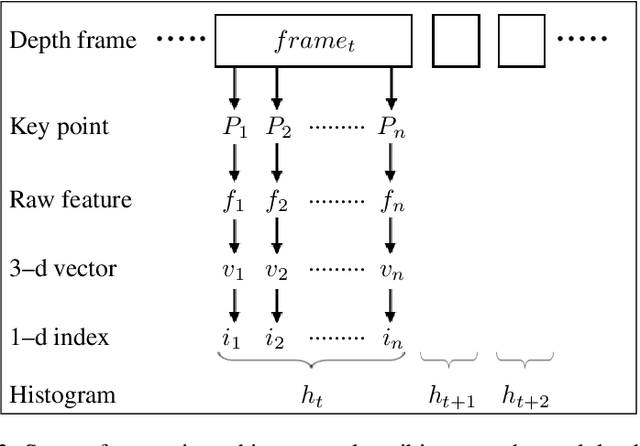
This paper proposes a reliable approach for human gait symmetry assessment using a depth camera and two mirrors. The input of our system is a sequence of 3D point clouds which are formed from a setup including a Time-of-Flight (ToF) depth camera and two mirrors. A cylindrical histogram is estimated for describing the posture in each point cloud. The sequence of such histograms is then separated into two sequences of sub-histograms representing two half-bodies. A cross-correlation technique is finally applied to provide values describing gait symmetry indices. The evaluation was performed on 9 different gait types to demonstrate the ability of our approach in assessing gait symmetry. A comparison between our system and related methods, that employ different input data types, is also provided.
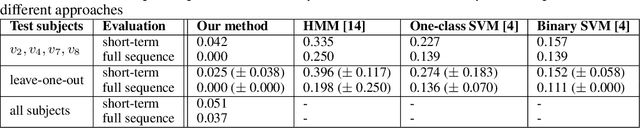
Applying Adversarial Auto-encoder for Estimating Human Walking Gait Abnormality Index
Aug 16, 2019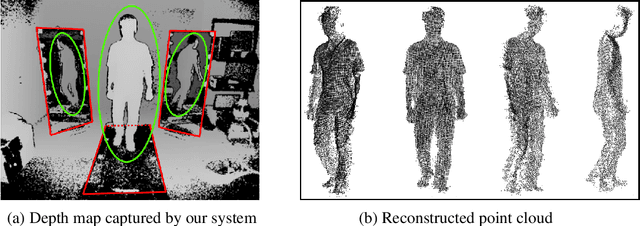

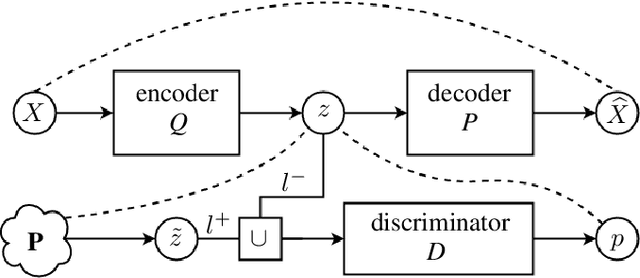
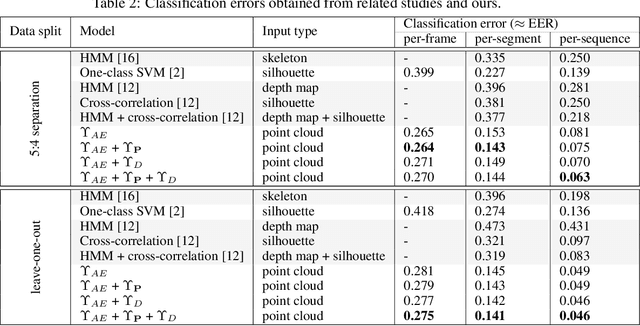
This paper proposes an approach that estimates human walking gait quality index using an adversarial auto-encoder (AAE), i.e. a combination of auto-encoder and generative adversarial network (GAN). Since most GAN-based models have been employed as data generators, our work introduces another perspective of their application. This method directly works on a sequence of 3D point clouds representing the walking postures of a subject. By fitting a cylinder onto each point cloud and feeding obtained histograms to an appropriate AAE, our system is able to provide different measures that may be used as gait quality indices. The combinations of such quantities are also investigated to obtain improved indicators. The ability of our method is demonstrated by experimenting on a large dataset of nearly 100 thousands point clouds and the results outperform related approaches that employ different input data types.
Comparative study of motion detection methods for video surveillance systems
Apr 16, 2018The objective of this study is to compare several change detection methods for a mono static camera and identify the best method for different complex environments and backgrounds in indoor and outdoor scenes. To this end, we used the CDnet video dataset as a benchmark that consists of many challenging problems, ranging from basic simple scenes to complex scenes affected by bad weather and dynamic backgrounds. Twelve change detection methods, ranging from simple temporal differencing to more sophisticated methods, were tested and several performance metrics were used to precisely evaluate the results. Because most of the considered methods have not previously been evaluated on this recent large scale dataset, this work compares these methods to fill a lack in the literature, and thus this evaluation joins as complementary compared with the previous comparative evaluations. Our experimental results show that there is no perfect method for all challenging cases, each method performs well in certain cases and fails in others. However, this study enables the user to identify the most suitable method for his or her needs.
* 69 pages, 18 figures, journal paper