 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStockBabble: A Conversational Financial Agent to support Stock Market Investors
Jun 15, 2021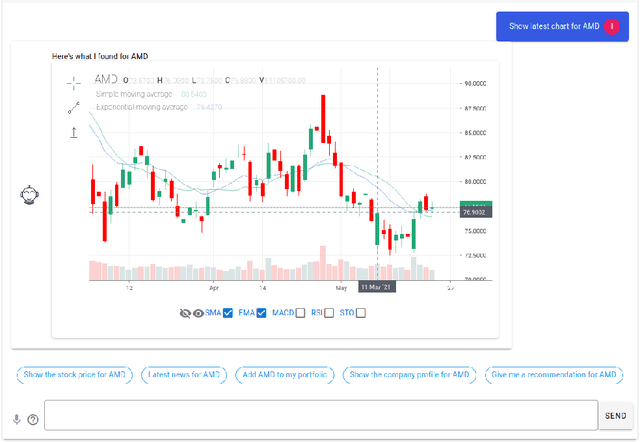
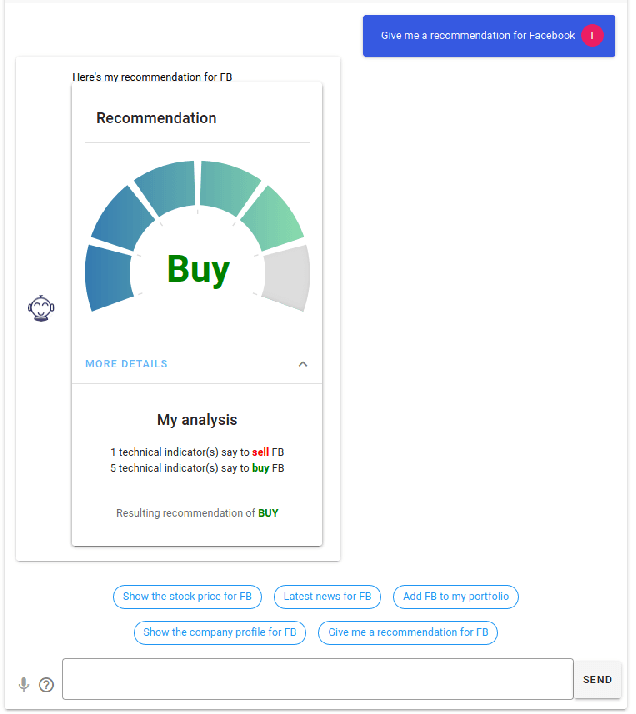
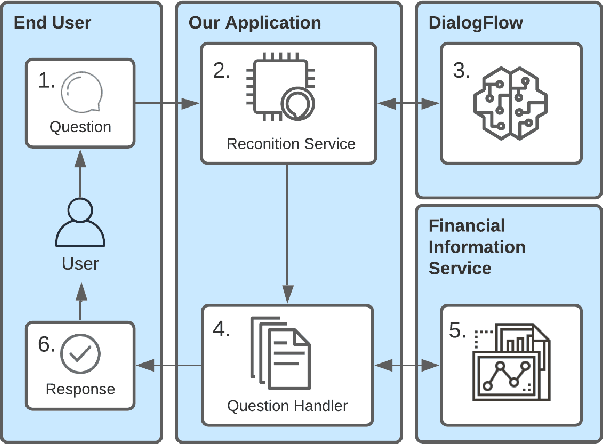
We introduce StockBabble, a conversational agent designed to support understanding and engagement with the stock market. StockBabble's value and novelty is in its ability to empower retail investors -- many of which may be new to investing -- and supplement their informational needs using a user-friendly agent. Users have the ability to query information on companies to retrieve a general and financial overview of a stock, including accessing the latest news and trading recommendations. They can also request charts which contain live prices and technical investment indicators, and add shares to a personal portfolio to allow performance monitoring over time. To evaluate our agent's potential, we conducted a user study with 15 participants. In total, 73% (11/15) of respondents said that they felt more confident in investing after using StockBabble, and all 15 would consider recommending it to others. These results are encouraging and suggest a wider appeal for such agents. Moreover, we believe this research can help to inform the design and development of future intelligent, financial personal assistants.
The Shadowy Lives of Emojis: An Analysis of a Hacktivist Collective's Use of Emojis on Twitter
May 07, 2021
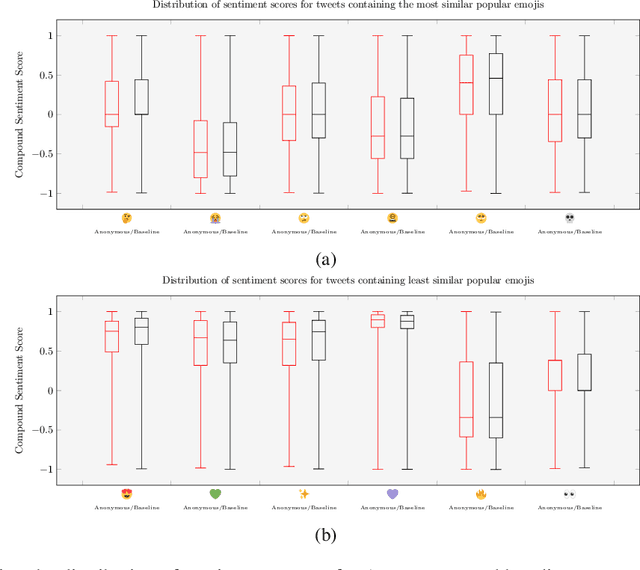

Emojis have established themselves as a popular means of communication in online messaging. Despite the apparent ubiquity in these image-based tokens, however, interpretation and ambiguity may allow for unique uses of emojis to appear. In this paper, we present the first examination of emoji usage by hacktivist groups via a study of the Anonymous collective on Twitter. This research aims to identify whether Anonymous affiliates have evolved their own approach to using emojis. To do this, we compare a large dataset of Anonymous tweets to a baseline tweet dataset from randomly sampled Twitter users using computational and qualitative analysis to compare their emoji usage. We utilise Word2Vec language models to examine the semantic relationships between emojis, identifying clear distinctions in the emoji-emoji relationships of Anonymous users. We then explore how emojis are used as a means of conveying emotions, finding that despite little commonality in emoji-emoji semantic ties, Anonymous emoji usage displays similar patterns of emotional purpose to the emojis of baseline Twitter users. Finally, we explore the textual context in which these emojis occur, finding that although similarities exist between the emoji usage of our Anonymous and baseline Twitter datasets, Anonymous users appear to have adopted more specific interpretations of certain emojis. This includes the use of emojis as a means of expressing adoration and infatuation towards notable Anonymous affiliates. These findings indicate that emojis appear to retain a considerable degree of similarity within Anonymous accounts as compared to more typical Twitter users. However, their are signs that emoji usage in Anonymous accounts has evolved somewhat, gaining additional group-specific associations that reveal new insights into the behaviours of this unusual collective.
Behind the Mask: A Computational Study of Anonymous' Presence on Twitter
Jun 15, 2020


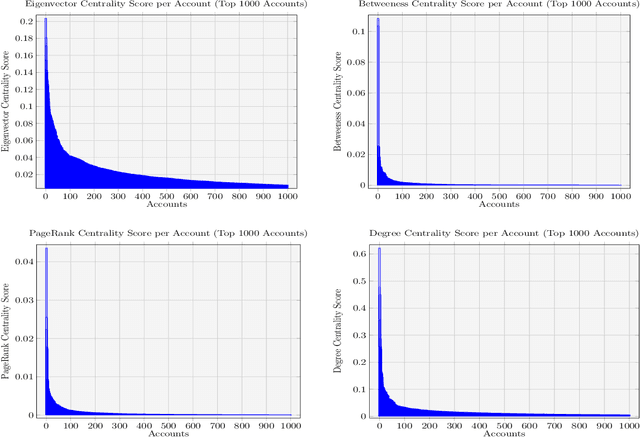
The hacktivist group Anonymous is unusual in its public-facing nature. Unlike other cybercriminal groups, which rely on secrecy and privacy for protection, Anonymous is prevalent on the social media site, Twitter. In this paper we re-examine some key findings reported in previous small-scale qualitative studies of the group using a large-scale computational analysis of Anonymous' presence on Twitter. We specifically refer to reports which reject the group's claims of leaderlessness, and indicate a fracturing of the group after the arrests of prominent members in 2011-2013. In our research, we present the first attempts to use machine learning to identify and analyse the presence of a network of over 20,000 Anonymous accounts spanning from 2008-2019 on the Twitter platform. In turn, this research utilises social network analysis (SNA) and centrality measures to examine the distribution of influence within this large network, identifying the presence of a small number of highly influential accounts. Moreover, we present the first study of tweets from some of the identified key influencer accounts and, through the use of topic modelling, demonstrate a similarity in overarching subjects of discussion between these prominent accounts. These findings provide robust, quantitative evidence to support the claims of smaller-scale, qualitative studies of the Anonymous collective.
* 12 pages, 5 figures. Published in the proceedings of the fourteenth International AAAI Conference on Web and Social Media
Is your chatbot GDPR compliant? Open issues in agent design
May 26, 2020Conversational agents open the world to new opportunities for human interaction and ubiquitous engagement. As their conversational abilities and knowledge has improved, these agents have begun to have access to an increasing variety of personally identifiable information and intimate details on their user base. This access raises crucial questions in light of regulations as robust as the General Data Protection Regulation (GDPR). This paper explores some of these questions, with the aim of defining relevant open issues in conversational agent design. We hope that this work can provoke further research into building agents that are effective at user interaction, but also respectful of regulations and user privacy.
Catching the Phish: Detecting Phishing Attacks using Recurrent Neural Networks (RNNs)
Aug 09, 2019

The emergence of online services in our daily lives has been accompanied by a range of malicious attempts to trick individuals into performing undesired actions, often to the benefit of the adversary. The most popular medium of these attempts is phishing attacks, particularly through emails and websites. In order to defend against such attacks, there is an urgent need for automated mechanisms to identify this malevolent content before it reaches users. Machine learning techniques have gradually become the standard for such classification problems. However, identifying common measurable features of phishing content (e.g., in emails) is notoriously difficult. To address this problem, we engage in a novel study into a phishing content classifier based on a recurrent neural network (RNN), which identifies such features without human input. At this stage, we scope our research to emails, but our approach can be extended to apply to websites. Our results show that the proposed system outperforms state-of-the-art tools. Furthermore, our classifier is efficient and takes into account only the text and, in particular, the textual structure of the email. Since these features are rarely considered in email classification, we argue that our classifier can complement existing classifiers with high information gain.
* 13 pages
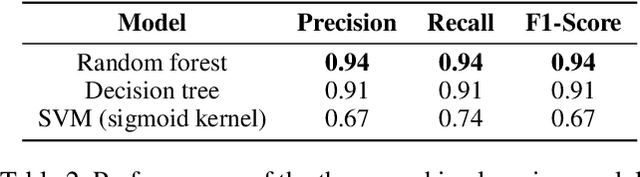
Understanding the Radical Mind: Identifying Signals to Detect Extremist Content on Twitter
May 15, 2019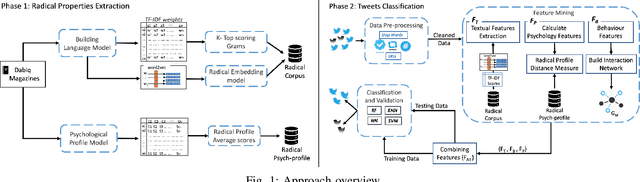
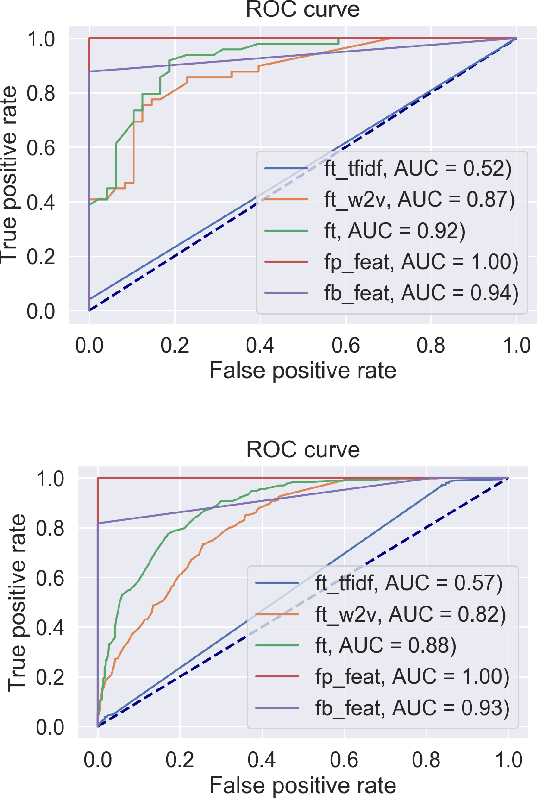
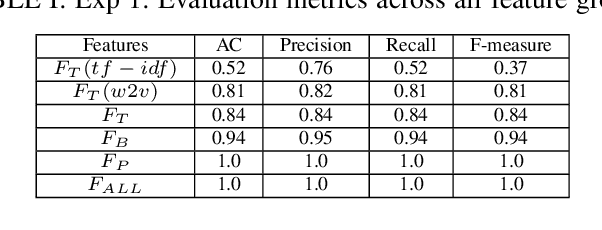
The Internet and, in particular, Online Social Networks have changed the way that terrorist and extremist groups can influence and radicalise individuals. Recent reports show that the mode of operation of these groups starts by exposing a wide audience to extremist material online, before migrating them to less open online platforms for further radicalization. Thus, identifying radical content online is crucial to limit the reach and spread of the extremist narrative. In this paper, our aim is to identify measures to automatically detect radical content in social media. We identify several signals, including textual, psychological and behavioural, that together allow for the classification of radical messages. Our contribution is three-fold: (1) we analyze propaganda material published by extremist groups and create a contextual text-based model of radical content, (2) we build a model of psychological properties inferred from these material, and (3) we evaluate these models on Twitter to determine the extent to which it is possible to automatically identify online radical tweets. Our results show that radical users do exhibit distinguishable textual, psychological, and behavioural properties. We find that the psychological properties are among the most distinguishing features. Additionally, our results show that textual models using vector embedding features significantly improves the detection over TF-IDF features. We validate our approach on two experiments achieving high accuracy. Our findings can be utilized as signals for detecting online radicalization activities.
A semi-supervised approach to message stance classification
Jan 29, 2019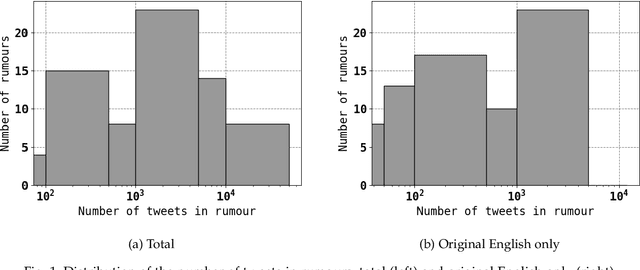
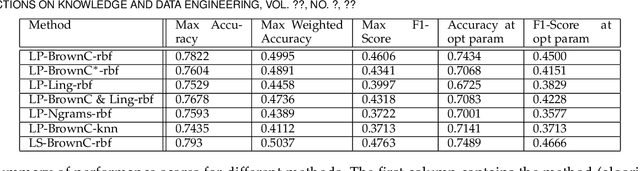
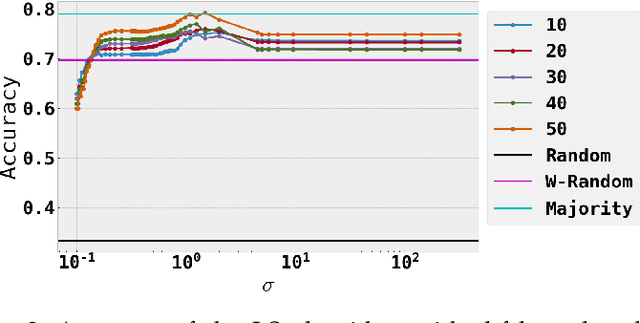
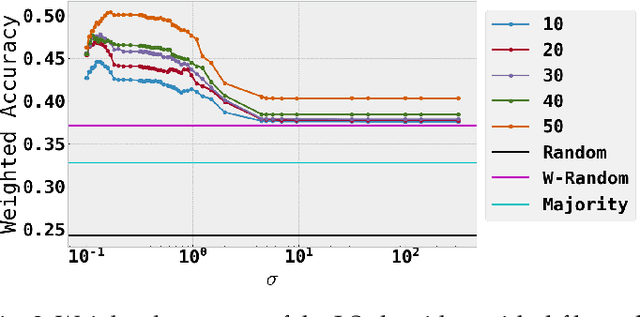
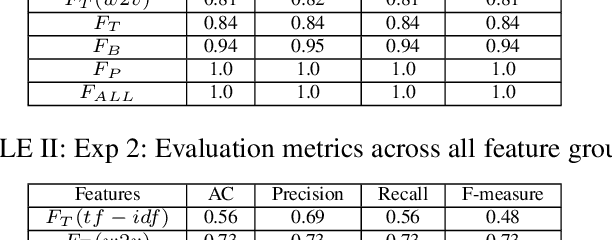
Social media communications are becoming increasingly prevalent; some useful, some false, whether unwittingly or maliciously. An increasing number of rumours daily flood the social networks. Determining their veracity in an autonomous way is a very active and challenging field of research, with a variety of methods proposed. However, most of the models rely on determining the constituent messages' stance towards the rumour, a feature known as the "wisdom of the crowd". Although several supervised machine-learning approaches have been proposed to tackle the message stance classification problem, these have numerous shortcomings. In this paper we argue that semi-supervised learning is more effective than supervised models and use two graph-based methods to demonstrate it. This is not only in terms of classification accuracy, but equally important, in terms of speed and scalability. We use the Label Propagation and Label Spreading algorithms and run experiments on a dataset of 72 rumours and hundreds of thousands messages collected from Twitter. We compare our results on two available datasets to the state-of-the-art to demonstrate our algorithms' performance regarding accuracy, speed and scalability for real-time applications.
* 33 pages, 8 figures, 1 table
A Storm in an IoT Cup: The Emergence of Cyber-Physical Social Machines
Sep 16, 2018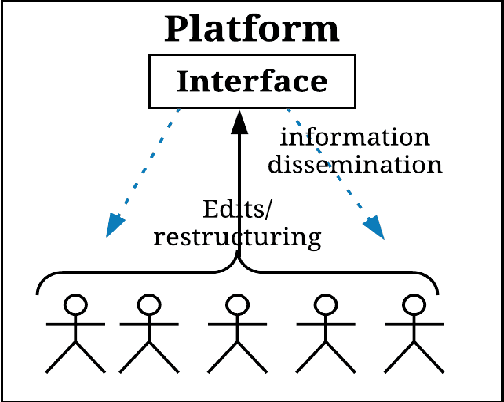
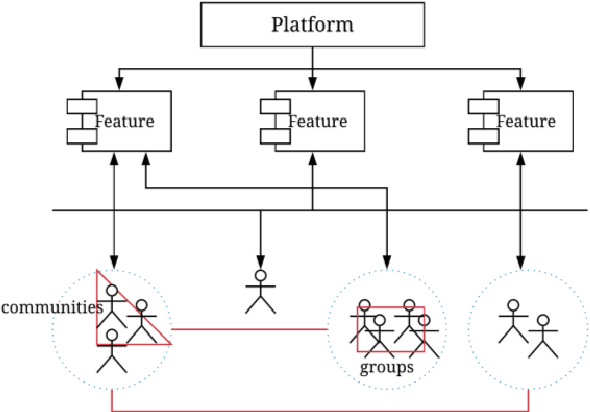
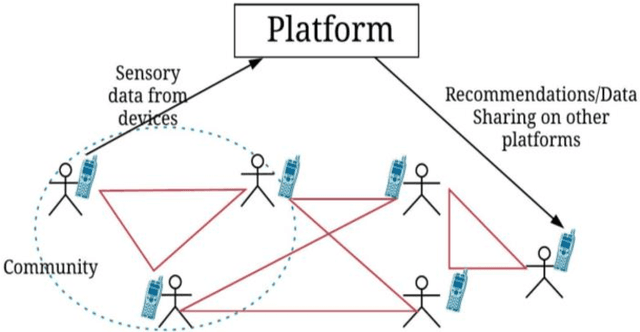
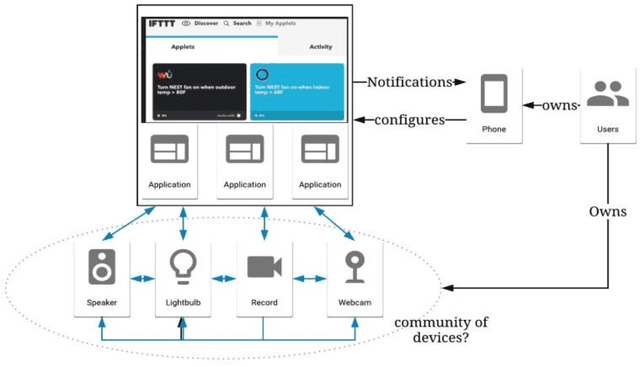
The concept of social machines is increasingly being used to characterise various socio-cognitive spaces on the Web. Social machines are human collectives using networked digital technology which initiate real-world processes and activities including human communication, interactions and knowledge creation. As such, they continuously emerge and fade on the Web. The relationship between humans and machines is made more complex by the adoption of Internet of Things (IoT) sensors and devices. The scale, automation, continuous sensing, and actuation capabilities of these devices add an extra dimension to the relationship between humans and machines making it difficult to understand their evolution at either the systemic or the conceptual level. This article describes these new socio-technical systems, which we term Cyber-Physical Social Machines, through different exemplars, and considers the associated challenges of security and privacy.
Using semantic clustering to support situation awareness on Twitter: The case of World Views
Jul 17, 2018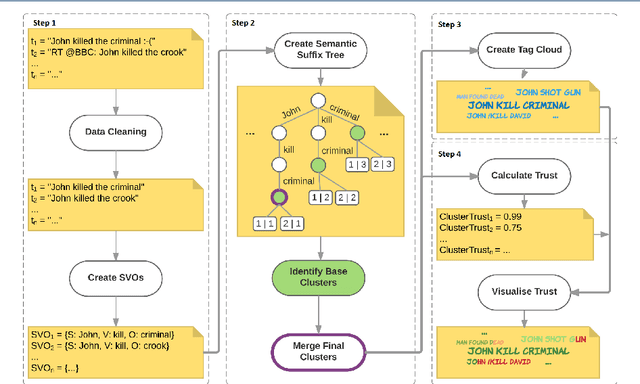



In recent years, situation awareness has been recognised as a critical part of effective decision making, in particular for crisis management. One way to extract value and allow for better situation awareness is to develop a system capable of analysing a dataset of multiple posts, and clustering consistent posts into different views or stories (or, world views). However, this can be challenging as it requires an understanding of the data, including determining what is consistent data, and what data corroborates other data. Attempting to address these problems, this article proposes Subject-Verb-Object Semantic Suffix Tree Clustering (SVOSSTC) and a system to support it, with a special focus on Twitter content. The novelty and value of SVOSSTC is its emphasis on utilising the Subject-Verb-Object (SVO) typology in order to construct semantically consistent world views, in which individuals---particularly those involved in crisis response---might achieve an enhanced picture of a situation from social media data. To evaluate our system and its ability to provide enhanced situation awareness, we tested it against existing approaches, including human data analysis, using a variety of real-world scenarios. The results indicated a noteworthy degree of evidence (e.g., in cluster granularity and meaningfulness) to affirm the suitability and rigour of our approach. Moreover, these results highlight this article's proposals as innovative and practical system contributions to the research field.
Determining the Veracity of Rumours on Twitter
Nov 19, 2016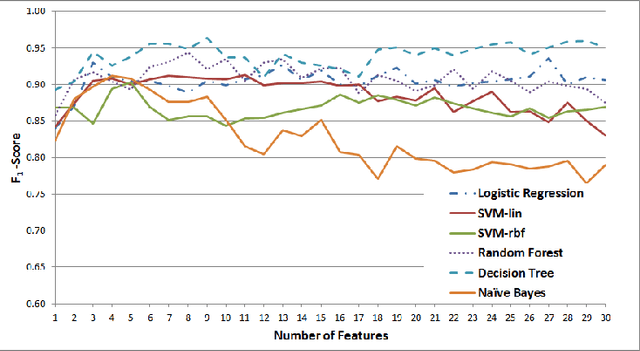

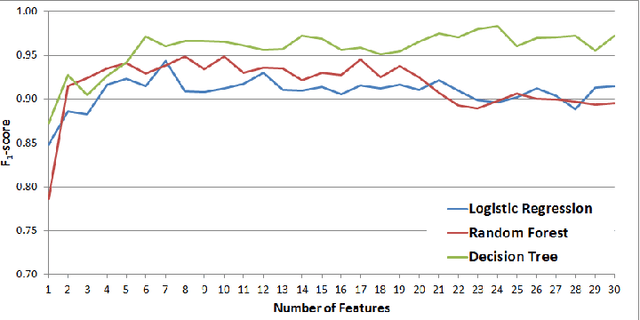
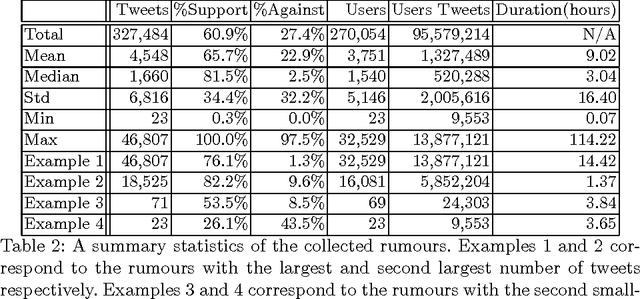
While social networks can provide an ideal platform for up-to-date information from individuals across the world, it has also proved to be a place where rumours fester and accidental or deliberate misinformation often emerges. In this article, we aim to support the task of making sense from social media data, and specifically, seek to build an autonomous message-classifier that filters relevant and trustworthy information from Twitter. For our work, we collected about 100 million public tweets, including users' past tweets, from which we identified 72 rumours (41 true, 31 false). We considered over 80 trustworthiness measures including the authors' profile and past behaviour, the social network connections (graphs), and the content of tweets themselves. We ran modern machine-learning classifiers over those measures to produce trustworthiness scores at various time windows from the outbreak of the rumour. Such time-windows were key as they allowed useful insight into the progression of the rumours. From our findings, we identified that our model was significantly more accurate than similar studies in the literature. We also identified critical attributes of the data that give rise to the trustworthiness scores assigned. Finally we developed a software demonstration that provides a visual user interface to allow the user to examine the analysis.
* 21 pages, 6 figures, 2 tables