 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatenrgy: Model Agnostic Latency and Energy Consumption Prediction for Binary Classifiers
Dec 26, 2024Machine learning systems increasingly drive innovation across scientific fields and industry, yet challenges in compute overhead, specifically during inference, limit their scalability and sustainability. Responsible AI guardrails, essential for ensuring fairness, transparency, and privacy, further exacerbate these computational demands. This study addresses critical gaps in the literature, chiefly the lack of generalized predictive techniques for latency and energy consumption, limited cross-comparisons of classifiers, and unquantified impacts of RAI guardrails on inference performance. Using Theory Construction Methodology, this work constructed a model-agnostic theoretical framework for predicting latency and energy consumption in binary classification models during inference. The framework synthesizes classifier characteristics, dataset properties, and RAI guardrails into a unified analytical instrument. Two predictive equations are derived that capture the interplay between these factors while offering generalizability across diverse classifiers. The proposed framework provides foundational insights for designing efficient, responsible ML systems. It enables researchers to benchmark and optimize inference performance and assists practitioners in deploying scalable solutions. Finally, this work establishes a theoretical foundation for balancing computational efficiency with ethical AI principles, paving the way for future empirical validation and broader applications.
A Measure for Level of Autonomy Based on Observable System Behavior
Jul 20, 2024



Contemporary artificial intelligence systems are pivotal in enhancing human efficiency and safety across various domains. One such domain is autonomous systems, especially in automotive and defense use cases. Artificial intelligence brings learning and enhanced decision-making to autonomy system goal-oriented behaviors and human independence. However, the lack of clear understanding of autonomy system capabilities hampers human-machine or machine-machine interaction and interdiction. This necessitates varying degrees of human involvement for safety, accountability, and explainability purposes. Yet, measuring the level autonomous capability in an autonomous system presents a challenge. Two scales of measurement exist, yet measuring autonomy presupposes a variety of elements not available in the wild. This is why existing measures for level of autonomy are operationalized only during design or test and evaluation phases. No measure for level of autonomy based on observed system behavior exists at this time. To address this, we outline a potential measure for predicting level of autonomy using observable actions. We also present an algorithm incorporating the proposed measure. The measure and algorithm have significance to researchers and practitioners interested in a method to blind compare autonomous systems at runtime. Defense-based implementations are likewise possible because counter-autonomy depends on robust identification of autonomous systems.
Reproducing Random Forest Efficacy in Detecting Port Scanning
Feb 18, 2023Port scanning is the process of attempting to connect to various network ports on a computing endpoint to determine which ports are open and which services are running on them. It is a common method used by hackers to identify vulnerabilities in a network or system. By determining which ports are open, an attacker can identify which services and applications are running on a device and potentially exploit any known vulnerabilities in those services. Consequently, it is important to detect port scanning because it is often the first step in a cyber attack. By identifying port scanning attempts, cybersecurity professionals can take proactive measures to protect the systems and networks before an attacker has a chance to exploit any vulnerabilities. Against this background, researchers have worked for over a decade to develop robust methods to detect port scanning. One such method revealed by a recent systematic review is the random forest supervised machine learning algorithm. The review revealed six existing studies using random forest since 2021. Unfortunately, those studies each exhibit different results, do not all use the same training and testing dataset, and only two include source code. Accordingly, the goal of this work was to reproduce the six random forest studies while addressing the apparent shortcomings. The outcomes are significant for researchers looking to explore random forest to detect port scanning and for practitioners interested in reliable technology to detect the early stages of cyber attack.
Detecting Synthetic Phenomenology in a Contained Artificial General Intelligence
Nov 06, 2020Human-like intelligence in a machine is a contentious subject. Whether mankind should or should not pursue the creation of artificial general intelligence is hotly debated. As well, researchers have aligned in opposing factions according to whether mankind can create it. For our purposes, we assume mankind can and will do so. Thus, it becomes necessary to contemplate how to do so in a safe and trusted manner -- enter the idea of boxing or containment. As part of such thinking, we wonder how a phenomenology might be detected given the operational constraints imposed by any potential containment system. Accordingly, this work provides an analysis of existing measures of phenomenology through qualia and extends those ideas into the context of a contained artificial general intelligence.
Stovepiping and Malicious Software: A Critical Review of AGI Containment
Nov 08, 2018Awareness of the possible impacts associated with artificial intelligence has risen in proportion to progress in the field. While there are tremendous benefits to society, many argue that there are just as many, if not more, concerns related to advanced forms of artificial intelligence. Accordingly, research into methods to develop artificial intelligence safely is increasingly important. In this paper, we provide an overview of one such safety paradigm: containment with a critical lens aimed toward generative adversarial networks and potentially malicious artificial intelligence. Additionally, we illuminate the potential for a developmental blindspot in the stovepiping of containment mechanisms.
A Cyber Science Based Ontology for Artificial General Intelligence Containment
Jan 28, 2018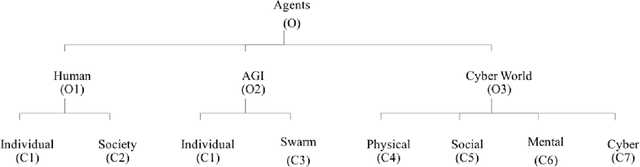

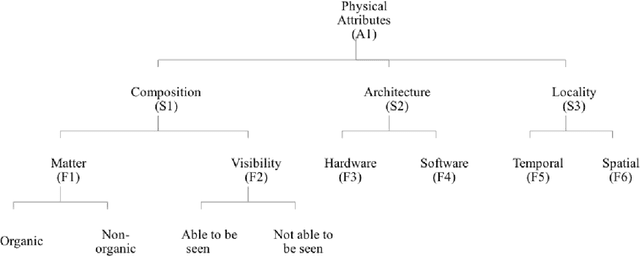

The development of artificial general intelligence is considered by many to be inevitable. What such intelligence does after becoming aware is not so certain. To that end, research suggests that the likelihood of artificial general intelligence becoming hostile to humans is significant enough to warrant inquiry into methods to limit such potential. Thus, containment of artificial general intelligence is a timely and meaningful research topic. While there is limited research exploring possible containment strategies, such work is bounded by the underlying field the strategies draw upon. Accordingly, we set out to construct an ontology to describe necessary elements in any future containment technology. Using existing academic literature, we developed a single domain ontology containing five levels, 32 codes, and 32 associated descriptors. Further, we constructed ontology diagrams to demonstrate intended relationships. We then identified humans, AGI, and the cyber world as novel agent objects necessary for future containment activities. Collectively, the work addresses three critical gaps: (a) identifying and arranging fundamental constructs; (b) situating AGI containment within cyber science; and (c) developing scientific rigor within the field.