 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MVTec AD 2 Dataset: Advanced Scenarios for Unsupervised Anomaly Detection
Mar 27, 2025In recent years, performance on existing anomaly detection benchmarks like MVTec AD and VisA has started to saturate in terms of segmentation AU-PRO, with state-of-the-art models often competing in the range of less than one percentage point. This lack of discriminatory power prevents a meaningful comparison of models and thus hinders progress of the field, especially when considering the inherent stochastic nature of machine learning results. We present MVTec AD 2, a collection of eight anomaly detection scenarios with more than 8000 high-resolution images. It comprises challenging and highly relevant industrial inspection use cases that have not been considered in previous datasets, including transparent and overlapping objects, dark-field and back light illumination, objects with high variance in the normal data, and extremely small defects. We provide comprehensive evaluations of state-of-the-art methods and show that their performance remains below 60% average AU-PRO. Additionally, our dataset provides test scenarios with lighting condition changes to assess the robustness of methods under real-world distribution shifts. We host a publicly accessible evaluation server that holds the pixel-precise ground truth of the test set (https://benchmark.mvtec.com/). All image data is available at https://www.mvtec.com/company/research/datasets/mvtec-ad-2.
Shift Variance in Scene Text Detection
Aug 19, 2022


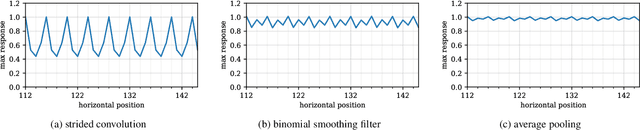
Theory of convolutional neural networks suggests the property of shift equivariance, i.e., that a shifted input causes an equally shifted output. In practice, however, this is not always the case. This poses a great problem for scene text detection for which a consistent spatial response is crucial, irrespective of the position of the text in the scene. Using a simple synthetic experiment, we demonstrate the inherent shift variance of a state-of-the-art fully convolutional text detector. Furthermore, using the same experimental setting, we show how small architectural changes can lead to an improved shift equivariance and less variation of the detector output. We validate the synthetic results using a real-world training schedule on the text detection network. To quantify the amount of shift variability, we propose a metric based on well-established text detection benchmarks. While the proposed architectural changes are not able to fully recover shift equivariance, adding smoothing filters can substantially improve shift consistency on common text datasets. Considering the potentially large impact of small shifts, we propose to extend the commonly used text detection metrics by the metric described in this work, in order to be able to quantify the consistency of text detectors.